
 标签: 实战
标签: 实战
相关帖子


相关博文
-
要使用YOLOv8进行路面坑洞检测,可以按照以下步骤进行: 1. 准备数据集:收集包含路面坑洞的图片,并为每个图片标注出坑洞的位置。可以使用LabelImg等工具进行标注。 2. 安装依赖库:确保已经安装了Python、OpenCV、NumPy等库。 3. 下载YOLOv8模型:从YOLO官网或GitHub仓库下载预训练的YOLOv8模型。 4. 修改配置文件:根据实际需求修改YOLOv8的配置文件,例如类别数量、锚点尺寸等。 5. 训练模型:使用准备好的数据集和配置文件训练YOLOv8模型。 6. 测试模型:使用测试集评估模型的性能。 7. 应用模型:将训练好的模型应用于实际路面图像,检测坑洞。 以下是一个简单的代码示例: ```python import cv2 import numpy as np from yolov8 import YOLOv8 # 加载预训练的YOLOv8模型 yolo = YOLOv8("yolov8.weights", "yolov8.cfg") # 读取路面图像 image = cv2.imread("road_image.jpg") # 使用YOLOv8进行目标检测 detections = yolo.detect(image) # 在图像上绘制检测结果 for detection in detections: x, y, w, h = detection cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2) # 显示结果 cv2.imshow("Result", image) cv2.waitKey(0) cv2.destroyAllWindows() ``` 注意:这里的代码仅作为示例,实际应用时需要根据具体情况进行调整。
-
谢谢刘波。谢谢面包板论坛。谢谢机械工业出版社。非常感谢给的这一次试读机会,机械工业出版社! 接上三篇: 《Proteus实战攻略》+单片机仿真1开箱 《Proteus实战攻略》+单片机仿真2至诚经典第八章 《Proteus实战攻略》+单片机仿真3基础电路第一章 《Proteus实战攻略》+单片机仿真4第二章 在阅读了“PIC系列单片机仿真实例”这章后,我深感PIC单片机的魅力及其在电路仿真中的应用。通过这些实例,我不仅学习到了PIC单片机的相关知识,还对电路仿真有了更深入的理解。下面是我对这篇文章的一些心得体会。 首先,这个例子让我重新认识了PIC单片机。让我看到了PIC单片机的实际应用和它所具备的强大功能。通过为PIC单片机配置相应的硬件和软件,我们可以实现从键盘输入数值,到对输入的数值进行加减乘除等基本运算,最后将结果显示在LCD显示屏上。这一切都让我深刻体验到了单片机的实用性。无论是在嵌入式系统还是在自动化设备中,PIC单片机都发挥着举足轻重的作用。通过这些实例,我明白了一些硬件知识,例如LCD显示屏电路等。这些都为我在今后的学习和工作中奠定了基础。 在所有的实例中,我特别被“简易计算器电路仿真”这个实例所吸引。这个实例不仅涵盖了PIC单片机的基础知识,还进一步展示了其强大的数据处理和运算能力。通过这个实例,我复习了如何利用PIC单片机进行简单的数值运算和四则运算,这让我对单片机的功能和应用有了更深的认识。这个例子也让我体会到了理论与实践相结合的重要性。在硬件电路设计过程中,我了解到如何根据实际需求选择合适的电子元件和设备,如何配置电路以满足计算器的功能需求。这让我明白了理论知识只有在实践中才能真正得到理解和巩固。 在硬件电路设计方面,我了解到绘制电路图的重要性以及如何将电路图转化为实际的硬件电路。通过这些实例,我学会了如何使用专业的EDA工具,如Altium Designer,进行电路设计和仿真。这些技能对于我在今后的学习和工作中的电路设计具有重要的指导意义。 此外,我也认识到编程语言如C语言在PIC单片机上的应用。通过这个实例,我复习了如何使用C语言编写程序,使得PIC单片机能够实现各种运算功能。这让我深刻体会到编程语言在嵌入式系统中的重要性。我想说的是,这个例子虽然只是一个简单的计算器电路设计,但它所蕴含的原理和技巧对于我未来的学习和工作将具有深远的指导意义。我将继续努力,将所学的知识和技能运用到实际中,为电子技术的发展做出贡献。 总的来说,通过这些PIC系列单片机仿真实例,我对PIC单片机的使用有了更深入的了解。这些知识不仅有助于我在今后的学习和工作中更好地应用PIC单片机,同时也提高了我的实践能力和解决问题的能力。在此过程中,我也认识到自己的不足之处,这是我今后需要进一步学习和提高的地方。我不仅掌握了PIC单片机的应用和电路设计的基本步骤,更重要的是,我从中领悟到了理论与实践相结合的重要性,以及不断探索和创新的精神对于我们学习和工作的价值。这是我在这个例子中最大的收获,也是我今后学习和实践的指导思想。 最后,我想说的是,这些实例只是开始。在今后的学习和工作中,我将继续探索和研究PIC单片机的更多功能和应用,不断提高自己的技能和能力。我相信,只有不断地学习和实践,才能更好地理解和应用PIC单片机,为我们的生活和工作环境带来更多的便利和进步。 谢谢!
-
谢谢刘波。谢谢面包板论坛。谢谢机械工业出版社。非常感谢给的这一次试读机会,机械工业出版社! 接上三篇: 《Proteus实战攻略》+单片机仿真1开箱 《Proteus实战攻略》+单片机仿真2至诚经典第八章 《Proteus实战攻略》+单片机仿真3基础电路第一章 本章主要表达了作者通过51系列单片机的仿真和实践,对单片机的工作原理和应用有了更深入的理解,尤其是在直流电动机调速电路的仿真设计中,作者学会了如何用单片机来控制电动机,并深刻体会到了单片机在嵌入式系统中的重要地位。 在文章中,作者详细描述了在直流电动机调速电路的仿真过程中的新知识,例如对晶振电路有了更深入的理解,如何设置和调整晶振的频率,以及通过绘制和调整电阻、电容等电子元件,温故了电子技术的基础知识。这些知识的获得和巩固,使得对嵌入式系统有了更深刻的认识。 此外,作者还分享了自己在这个过程中最大的收获是了解了单片机在实际工程中的应用,并学会了如何用单片机去控制一个系统。这对嵌入式系统有了更深刻的认识,并且更加期待后续的学习和实践。 最后,作者提到了在未来的学习和工作中,将更加注重实践操作,多进行实际项目的开发和调试,并阅读和学习相关的技术文献和资料,以扩大自己的知识面和提升自己的技能水平。同时,作者也希望能在今后的学习和实践中,更好地培养自己的创新意识和团队协作精神,以便更好地适应社会的需求和发展。 总的来说,这段文字表达了作者对51系列单片机仿真的实践感受和收获,以及对未来期望和计划。 通过直流电动机调速电路的仿真设计,我不仅学会了如何用单片机来控制电动机,也深刻体会到了单片机在嵌入式系统中的重要地位。在直流电动机调速电路的仿真过程中,我了解到通过51单片机控制H桥驱动电路,可以对直流电动机的转速和转向进行精确控制。这让我对单片机的I/O端口有了更深的认识,它们可以作为输入或输出信号,控制外部硬件的工作状态。此外,通过独立按键来调节转速和转向,让我感受到了单片机的实时性和灵活性。 总之,通过这次51系列单片机仿真的学习与实践,我不仅提高了自己的专业素养,还锻炼了自己的实践能力和创新思维。我相信,这次的学习与实践将对我未来的学习和工作产生深远的影响。同时,我也期待着在未来的学习和实践中,能继续发挥自己的专业特长和创新能力,为嵌入式系统的发展做出自己的贡献。 谢谢!
-
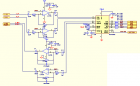
1路视频光端机硬件原理详细设计 记录编号: X XXXXX 一、 项目编号: X XXXX 二、 项目名称: 1路视频光端机(国办方案) 三、 版本: X XXXXXX 四、 用模块图表示设计原理 整对 PCB采用2片 EPM3128A 数据复用芯片 1 片国办的 DS92LV1212A / DS92LV1 021 A 芯片 , 1片AD9708 和AD9280 A/D转换芯片 1片MAX488 MAX3232 PCM3008T 芯片 ,组成一对1路视频 1路双向音频 1路双向数据(RS485/422 RS232 ) 的收发数字视频光端机。 整个主板主要分七大部分:电源电路部分、视频模拟电路放大滤波部分、模拟 /数字转换部分、cpld数字信号复用和时钟处理部分、G-LINK 高速串行编解码部分、光模块电路部分、音频数据部分。 五、 各部分原理说明 I 、电源电路 由电源插座引入 220V交流电源,经一块YAS-5.0 AC/DC开关电源模块 产生 +5V/2.4A直流电源供应布在PCB板上的OP691 OP690 LM353 MAX488 芯片设备。 独立的 AD芯片, EPM3128A 数据复用芯片 , DS92LV1 021 A serializer芯片 的电源电路采用AS1117芯片稳压电路构成,产生系统的+3.3V的电源。 1、 AS1117() ① 、供应 AD9280/9708芯片74LC14芯片, EPM3128A 数据复用芯片 ,其电源网络标号是 “+ 3.3 V”。 ② 、供应音频处理芯片 PCM3008T的数字PIN5,其电源网络标号是 “+3.3AU”。 ③ 、供应 RS3232芯片VCC接口,其电源网络标号是 “”。 ④、供应 DS92LV1 021 A serializer芯片,其电源网络标号是 “+3.3LVA” “+3.3LVD” 2 RS3232 芯片PIN3提供 -5V 电压给OPA690 ,其电源网络标号是 “ – 5A ”和 提供给OPA691 ,其电源网络标号为 “ – 5B ”。 3 +5V/2.4A直流电源 供应光收发模块的TTL 电路电源网络标号为“+5V ” . ① 、供应 电压放大器 OPA690 ,其电源网络标号“+5A ” . ② 、供应电流放大器 OPA691 , 其电源网络标号“+5B ” 。 ③ 、供应 MAX488芯片 ,其电源网络标号 “ +5DA ” . ④、供应LM358 芯片,其电源网络标号 “ +5AU ” . 在电源的总输出处加入 L24(22UH/2A)的滤波电感以提高电源的信噪比。 II、 CPLD 芯片 电路部分 该电路采用 EPM3128A数字复用 芯片 。 主要特性如下: · 芯片实现数据并行复用 · QFP1 00 封装, 3.3V 供电。 Ⅲ、 Video 视频部分 本设备视频发射和接收部分主要采用了国办的 OPA690 电压反馈放大芯片,OPA691电流反馈放大 芯片、 LM1881 视频同步分离芯片、LC三阶低通滤波电路、AD9280/9708 模数转换芯片搭建而成。 TX 发射端的视频信号输入先经过 OPA691 电流反馈放大电路部分在传输到三阶8mhz低通滤波电路 传到 AD9280 的ADC 处理传给CPLD的复用 ,再把视频信号传给LVDS 芯片变成高速串行信号输出到 TTL电平的光模块电路转成光信号传到远端接收部分。 RX ⑴ 、 LM1881 视频同步分离器芯片电路 LM1881 行场同步分离模块 ( 视频同步信号提取电路 ) 芯片性能: 1、定时提取视频的同步信息,包括复合同步视频信号和垂直信号、脉冲时沿,在这里应用是分离出复合同步信号给 D7,信号在经过三极管Q1得放大电路 把信号传给CPLD处理、和 通过同步信号分离模块将外输入的视频信号中的行场同步信号分离出来,该分离信号引入 AD9280 。 2、LM1881 的第8脚VCC 5V电压输入,C13 0.1uf C106 0.01uf电容起去耦 提供低阻抗通路 作用。 C14 0.1uf 起耦合作用 C105 470pf电容起滤波作用。 Lm1881 硬件框图 ⑵ 、 OPA691 电流反馈放大芯片 OPA690 电压反馈放大芯片电路 OPA691 将宽带的电流反馈型运算放大器提高到一个崭新的水平。一般情况下工作在 5.1mA 的极低 供电电流,当在更高的供电电流下工作时 ,OPA691可满足高的压摆率 (2100V/us) 及输出功率 (190mA),是多路广播视频接口应用的选择。 OPA690 具有稳定的单位增益、带禁用端的电压反馈型运算放大器,它可提供先前只在宽带电流反馈放大器中才具有的压摆率及满功率带宽。OPA690 采用 +5V 单电源,在超过 150mA的 驱动电流和150MHz 带宽的条件下,提供 1V至4V 的输出动态范围,奠定了其在 RGB 线驱动以及单电源 ADC 输入驱动器中的性能。双路的 OPA2690 可支持高压摆率的差分输入输出,单个三路 的OPA3690 更能实现有源高阶滤波。 特性 · 宽电源范围: 5V 到 12V 的单电源、+/-2.5 到 +/-6V的双电源 · 高输出电流: +/-190mA(+/-250mA限流) · 高压摆率: 2100V/us (OPA691) · 输出电压范围: +/- 5 V TX: OPA691 电流反馈放大电路部分 RX:OPA691 电流反馈放大电路部分- RX:OPA690 电压反馈放大器电路部分 ⑶ 视频 A/D 模拟数字转换部分电路。 AD9280 ADC : ① CMOS 8 bit 编码 32MSPS 采样 ; 可实现数据的多通道传输低电压高速采样 ② 高性能低电压 ,在3V 电压工作模式下功耗为:95mw (3v ),在休眠工作模式下功耗仅为5mw; ③ 可调的芯片参考电压 ; ④ 多种模式选择 见图如下 : TX:AD9280 模转数电路部分 参考电压工作模式设置 :在1V模式下是内部参考电压把REFSENSE 和VREF 连接;在2V模式是把REFSENSE 接地;外部驱动模式是在1V 2V模式增加电阻;外部参考模式是使能给REFTS REFBS VREF pin 信号输入采用 Differential 模式AIN 驱动一个信号输入,REFTS OR REFBS 连接驱动另一个输入,此模式PIN 要打到AVDD/2 才能达到最佳模式. INPUT 输入和参考电压部分的关系是 (REFTS-VREF/2) ≤ AIN ≤ (REFTS+VREF/2) ,是由VREF 输出参考来决定AIN 的范围在顶层参考和底层参考的范围之间比值为1V :2V . 电路在芯片的 REFTF 和 REFBF 搭建了去藕网络-短路两个PIN 并联上10uf和0.1分电容及串上两个0.1uf对接地电容,芯片参考电压VREF PIN 要旁路给AVSS (analog ground) 1.0uf 电容和并上0.1uf电容. AD9280 可以DIFFERENTIAL 输入信号,可以短路REFTS 和REFBS pins 驱动differential 信号,在这种配置下,AD9280 可以接受1V P-P 的信号. AD芯片5-12 pin 是输出8位的并行数据到CPLD 复用芯片.时钟信号的CLK输出到cpld . RX:AD9708 数转模电路部分 AD9708 DAC : ① 高性能低电压数子到模拟转换器 ,在3V 电压工作模式下功耗为:45mw (3v );在5V 的工作电压下功耗为175MW ,在休眠工作模式下功耗仅为20mw @ 5V; ② 模拟和数字部分的电压为图中 AVDD DVDD,支持电压范围再2.7v-5. 5v , 数字部分可以运行在 125MSPS 的时钟速率下 ③ 输出电流在 2MA -- 20ma .外围电阻结合内部参考放大器 参考电压 V REF 来调整 I REF ④ 芯片的每个针脚( pin)的定义见下表: ⑤ 芯片要求输出阻抗大于 100K欧 ,所以电路图中可见芯片的IOUTA IOUTB 输出PIN 的外接电路的加上了51欧的下拉电阻R63 R64及22pf 的C116 C117滤波及采用510欧的R56 R57 电阻对输出信号达到要求的阻抗。 ⑥ 电路中芯片的 FSADJ PIN 要求外接2K欧对地的R67 电阻,用来控制数字信号的输出电流. ⑦ 芯片分模拟和数字两部分,在接地和供电方面也要求,接地 ACOM DCOM 和供电AVDD DVDD 要分开,不能通用。 ⑧ 电路中芯片的 REFLO 参考地和ACOM 模拟地连接,才能REFIO 参考输出电压要达到1.2V ,这样需要REFIO外接补偿 0.1uf 电容。 ⑷ 三阶低通滤波电路部分 。 视频信号经过 OPA691放大后进入8MHZ 的三阶低通滤波电路,对信号的优化后传到AD9280转换芯片进行AD转换处理. Ⅳ LVDS 国办芯片部分 本设备串并数据转换部分采用国办的 DS92LV1021A 和DS92LV1212A 芯片 ,把并行数据转换成高速的串行数据最后传给TTL电平的光模块转称光信号传给远端的设备,在由接收端DS92LV1212A芯片解出串行信号恢复出同步的并行信号。两边采用的同步时钟为16.384MHZ. ⑴ TX :DS921021A 电路部分 ⑵ R X :DS921212A 电路部分 Ⅴ、 AUDIO 部分 本设备得音频部分是采用 PCM3008T 芯片搭建的双向立体声的电路通道。PCM3008T 芯片是低成本数字立体声音频处理芯片,16bit 的ADC 和 DAC ,8khz-48khz 采样、 Ⅵ RS488/422 RS232数据部分 Ⅶ 时钟晶振电路部分 设备时钟采用 Ⅷ 指示灯部分 Ⅸ 光模块 光模块采用的是普通的 1×9针光模块,采用+5V供电, 发射是1.25G PECL电平和155M TTL电平的双向光模块,主芯片工作电压为+3.3V,因此使用交流耦合。 光接收检测信号 ,此信号分两路,送LVDS1021/1212A 光口信号检测输入。经LVDS1021A组成的并转串电路转换成串行光信号送入发送至对端设备。
-
自己不懂,那就是“理论”? 程晓华 2014-2-26 某天跟一个做供应链培训的朋友喝茶,他一直在抱怨,说他讲课的时候,经常被客户挑战,客户总认为他讲的都是“不切实际的理论”,搞得他都没有信心再做这一行了。 我问他,那您自己认为呢? 他说,程老师,我也是从工厂里做供应链出身的,尽管没有您资深,但我毕竟也是有一定的实战经验啊! 我说我可知道您可是啥课都敢讲啊? 他说是啊,我讲的是比较杂,但我善于学习啊,我几乎两三天就能看完一本书,包括您的书,有很多都是“实战”性质的嘛。 我说,也对,也不对。 “对”的地方在哪里呢? 第一:所有的管理理论,尤其是供应链管理理论,几乎都是来自于实践; 第二:作为一个讲师或者咨询师,不可能什么行业、什么产品都做过; 第三:行业、产品之间有其特殊性,但基本逻辑、做法则是大同小异; 第四:客户之所以请你去讲课,他们可能的确不懂这些“理论”或者逻辑; 第五:或许客户明白这些“理论”,但他不明白怎么去用,所以请你去解惑; 第六:通常情况下,人们总是把自己不懂而别人明白的东西统称为“理论”。 他不断地点头称赞。 但“不对”的地方在哪里呢? 我说: 第一:你讲的所谓的理论是不是经过自己的实践总结出来的?也就是你自己的亲身体会? 第二:如果不是,你能否对你所讲的东西自圆其说、自成体系? 第三:如果连自圆其说都不能,那你其实是否是连你自己都不是真懂这个“理论”或者逻辑,而是人云亦云,照猫画虎,照搬照抄? 他不断地摇头,总共三次。 作者程晓华( John Cheng),《制造业库存控制技巧》、《CMO首席物料官》著作者;“TIM全面库存管理”体系创始人、咨询师,“制造业库存控制技术与策略”课程创始人、讲师;15年制造业工作经验,5年咨询业经历。 WEB:www.timvalue.net 个人QQ: 1970985562 中国创新智造联盟QQ群: 221921205
相关资源
-
一、ChatGLM定义ChatGLM是由清华技术成果转化的公司智谱AI发布的开源的、支持中英双语问答的对话语言模型系列,并针对中文进行了优化,该模型基于GeneralLanguageModel(GLM)架构构建,ChatGLM是一款基于人工智能技术的智能聊天机器人,它具备强大的自然语言处理能力,能够理解和回答我们的问题,通过与ChatGLM的对话,我们可以轻松获取各种信息,解决生活中的疑惑,甚至寻求专业建议,ChatGLM的出现,让我们在获取信息、解决问题上更加高效便捷。二、发展历程早期对话系统:最初的对话系统基于规则和模板,能够回答特定的问题或执行简单的任务。统计模型:随后,统计机器学习方法被用于对话系统,使得模型能够处理更多样化的输入。神经网络:深度学习的兴起带来了基于神经网络的对话系统,这些系统能够生成更自然的回答。预训练语言模型:BERT、GPT等预训练语言模型的出现极大地提升了对话系统的性能。专门化的聊天模型:随着技术的进步,出现了专门为聊天设计的模型,如Meena、DialoGPT、ChatGLM等。三、ChatGLM3-6B模型私有化部署ChatGLM-6B是一个开源的、支持中英双语的对话语言模型,基于GeneralLanguageModel(GLM)架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGPT相似的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。四、AI数字人技术开发的几个关键趋势和进展:B端市场扩大:数字人的制造和运营服务市场正不断扩大,从传统的电影动画领域向广告营销、电商直播、虚拟偶像等多个领域扩展。未来,数字人有望为更广泛的C端用户提供服务。技术迭代:技术的不断迭代推动了数字人在外形上更接近真人,制作效能得到提升。这包括建模技术、物理仿真算法、渲染引擎和GPU算力的提升,以及动捕技术的优化。AI赋能:AI技术是数字人发展的重要推动力,它使得数字人能够进行多模态交互,更神似人。AI技术的应用不仅限于交互,还覆盖了数字人的全流程,包括视频生成、建模、动作捕捉等。融合发展:数字人技术与SLAM、3D交互、体积视频、空间音频等技术的深度融合,预示着渲染技术将从本地转移到云端,为数字人提供更强大的支持。行业应用:数字人将成为人机交互的新入口,应用场景广泛,从简单的信息服务到复杂的情感交流,数字人都能提供更好的用户体验。UGC模式:随着技术门槛和成本的降低,用户生成内容(UGC)的数字人将加速出现,成为产业的增量空间。显示设备:虽然数字人主要以2D显示设备为主,但3D显示设备如AR/VR眼镜等,将在特定领域提供新的解决方案。在场感:数字人发展的高级阶段将与应用场景深度耦合,提供更真实的沉浸感和更大的价值。艺术与技术双轮驱动:北京等地区有望成为数字人产业的新高地,艺术和技术的结合将推动数字人产业的发展。合规性:随着数字人产业的发展,版权保护和行业合规体系的建设也变得尤为重要,以确保数字人的可用性、可靠性、可知性和可控性。五、数字人技术开发的关键组成部分通常包括:人物建模:使用3D建模软件创建数字人的外形,包括面部特征、身体结构等。动作捕捉:通过捕捉真人的动作数据,将其映射到数字人模型上,使其能够做出逼真的动作。语音合成:将文本转换为口语,使用TTS技术让数字人能够“说话”。面部表情生成:利用AI算法生成逼真的面部表情和嘴型,以匹配其语音输出。动画生成:通过编程或AI算法生成数字人的动作和姿态变化。交互能力:集成NLP技术,使数字人能够理解用户的输入并做出适当的反应。个性化:允许用户根据个人喜好定制数字人的外观和行为。实时渲染:使用游戏引擎或其他实时渲染技术,使数字人能够在视频或直播中实时显示。云计算和边缘计算:提供必要的计算资源,支持数字人的高度复杂计算需求。API和SDK:为开发者提供工具和接口,以便他们可以创建自己的数字人应用。六、虚拟数字人的基本组成一个完整的AI虚拟数字人通常包括以下几个部分:视觉模型:3D模型或2D动画,用于展示虚拟人的外观。语音合成:将文本转换为语音,使虚拟人能够发声。自然语言处理(NLP):理解用户输入并生成相应的回应。动作驱动:根据语音和情绪驱动虚拟人的面部表情和肢体动作。七、语音合成与识别使用第三方API进行语音合成可以使用诸如GoogleText-to-Speech、AmazonPolly或微软AzureTTS等成熟的语音合成API。以下是一个使用Python调用GoogleTTS的示例:importopenaiopenai.api_key='your_api_key'defchat_with_gpt(prompt): response=openai.Completion.create( engine="davinci", prompt=prompt, max_tokens=150 ) returnresponse.choices[0].text.strip()user_input="你好,你是谁?"response=chat_with_gpt(user_input)print("AI:",response)

-
一、Llama3大模型是什么?Llama是由Meta的人工智能研究团队开发并开源的大型语言模型(LLM),继Llama2+模型之后,Meta进一步推出了性能更卓越的MetaLlama3系列语言模型,包括一个80亿参数模型和一个700亿参数模型。Llama370B的性能美Gemini1.5Pro,全面超越Claude大杯,而400B+的模型则有望与Claude超大杯和新版GPT-4Turbo掰手腕二、llama2和llama3有什么区别?llama3与llama2的模型架构完全相同,只是model的一些配置(主要是维度)有些不同,llama2推理的工程基本可以无缝支持llama3。在meta官方的代码库,模型计算部分的代码是一模一样的,也就是主干decoderonly,用到了RoPE、SwiGLU、GQA等具体技术。通过对比huggingface模型中的config.json,首先可以看出,模型都是LlamaForCausalLM这个类,模型结构不变。三、Llama3的目标和最佳表现Llama3拥抱开源社区。通过不断响应用户反馈来提升模型效果,并且持续在负责任的AI领域扮演重要角色。近期发布的基于文本的模型是Llama3集合的一部分。未来的目标是使Llama3成为多语言、多模态、长上下文、持续提升核心能力,如:推理和代码生成。得益于pretraining和post-training的改进,我们的pretrained模型和instruction-fine-tuned模型是8B和70B最好的大模型。post-training的改进包括:降低误拒率、改进的对齐方法、模型回答的多样性。同时,我们也看到Llama3综合能力的提升,如:推理、代码生成、指令遵循。这使得Llama3更加可控。四、从头构建LLaMA3大模型(Python)首先是模型架构的选择。原工作用的是GPTNeo架构(可以看他们的config),这个算是很老的模型了,最初是EleutherAI用来复现追踪GPT-3的工作的,现在用的也比较少了。我打算选用LLaMA架构,也算是符合研究主流、便于推广。LLaMA3主要多了个GQA,也是现在模型的主流,我这里也用一下。其次是数据的选择。既然是复现,就直接贯彻拿来主义,用原工作开源的数据集(主要是从头生成要花不少api费用)。原工作第一版的时候用的是GPT-3.5生成的数据,后面社区有人更新了第二版,是用GPT-4生成的,比原数据更好,就用它了。最后是训练。其实我手上就两张306012G和4060Ti16G,训这个确实是绰绰有余,但我还是不想在桌前吵我自己,于是继续用Colab。现在Colab可以直接看到剩余使用时长了,虽然已经被砍到只有3h左右的用卡时间,但至少心里有个底,况且3h训我们这个也完全够了。五、用户与LlaMA3进行交互的方式主要分为6个阶段。阶段1:通过按原样使用模型,以适应广泛的应用场景。第2阶段:在用户自定义的应用程序中使用模型。第3阶段:使用提示工程来训练模型,以产生所需的输出。第4阶段:在用户端使用提示工程,同时深入研究数据检索和微调,这仍然主要由LLM提供商管理。第5阶段:把大部分事情掌握在自己(用户)手中,从提示工程到数据检索和微调(RAG模型、PEFT模型等)等诸多任务。第6阶段:从头开始创建整个基础模型——从训练前到训练后。为了最大限度地利用这些模型,建议最好的方法是使用上面的第5阶段,因为灵活性很大程度上取决于用户自身。能够根据领域需求定制模型对于最大限度地提高其收益至关重要。因此,如果不参与到系统开发中,是不能产生最佳回报的。
-
一、Vulkan简介Vulkan是一个低开销、跨平台的二维、三维图形与计算的应用程序接口(API),最早由科纳斯组织在2015年游戏开发者大会(GDC)上发表。与OpenGL类似,Vulkan针对全平台即时3D图形程序(如电子游戏和交互媒体)而设计,并提供高性能与更均衡的CPU与GPU占用,这也是Direct3D12和AMD的Mantle的目标。与Direct3D(12版之前)和OpenGL的其他主要区别是,Vulkan是一个底层API,而且能执行并行任务。除此之外,Vulkan还能更好地分配多个CPU核心的使用。相比于传统的OpenGL,VulkanAPI的设计更加贴近硬件。传统API比如OpenGL内部维护一个单一全局的状态机,这就意味着需要通过一个主线程来处理所有的绘图命令,即便驱动内部能够保证渲染足够高校,但是由于外部提交指令的方式是单线程的容易导致多核CPU的利用率不高。而Vulkan从设计上就考虑了多线程编程,允许开发者在多个线程中并行执行绘图命令和资源管理操作。这样可以大幅提升渲染性能,并使应用程序更具响应性。二、Vulkan在图形渲染中的优势1、低开销和高性能:Vulkan通过减少驱动程序的开销和提供更直接的硬件访问,显著提升了图形渲染的效率。这使得Vulkan在处理复杂场景和高分辨率图像时表现尤为出色。2、多线程支持:Vulkan的设计允许开发者充分利用多核处理器的优势,通过并行处理来提升渲染性能。这对于现代多核CPU来说是一个巨大的优势,可以显著提高帧率和降低延迟。3、跨平台兼容性:Vulkan支持多种操作系统和硬件平台,包括Windows、Linux、Android等。这使得开发者可以编写一次代码,然后在多个平台上运行,极大地提高了开发效率。4、灵活的内存管理:Vulkan提供了更灵活的内存管理机制,允许开发者更精细地控制内存分配和使用。这对于需要高效利用内存资源的应用来说是一个重要的优势。三、Vulkan及其演化史目前主流的图形渲染API有OpenGL、OpenGLES、DirectX、Metal等OpenGL的应用领域较为广泛,支持多种操作系统平台(如Windows、UNIX、Linux、macOS等)基于其开发的应用可以方便、低成本地在不同操作系统平台之间移植。既可以用于开发游戏,又可以用于开发工业、行业应用OpenGL-ES则是OpenGL针对移动端的裁剪版本。Direct-X是微软针对Win系统下图形渲染的技术,Metal则是针对Mac/iOS系统下图形渲染技术,从占有率而言DirectX是远远超过Metal的。那么OpenGL在和Vulkan相比,Vulkan能够更好的调动GPU的性能,OpenGL在使用GPU前需要CPU处理很多数据,而Vulkan能够提供更小的运行开销、更直接的GPU控制、和更低的CPU负载。Vulkan的原始概念是由AMD基于他们的私有的MantleAPI设计和实现的,这个API几款不同的API中体现了自己的先进特性四、Vulkan将设备队列按照队列组的方式进行组织,规则如下一个队列组可以支持一个或者多个功能一个队列组中包含一个或者多个队列同一个队列组中的所有队列支持相同的功能队列族之间可以有相同的功能,但两两队列之间不能有两个功能集获取QueueFamily和QueueFamilyPropertytypedefstructVkQueueFamilyProperties{ VkQueueFlags queueFlags; uint32_t queueCount; uint32_t timestampValidBits; VkExtent3D minImageTransferGranularity;}VkQueueFamilyPropertie五、显式的GPU控制在OpenGL驱动中,驱动会帮你做API验证,内存管理,线程管理等大部分工作。OpenGL驱动大包大揽什么事情都管,即使应用使用API出错,也会帮忙解决处理,保证应用正常运行。开发者使用起来非常简单。但是OpenGL为了这些事情,牺牲了大量的性能。在一些复杂的应用场景,依然会遇到无法解决的问题,很多时候经常是驱动的一厢情愿,应用并不为此买单。Vulkan则不然。Vulkan把API验证、内存管理、多线程管理等工作交由开发者负责。一旦API使用出错,应用就会出现crash。没人帮应用兜底,所有事情都交由应用打理。这种方式无疑增加了API使用的复杂度和困难度,但换来的是性能上巨大的提升。单单是在驱动中去掉API验证操作,就把性能提升了9倍。六、图形API的选择建议Vulkan被设计用于在现代多核CPU和GPU上实现更好的并行处理,同时还有更少的CPU开销和更好的可扩展性。此外,Vulkan还提供了更好的调试工具和更好的错误处理机制,这使得它更容易开发和调试。OpenGL仍然是一个非常流行的图形API接口,它已经存在了很长时间并且被广泛使用。它是一个跨平台的API,可以在多种操作系统和硬件上运行。OpenGL的主要优势是它的广泛支持和成熟的生态系统,同时也有很多开发者和工具支持。然而,OpenGL的主要缺点是它的性能受到限制,因为它是一个高级API,对硬件的控制较少,而且它的执行方式也不是非常高效。总之,Vulkan和OpenGL都有各自的优缺点,它们在不同的场景下都有自己的用武之地。
-
随着人工智能的不断发展,AI绘画技术也逐渐得到了广泛的应用和推广,很多人不知道如何进行AI绘画,其实非常AI绘画是非常简单的。今天就给大家分享一些AI绘画相关的功能,包括AI绘画tag生成器和简单好用的AI绘画工具,两者组合使用就能生成一些精致的图片,对于AI绘画小白也非常友好!一、AI绘画的历史AI绘画的出现时间可能比很多人想象的要早.计算机是上世纪60年代出现的,而就在70年代,一位艺术家,哈罗德·科恩HaroldCohen(画家,加利福尼亚大学圣地亚哥分校的教授)就开始打造电脑程序"AARON"进行绘画创作.只是和当下AI绘画输出数字作品有所不同,AARON是真的去控制一个机械臂来作画的.Harold对AARON的改进一直持续了几十年,直到他离世.在80年代的时候,ARRON"掌握"了三维物体的绘制;90年代时,AARON能够使用多种颜色进行绘画,据称直到今天,ARRON仍然在创作.不过,AARON的代码没有开源,所以其作画的细节无从知晓,但可以猜测,ARRON只是以一种复杂的编程方式描述了作者Harold本人对绘画的理解--这也是为什么ARRON经过几十年的学习迭代,最后仍然只能产生色彩艳丽的抽象派风格画作,这正是HaroldCohen本人的抽象色彩绘画风格.Harold用了几十年时间,把自己对艺术的理解和表现方式通过程序指导机械臂呈现在了画布上.二、AI绘画能取代绘画师吗?我认为AI绘图工具可以辅助设计师进行图像制作,但不可能完全取代设计师的角色。以下是我对这个问题的一些看法:技术的局限性:目前的AI绘图工具虽然可以完成一些简单的图像制作,但是在处理复杂的设计任务和艺术创作方面仍然存在局限。设计师可以通过自己的专业知识和创意来解决这些问题,而AI绘图工具则需要更多的技术研究和进步才能够实现。设计师的创造力:设计师不仅需要具备绘画技能,还需要具备独特的创造力和审美眼光。这些都是AI绘图工具无法取代的,因为它们是人类独有的思维和能力。人性化的设计:设计师可以更好地理解人类的需求和心理,创作出符合人性化的设计作品。而AI绘图工具则缺乏这种人性化的思考和理解,难以产生具备情感和人性化的设计作品。AI绘图工具可以在一定程度上辅助设计师进行图像制作,但是在创造力、人性化的设计和技术局限性等方面仍然存在一些问题。设计师可以通过不断学习和提升自己的专业能力,与AI绘图工具共同发挥各自的优势,为用户创造更好的设计作品。三、AI绘画工具有哪些你知道吗?1、MidjourneyMidjourney是一个独立的研究实验室开发的人工智能程序,它能够根据文本提示生成图像。优点:易于上手,模型生成质量高,尤其是自然语言理解能力强,界面设计简洁明了,适合初学者,并且是基于Discord社区机器人,使用便捷。缺点:需要梯子、会员付费,生成图片的不稳定性和不可控性。2、StableDiffusionStableDiffusion是一种深度学习模型,主要用于文本到图像的生成。在图像生成领域,StableDiffusion可以通过学习大量图像数据集的分布,从而能够生成新的、逼真的图像。优点:开源免费、可商用、支持多平台部署、生成图片可控度高、插件众多。缺点:本地计算机配置需求高、安装包较大、学习门槛略高于其他AI绘图工具。3、文心一格这也是国内最知名的AI绘画工具之一啦,除了可以进行AI画图的曹邹外,也可以进行各种类型的图片处理操作,可以说非常适合绘画师和设计师的一款工具啦,包括AI抠图、图片拓展和一键消除等功能,都是俺经常会用到的。 4、DeepAI不用注册就能使用?没错,这也是一款完全免费开源的AI绘画、视频、音频和对话工具,个人觉得油画和素描的生成效果也相当不错,基础功能足以满足大部分的图片绘制需求,非常适合国内的朋友哦~5、LiblibAI国内的在线版SD,可以直接在线生成一些高级的图片效果,还有其他的大量模型,随意截了个图,可以发现生成的图片质量都非常高,而且也搭载了ControlNet插件和涂鸦功能,最大限度满足你的制作需求!四、AI绘画前景AI绘画的前景非常广阔,具有巨大的市场潜力和应用价值。AI绘画技术正在迅速发展,已经能够创作出令人惊叹的艺术作品。这些技术使用复杂的算法来分析大量的艺术作品,学习不同的风格和技巧,并在此基础上创造出全新的作品。AI绘画不仅对传统绘画技术是一种补充,也为艺术创作提供了全新的可能性。随着技术的成熟,AI绘画在艺术界掀起了一股新浪潮,预示着一种新兴职业——AI艺术家的可能出现。这些艺术家可能不具备传统的绘画技能,但他们需要具备对透视、光影以及其他美学基础的深刻理解,通过选择合适的作画工具、调整参数和指导创作过程中的美学方向,创作出独特的艺术作品。AI绘画的兴起对艺术世界的影响是双面的:一方面,它打破了艺术创作的传统界限,使得没有绘画背景的人也能创作出优美的艺术作品;另一方面,这也引发了关于“什么是真正的艺术”以及“机器创作的作品能否被视为艺术”的讨论。
-
一、什么是流媒体流媒体是一种以流的形式在网络上进行数字媒体(音频、视频)传输的技术。它将频、音视频之类的连续媒体经压缩编码、数据打包后按照一定的时间间隔要求连续地发送给接收方,接收方在后续数据不断到达的同时对接收到的数据进行重组、解码和播放。如果你对流媒体感兴趣的话,可以看一下Live555,一个更流行且更专业的流媒体库。它支持了各种标准流媒体传输协议,如RTP/RTCP、RTSP、SIP,实现了对多种音视频编码格式的音视频数据的流化、接收和处理等支持。播放VLC和MPlayer都是基于它来实现流媒体播放的功能,并且非常适合嵌入式领域。二、视频编码 是指压缩编码。在计算机的世界中,一切都是0和1组成的,音视频的数据量庞大,如果按照裸流数据存储的话,那将需要耗费非常大的存储空间,也不利于传送。而音视频中,其实包含了大量0和1的重复数据,因此可以通过一定的算法来压缩这些0和1的数据。特别在视频中,由于画面是逐渐过渡的,因此整个视频中,包含了大量画面/像素的重复,这正好提供了非常大的压缩空间。因此,编码可以大大减小音视频数据的大小,让音视频更容易存储和传送。三、simple-rtmp-server[多种类型直播]一个简单高效的实时视频服务器,使用C++开发,支持RTMP/WebRTC/HLS/HTTP-FLV/SRT/GB28181。SRS定位是运营级的互联网直播服务器集群,追求更好的概念完整性和最简单实现的代码。SRS提供了丰富的接入方案将RTMP流接入SRS,包括推送RTMP到SRS、推送RTSP/UDP/FLV到SRS、拉取流到SRS。SRS还支持将接入的RTMP流进行各种变换,譬如将RTMP流转码、流截图、转发给其他服务器、转封装成HTTP-FLV流、转封装成HLS、转封装成HDS、录制成FLV四、音视频处理框架1.OpenCVOpenCV全称是OpenSourceComputerVisionLibrary,是一个跨平台的计算机视觉库,是由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。可用于开发实时的图像处理、计算机视觉以及模式识别程序。OpenCV用C++语言编写,有大量的Python,JavaandMATLAB(版本2.5)的接口。2.GstreamerGStreamer是一个基于管道的多媒体框架,基于GObject,以C语言写成。可以很容易地创建各种多媒体功能组件,包括简单的音频回放,音频和视频播放,录音,流媒体和音频编辑。适用于所有主要操作系统,例如Linux、Android、Windows、MaxOSX、iOS,以及大多数BSD、商业Unix、Solaris和Symbian。GStreamers功能可以通过新插件进行扩展。3.FFmpeg一套开源的音视频处理的框架,可以运行音频和视频多种格式的录影、转换、流功能,包含了libavcodec(用于多个项目中音频和视频的解码器库)以及libavformat(音频与视频格式转换库)五、多媒体处理功能 多媒体视频处理工具FFmpeg有非常强大的功能[1]包括视频采集功能、视频格式转换、视频抓图、给视频加水印等。视频采集功能 FFmpeg是在Linux下开发出来的,但它可以在包括Windows在内的大多数操作系统中编译。这个项目是由FabriceBellard发起的,现在由MichaelNiedermayer主持。 ffmpeg视频采集功能非常强大,不仅可以采集视频采集卡或USB摄像头的图像,还可以进行屏幕录制,同时还支持以RTP方式将视频流传送给支持RTSP的流媒体服务器,支持直播应用。 ffmpeg在Linux下的视频采集 在Linux平台上,ffmpeg对V4L2的视频设备提高了很好的支持,如: ./ffmpeg-t10-fvideo4linux2-s176*144-r8-i/dev/video0-vcodech263-frtprtp://192.168.1.105:5060>/tmp/ffmpeg.sdp 以上命令表示:采集10秒钟视频,对video4linux2视频设备进行采集,采集QCIF(176*144)的视频,每秒8帧,视频设备为/dev/video0,视频编码为h263,输出格式为RTP,后面定义了IP地址及端口,将该码流所对应的SDP文件重定向到/tmp/ffmpeg.sdp中,将此SDP文件上传到流媒体服务器就可以实现直播了。六、视频会议传输模块的开发选择视频会议主要是开发音视频、数据的传输的软件,在这些开发过程中,最核心的模块是传输模块,传输模块的性能直接影响到视频会议的最终质量,因此传输模块的选择在视频会议开发当中尤其重要。传输模块在开发过程中,由于考虑到QOS的影响,一般都会使用数据重发的技术,因此传输模块以及成为视频会议底层开发的一个重点,我们开发的传输模块,可以选择用TCP、UDP直接进行开发或者利用开源的传输库,因为一些开源传输库以及比较成熟,直接拿来用就可以,如果自己开发传输模块,估计也是一个巨大工程。现在我们介绍一下传输模块的开发选择。七、商用流媒体软件的选用如果项目在稳定性、安全性和责任约束上比较苛刻,还是建议选用商用产品。商用流媒体服务器软件的选择范围不大,基本上是国内外几家专业的公司在做,可选产品包括:Wowza、AdobeFlashMediaServer和国内NTVMediaServerG3等。Wowza是一个美国WowzaMediaSystems公司的产品,也是目前应用最广泛的一款流媒体服务器产品,在国内也有它的代理商。通过发放软件授权证书进行授权,可以按月、按年度购买使用授权,官网上有明确的报价。国内代理商加上自己的包装和技术支持费用,价格不一。AdobeFlashMediaServer是早些年使用最广泛的一款产品,产品成熟,价格相对高昂,随着Adobe公司退出中国市场,技术支持也主要有一些国内代理商负责。和Wowza一样,由于由国内厂商支持,加上语言、技术能力和时差等问题,在技术支持上并不尽人意。
-
ESP32-C3是搭载了开源指令集RISC-V的32位低功耗、低成本、安全的物联网芯片,本书也是该芯片原厂乐鑫科技的官方作品。本书从物联网工程开发的必备知识入手,循序渐进地介绍了硬件设计、外设驱动、ESP-IDF开发环境搭建、Wi-Fi网络配置、本地和云端控制、OTA升级原理、电源管理、低功耗优化、设备安全功能、固件版本管理和量产测试等方面的内容。物联网工程开发涉及的知识点很多,本书根据所涉及的知识点将全书分为4篇,分别是准备篇(第1~4章)、硬件与驱动开发篇(第5~6章)、无线通信与控制篇(第7~11章)、优化与量产篇(第12~15章),可帮助读者更好地掌握相关的知识点。
-
虽然Flutter的成长曲线和未来前景看起来都很好,但不可否认的是,目前Flutter仍处在发展阶段,很多大型互联网企业都无法毫无顾虑地让全线App接入,而其中最主要的顾虑是包大小与动态化。动态化代表着更短的需求上线路径,代表着大大压缩了原始包的大小,从而获得更高的用户下载意向,也代表着更健全的线上质量维护体系。当明白这些意义后,我们也就不难理解,在Flutter的应用与适配趋近完善时,动态化自然就成为了一个无法避开的话题。RN和Weex等成熟技术甚至让大家认为动态化是跨端技术的标配。一、什么是动态化?目前移动端应用的版本更新,最常见的方式是定期发版,无论是安卓还是iOS,都需要提交新的安装包到应用市场进行审核。审核通过后,用户在应用市场进行App的下载更新。而动态化,就是不依赖更新程序安装包,就能动态实时更新页面的技术。二、动态化的必要性为什么需要动态化技术呢?因为上述定期发版更新应用的方式存在一些问题,比如:1、审核周期长,且可能审核不通过。周期长导致发版本不够灵活,紧急的业务需求不能及时上线。2、线上出现急需修复的bug时,需要较长修复周期,影响用户体验。3、安装包过大,动辄几十兆几百兆的应用升级可能会让用户比较抗拒。4、即使上线了,也无法达到全部用户升级,服务端存在兼容多版本App的问题。三、Flutter的动态化可以通过在Flutter应用程序中集成可编程的UI组件来实现,例如将Dart代码作为字符串从服务器端下载并评估,从而生成新的UI元素。下面是一些设计思路和代码实现:1、使用Flutter的自定义渲染器(CustomRenderer):您可以编写一个自定义渲染器,该渲染器将解析从服务器或其他来源下载的UI描述,并使用FlutterFrameworkAPI构建UI元素。这种方法需要更多的开发工作,但它提供了更大的灵活性和控制权。2、使用FlutterWidget树序列化:FlutterWidget树可以序列化为JSON格式,并可以发送到移动设备上的Flutter应用程序。您可以使用此功能,从远程服务器下载UI树并将其反序列化为真实的Flutter组件树。3、使用Flutter插件:在Flutter中,插件是一个独立的、客户端库,在Flutter应用程序中运行。您可以编写一个插件,使其可以从云服务器下载所有UI元素并展示给用户四、实现思路 按道理iOS上也可以采取跟Android同样的思路,但是由于苹果开发者协议的规定,不允许动态更新、运行可执行代码;所以在Flutter资源的处理上,我们可以采用同Android一样的思路,但是对代码的处理,我们需要寻找新的方案。回顾之前的这些跨端方案,我们可以参照RN的实现,只不过N不再是Native了,而是Flutter。RN是通过JS控制Native渲染,我们要实现的是通过JS控制Flutter渲染。五、Flutter发展前景随着移动应用市场的不断扩大,跨平台开发框架的需求也越来越大。Flutter框架可以帮助开发者在不同平台上快速开发高质量的移动应用程序,这种趋势将进一步推动Flutter的发展和普及。作为一名Android开发工程师,学习Flutter框架是非常有必要的。因为现在的前端开发已经不仅仅局限于网页开发,而是需要涉及到多个平台的应用开发。如果掌握了Flutter框架的开发技能,就可以更好地满足前端开发的多样化需求。从19年过去的几年时间,Flutter在Google带领各大厂商的引领下,飞速发展。fluttersdk官方也在快速的迭代升级,从1.0到现在的3.1,从底层引擎到适配层再到框架层都有比较大的更新。六、Flutter动态化解决方案的两种方法:1.热重载(HotReload):热重载是Flutter框架的一项独特功能,它允许开发者在应用运行时快速预览代码更改的效果,而无需重新启动整个应用。热重载使开发人员可以实时查看界面、布局和功能等变化,并立即在应用中看到这些变化的效果。2.插件化(FlutterPlugin):插件化是一种在Flutter应用中集成动态化插件的方法,可以在应用运行时动态加载新的功能模块或代码。开发人员可以编写自定义插件,将其集成到应用中,以实现动态化更新和扩展功能的目的。七、动态化方案调研在Flutter实践层面,简单来说分为三个流派:方案一:JavaScript是最好的语言(碰瓷PHP)主要思路:利用Flutter做渲染,开发使用js,逻辑层通过v8/jscore解释运行。代表框架是腾讯的MXFlutter。这个框架是开源的,大写的。方案二:DSL+JS主要思路:基于模板实现动态化,主要布局层采用Dart转DSL的方式,逻辑层使用JS。代表框架是58同城开源的Fair。方案三:布局,逻辑,一把梭主要思路:与方案一最主要的区别是,逻辑层也是使用dart,增加了一层语法解析和运行时。有一个代表,美团的MTFlutter,然而没有开源动向,无从考察更多。
-
一、PyQT的概念PyQt是一个创建PythonGUI应用程序的工具包,是Qt和Python结合的一个产物,可以说是为了将Qt的功能用于Python开发的一个Qt的Python包装器。它是Python编程语言和Qt库的成功融合。PyQt的整个程序开发框架,主要包括如下部分:图形界面编辑的工具:QtDesigner不同部分信息交换机制:信号和槽界面操作的事件及捕获机制一套控制界面显示和数据存储分离以及映射的机制:Model/View架构通过这些重要的工具和框架机制,开发人员可以设计对应的GUI图形化界面、定义不同部件的操作及响应、捕获部件或应用的消息以及实现界面显示组件和数据存储组件的联动,从而构造完整的应用程序框架。PyQt实现了一个Python模块集。它有超过300类,将近6000个函数和方法。它是一个多平台的工具包,可以运行在所有主要操作系统上,包括UNIX,Windows和Mac。PyQt采用双许可证,开发人员可以选择GPL和商业许可。在此之前,GPL的版本只能用在Unix上,从PyQt的版本4开始,GPL许可证可用于所有支持的平台。二、OpenCVOpenCV项目最初由Intel于1999年启动,当时的目标是提供一个免费的计算机视觉库,并开放其源代码,以促进计算机视觉研究的发展。随后,OpenCV在2000年发布了第一个公开版本,从那时起,OpenCV迅速成为了计算机视觉领域最受欢迎的库之一。后来,OpenCV的开发由WillowGarage公司继续,随后由Itseez公司接管,直到今天,OpenCV的开发由OpenCV开发团队维护。核心功能和模块:OpenCV库包含了众多的模块,每个模块都提供了不同的功能,以下是一些核心的模块:2.1核心功能模块(CoreModule)这个模块提供了基本的数据结构和功能,包括图像数据类型、矩阵操作、文件IO等。图像操作:读取和保存图像:可以使用imread()函数读取图像文件,使用imwrite()函数保存图像到文件。图像属性访问:可以通过Mat对象的属性访问功能获取图像的尺寸、通道数、数据类型等信息。像素操作:可以直接访问和修改图像的像素值,或者使用像素迭代器遍历图像。图像通道操作:可以将多通道图像拆分成单通道图像,或者将单通道图像合并成多通道图像。创建矩阵:可以使用Mat类的构造函数或create()函数创建矩阵。矩阵运算:支持常见的矩阵运算,如加法、减法、乘法等。矩阵转换:可以对矩阵进行转置、仿射变换、透视变换等操作。2.2图像处理模块(ImageProcessingModule)OpenCV的图像处理模块提供了各种图像处理算法,包括图像滤波、边缘检测、图像变换等。这些算法可以帮助用户对图像进行预处理、增强、分析和特征提取等操作。下面是图像处理模块中常用的功能和算法:图像滤波(ImageFiltering):平滑滤波(SmoothingFilters):如均值滤波、高斯滤波、中值滤波等,用于去除图像中的噪声。锐化滤波(SharpeningFilters):如拉普拉斯滤波器、Sobel滤波器等,用于增强图像的边缘和细节。图像变换(ImageTransformations):几何变换(GeometricTransformations):如平移、旋转、缩放、仿射变换等,用于调整图像的尺寸和位置。透视变换(PerspectiveTransformation):用于校正图像中的透视失真。边缘检测(EdgeDetection):Sobel算子:Sobel算子通常用于灰度图像的边缘检测,其基本思想是利用图像中像素灰度值的变化情况来识别边缘。Sobel算子在水平和垂直方向上分别定义了两个卷积核(通常为3x3的矩阵),用于计算图像中每个像素点的水平和垂直方向的梯度值。Canny边缘检测:首先,对输入图像进行高斯滤波,以减少图像中的噪声。高斯滤波可以平滑图像,并模糊图像中的细节,从而有助于检测到真实的边缘。在经过高斯滤波的图像上,利用Sobel算子或其他梯度算子计算图像的梯度幅值和梯度方向。梯度方向可以帮助确定边缘的方向。对图像中的梯度幅值进行非极大值抑制,保留局部梯度幅值最大的像素点,以使得边缘变得更细化。利用双阈值检测策略对梯度幅值进行阈值处理,将图像中的像素点分为强边缘、弱边缘和非边缘三类。通常设置两个阈值,一个是高阈值(highthreshold),用于确定强边缘像素;另一个是低阈值(lowthreshold),用于确定弱边缘像素。通过连接强边缘像素,利用弱边缘像素进行边缘跟踪,得到完整的边缘。三、人工智能应用人工智能在生活中的应用有:1、虚拟个人助理,使用者可通过声控、文字输入的方式,来完成一些日常生活的小事;2、语音评测,利用云计算技术,将自动口语评测服务放在云端,并开放api接口供客户远程使用;3、无人汽车,主要依靠车内的以计算机系统为主的智能驾驶仪来实现无人驾驶的目标;4、天气预测,通过手机gprs系统,定位到用户所处的位置,在利用算法,对覆盖全国的雷达图进行数据分析并预测。
-
当下,同城代驾服务越来越受到人们的青睐。为了满足市场需求,许多企业开始开发智能调度系统,以提高服务效率和用户体验。本文将介绍如何搭建一个智能调度系统,并以同城代驾小程序的开发为例进行详细教学。一、技术要求1、平台选择当前主流的平台有iOS和Android,开发者需要根据目标用户的偏好和市场占有率做出选择。同时,还需要考虑平台的开发成本和技术难度等因素。2、功能设计代驾app软件需要具备一些基本功能,如注册登录、订单管理、定位导航等。同时还可以考虑增加一些创新的功能,如在线支付、评价系统等,以提升用户体验和竞争力。3、安全保障代驾服务涉及到用户的个人信息和支付信息,安全性至关重要。在软件开发过程中,需要加强安全保障措施,如数据加密、身份验证等,以保护用户的隐私和安全。二、用户体验1、界面设计代驾app软件的界面设计要简洁明了,符合用户的使用习惯和视觉需求。合理的布局和颜色搭配,清晰的操作流程,能够提升用户的体验和满意度。2、易用性分析代驾app软件开发过程中,应注重易用性的考虑。例如,可以采用简洁明了的图标和按钮,提供明确的操作指引,减少用户的学习成本和操作困难,从而提高用户的使用效率和满意度。3、反馈机制代驾app软件应该提供及时的反馈机制,让用户能够随时了解订单的状态和司机的位置等信息。同时,还应该给用户提供反馈渠道,以便他们及时解决问题和提出建议。三、代驾小程序开发需要多少钱?代驾小程序最终的价格还是要看功能的,越复杂的功能越贵,几千到几万都有。上面推荐给大家的使用智能小程序搭建软件的方法,像上面那个代驾小程序的案例功能这么多的小程序,也就只需要千来块,性价比还是不错的。当然,不满足上面这些功能的老板们,可以选择专业定制,价格几万块但功能会更加全面。四、代驾APP开发有哪些好处1、对于代驾人员来说:代驾APP的开发无疑是为自己增加了客户来源,通过APP代驾人员无须担心车主因为醉酒而无法结算费用的问题。这样既可以保证自己的利益,又能获得更多的客户,不是一举两得吗?2、对于车主而言:代驾APP的到来无疑是为自己的安全带来了保障。让车主可以没有后顾之忧,可以畅饮开怀享受难得的团聚时光。3、对于相关部门来说:代驾APP的到来可以有效地降低交通事故发生率,提高行车安全意识,增强对法律法规的认知,从而更好地构建一个和谐社会。五、代驾app开发,你需要知道的一些技术!一.原生开发什么是原生开发?原生开发(NativeApp开发)就像盖房子,先打地基然后浇地梁、房屋结构、一砖一瓦、钢筋水泥、电路走向等,原生APP同理:通过代码从每个页面、每个功能、每个效果、每个逻辑、每个步骤全部用代码写出来,一层层,一段段全用代码写出来。传统的app是用H5或混合开发,成本不高,但是bug很多,兼容性不好,最直接的体现就是用户进入app十分不流畅,而且有时会发生卡顿、卡页面的现象。二.服务器服务器决定了app在高峰时会不会卡顿,是否流畅,如果服务器的稳定性和承载量不够高,就会出现用户不能良好的刷新页面,无法呼叫代驾,看起来是网络不稳,其实是服务器带不起来。三.长连接即时通讯模式长连接功能指的是代驾司机开展代驾业务时,能够让自己的移动定位实时显示在app界面,用户可以随时查看司机位置,而且都不会出现迟钝、不动的现象。
-
一、前言在Kubernetes(K8s)中,Pod是最小的可调度单元。当Spark任务运行在K8s上时,无论是Driver还是Executor都由一个单独的Pod来表示。每个Pod都被分配了一个唯一的IP地址,并且可以包含一个或多个容器(Container)。Driver和Executor的JVM进程都是在这些Container中启动、运行和销毁的。当一个Spark作业被提交到K8s集群后,首先会被启动的是DriverPod。然后,Driver负责按需向Apiserver请求创建ExecutorPods。Executor负责执行具体的Task。一旦作业完成,Driver将负责清理所有已创建的ExecutorPods。二、在将Spark任务提交到K8s集群上时,不同的公司可能会采取不同的方法。以下是目前常见的几种做法以及我们在线上所采用的任务提交和管理方式。1、使用原生spark-submit原生的spark-submit命令可以直接提交作业,集成起来简单且符合用户习惯。然而,这种方法不便于作业状态跟踪和管理,无法自动配置SparkUI的Service和Ingress,并且在任务结束后不能自动清理资源。因此,在生产环境中并不适合使用这种方式。2、使用spark-on-k8s-operator这是目前较常用的一种提交作业方式,需要先在K8s集群中安装spark-operator。客户端通过kubectl提交yaml文件来运行Spark作业。本质上,这是对原生方式的扩展,提供了作业管理、Service/Ingress创建与清理、任务监控、Pod增强等功能。尽管此方法可在生产环境中使用,但它与大数据调度平台的集成性较差,对于不熟悉K8s的用户来说,学习曲线较为陡峭。3、使用spark-k8s-cli在我们的生产环境中,我们使用spark-k8s-cli来提交任务。spark-k8s-cli是一个可执行文件,基于阿里云emr-spark-ack提交工具进行了重构、功能增强和深度定制。它融合了spark-submit和spark-operator两种作业提交方式的优点,所有作业都能通过spark-operator管理,并支持交互式spark-shell和本地依赖的提交。同时,它的使用方式与原生spark-submit完全一致。三、sparkonk8s的优点和缺点优点:1.资源隔离:SparkonKubernetes可以更好地管理资源,实现资源隔离,避免不同应用之间的资源竞争。2.灵活性:Kubernetes支持弹性伸缩,可以根据应用的需求自动扩容或缩容。3.易于部署:使用Kubernetes集群部署Spark应用更加简单方便,不需要手动管理集群资源。缺点:1.性能开销:在Kubernetes上运行Spark会带来一定的性能开销,相比传统的YARN或Mesos部署方式可能会有性能损失。2.学习成本:需要对Kubernetes和Spark有一定的了解,对于初学者来说可能需要花费一定时间学习。3.依赖外部组件:可能需要额外的监控和调优工具来对Spark应用进行管理,增加了系统的复杂度。四、Spark的集群部署模式Spark官方提供了四种集群部署的模式:Standalone、YARN、Mesos、Kubernetes。Standalone需要常驻Master服务和Worker服务。它作为资源调度,只能去调度Spark做作业。同时它需要每个节点预先准备好Spark运行时环境,所以不太适合生产环境使用。YARN在传统的大数据体系下是一个比较好的调度器。它不需要常驻Spark相关的服务,YARN的容器内其实也是可以进行任何作业的,但是需要每个节点去事先准备好运行时环境,YARN其实是更贴近于我们的传统Hadoop生态,它也有一些调度上的优化,比如计算时会尽可能地去找数据所在的HDFS节点,不过在我们云原生的场景下就不太适用了。Mesos在Spark3.2版本后已经被标记为弃用了,所以我们就不过多谈它。Kubernetes也是无需常驻Spark相关服务,支持容器化运行任何作业,也不需要依赖节点运行时环境,它是更贴近于云原生生态的。五、Sparkonk8s如何运行首先Spark有一个客户端,客户端会构建好driverpod对象,向K8s的apiserver发送请求,去创建driverpod,Spark的driver进程运行在driverpod当中。Sparkdriver启动之后,会在driver内构建executorpod的对象,创建executorpod,并持续watchandlist去监听每一个executorpod的状态。当任务运行结束的时候,executorpod会被清理,driverpod会继续以completed的状态存在。这就是SparkonK8s的运行过程。六、关于spark配置使用spark难免会需要一些hdfs、hive-metastore等配置、xml等,把这些配置打到镜像里显然可以,但很不灵活。本地spark-submit进程创建pod时会将本地的spark配置作为configMap挂在到pod中,所以只要维护好本地提交的spark环境即可,可以先通过kubectldescribe pod**来找到对相应的configMap,然后通过kubectldescribe configmap来确认配置
-
2024全新Langchain大模型AI应用与多智能体实战开发一、Langchain是什么LangChain是一个新一代的AI开发框架,旨在释放大语言模型的潜能,为开发者提供便捷的开发工具和接口。LangChain是一个帮助在应用程序中使用大型语言模型(LLM)的编程框架。与生成式AI中的所有东西一样,这个项目的发展也非常迅速。2022年10月,它先是作为一款Python工具,然后在今年2月增加了对TypeScript的支持。到今年4月,它支持多种JavaScript环境,包括Node.js、浏览器、CloudflareWorkers、Vercel/Next.js、Deno和SupabaseEdgeFunctions。二、什么是智能体?LLM智能体的定义非常宽泛:它们指的是所有将LLMs作为核心引擎,并能够根据观察对其环境施加影响的系统。这些系统能够通过多次迭代“感知⇒思考⇒行动”的循环来实现既定任务,并常常融入规划或知识管理系统以提升其表现效能。你可以在Xietal.,2023的研究中找到对智能体领域综述的精彩评述。 三、深入6大组件LangChain中的具体组件包括:模型(Models),包含各大语言模型的LangChain接口和调用细节,以及输出解析机制。提示模板(Prompts),使提示工程流线化,进一步激发大语言模型的潜力。数据检索(Indexes),构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。记忆(Memory),通过短时记忆和长时记忆,在对话过程中存储和检索数据,让ChatBot记住你是谁。链(Chains),是LangChain中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成常见用例。代理(Agents),是另一个LangChain中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使强大的“智能化”自主Agent成为可能!你的App将产生自驱力!总体来讲,LangChain是AI智能时代基于LLM大模型的开发框架。第一、它是上下文相关的,为LLM应用程序开发的整体生命周期提供全流程的框架支持。第二、使用LLM大模型的推理能力为LangChain开发的LLM应用程序提供规划能力(Planning)。第三、LangChain围绕开发LLM应用程序的整体流程提供ModelI/O(Prompt输入、Embedding向量化、LLM大模型适配以及大模型回答适配等)、Retriieval(数据源加载、转换、向量化、存入向量数据库、检索以及向量相识度计算等)、Chains(用于完成特定更高级别任务的组件组装)、Memory(短期记忆、长期记忆)、Agents(LLMAPP)、Callbacks(提供向外部回调的功能)。LangChain是一个旨在帮助您轻松构建大语言模型应用的框架,它提供如下功能:为各种不同基础模型提供统一接口(参见Models)帮助管理提示的框架(参见Prompts)一套中心化接口,用于处理长期记忆(参见Memory)、外部数据(参见Indexes)、其他LLM(参见Chains)以及LLM无法处理的任务的其他代理(例如,计算或搜索)。因为LangChain有很多不同的功能,所以一开始可能很难理解它的作用。因此我将在本文中介绍LangChain的(当前)六个关键模块,以便您更好地了解其功能。四、LangChain在不同领域的应用案例金融行业:LangChain应用系统可以应用于金融领域,帮助银行和金融机构进行智能客服、风险管理、舆情监控等工作,提升金融服务的质量和效率。医疗健康:在医疗健康领域,LangChain可以用于患者健康管理、医疗咨询、疾病诊断等方面,为医疗机构和患者提供更好的医疗服务。教育培训:LangChain应用系统可以用于教育培训行业,支持在线教育、智能学习系统、智能答题系统等应用,提升教育教学的效果和效率。零售行业:在零售行业,LangChain可以应用于智能客服、商品推荐、用户评论分析等方面,帮助零售企业提升销售额和客户满意度。LangChain应用系统的出现,为各行各业带来了新的发展机遇和挑战。随着人工智能技术的不断进步和应用场景的不断拓展,我们有理由相信,LangChain将会在未来发挥越来越重要的作用,为社会进步和发展做出更大的贡献。
-
一.什么是微前端“微前端架构”就是构建基于微服务的前端应用架构。其思想是将前端应用切分为一系列可以单独部署的松耦合的应用,然后将这些应用组装起来创建单个面向用户的应用程序。二.微前端的优势降低代码耦合独立开发、独立部署增量升级:微前端是一种非常好的实施渐进式重构的手段和策略独立运行时,每个微应用之间状态隔离,运行时状态不共享团队可以按照业务垂直拆分更高效三、微前端是一种前端架构模式,它将Web应用程序拆分为一组小型、可独立开发和部署的模块,每个模块可以由不同的团队开发和维护。这种模块化的架构可以帮助开发团队降低Web应用程序的规模和复杂度,从而提高应用程序的可维护性和可扩展性。微前端的概念最早由ThoughtWorks公司的技术总监CamJackson在2016年提出。他认为,微前端可以帮助团队将大型Web应用程序拆分为小型模块,从而更好地满足不同业务需求,提高应用程序的可维护性和可扩展性。自此之后,微前端逐渐成为了一种前端技术趋势,得到了越来越多的关注和支持。微前端的背景源于大型Web应用程序的发展和演进。随着Web应用程序的规模和复杂度的不断增加,前端开发团队面临越来越多的挑战,例如开发和维护难度大、代码耦合度高、性能问题等等。微前端通过将Web应用程序拆分为小型、可独立开发和部署的模块,从而降低了这些挑战的难度,提高了Web应用程序的可维护性和可扩展性。四、微前端的挑战包括:技术复杂度:微前端需要使用一些新的技术和工具来实现模块化开发、模块间通信和集成等功能,需要开发团队具备一定的技术实力和经验。项目规模限制:微前端适用于大型Web应用程序,但对于小型应用程序,可能会带来过度的复杂度和不必要的开销。性能问题:微前端需要在运行时动态加载模块,可能会影响应用程序的性能和响应速度,需要通过一些优化措施来解决。跨域问题:微前端需要在不同的域名下部署不同的模块,可能会带来跨域问题,需要通过一些跨域解决方案来解决。五、micro模块micro-app是京东零售推出的一款微前端框架,它基于类WebComponent进行渲染,从组件化的思维实现微前端,旨在降低上手难度、提升工作效率。它是目前接入微前端成本最低的框架,并且提供了JS沙箱、样式隔离、元素隔离、预加载、资源地址补全、插件系统、数据通信等一系列完善的功能。MicroApp借鉴了WebComponent的思想,通过CustomElement结合自定义的ShadowDom,将微前端封装成一个类WebComponent组件,实现微前端的组件化渲染。在此基础上,通过实现JS隔离、样式隔离、路由隔离,降低子应用的接入成本,子应用只需设置允许跨域请求,不需要改动任何代码即可接入微前端,使用方式和iframe几乎一致,但却没有iframe存在的问题。用于给应用赋能微前端,使其成为主应用,能够内部接入子应用。入口index.js:用于和主应用初始化接入;appConfigs.js:用于配置要接入子应用的相关信息;commonApi.js:公用的接口函数,透传给子应用使用;appTemplate.vue:子应用展示容器,类似于iframe效果;router.js:主应用中处理过后的子应用路由地址,最后合并接入到主应用路由文件。六、集成与部署策略在微前端架构中,集成与部署策略是至关重要的。以下是一些常见的集成与部署策略:构建时集成:在主应用的构建过程中,将微应用的代码打包到主应用的代码中。这种方式适用于微应用较少且更新不频繁的情况。运行时集成:主应用在运行时动态加载微应用的代码。这种方式可以实现微应用的独立部署和按需加载,适用于微应用较多且更新频繁的情况。独立部署:每个微应用都可以独立部署,主应用通过配置来管理微应用的版本和加载地址。这种方式可以实现微应用的并行开发和持续集成/持续部署(CI/CD),提高开发效率。容器化部署:使用Docker等容器化技术将每个微应用打包成容器进行部署。这种方式可以实现微应用的环境隔离和弹性扩展。
-
一、什么是微服务架构微服务架构是一种面向服务的架构风格,通过将应用程序拆分为小的、自治的服务单元,以提高系统的灵活性、可扩展性和可维护性。它是一种软件设计和开发的方法论,它将一个应用程序拆分成一组小而独立的服务单元,这些服务单元可以独立部署、扩展和管理。每个服务单元都专注于完成特定的业务功能,并通过轻量级的通信机制(通常是HTTP或消息队列)与其他服务单元协同工作。二、伴随着云计算、容器技术、大数据等新兴技术的不断涌现,微服务架构因为其高度可扩展性、灵活性等特点,越来越受到人们的青睐。在微服务架构中,每个服务都是一个独立的进程,每个进程都有自己的数据存储方式,操作系统环境等等。微服务通过通信协议(如http、grpc等)互相通信,形成为支撑大型应用系统的服务群。Go语言作为一个轻量级的,高并发的静态编译型语言,其天然的优势使其成为微服务开发的首选语言之一,内置的goroutine和channel机制保证了Go语言在高并发场景下极高的性能和稳定性。如何使用Go语言开发微服务呢?下面将从以下几个方面进行详细阐述。1、拆分微服务架构师应该首先根据业务模型,将整个应用拆分成若干个独立的服务。拆分的原则是保证每个微服务模块足够小,不要包含过多的业务逻辑,只保留服务本身的核心功能。通过手工埋点或开源工具例如Skywalking等方式,对微服务模块进行详细的跟踪和性能分析,发现程序中的瓶颈,进行优化。2、选择框架Go语言的生态系统非常完善,涵盖了很多优秀的微服务框架。开发过程中,架构师可以根据需求选择不同的框架进行集成。以下是几个常见的Go语言微服务框架:Gokit:提供了许多开箱即用的微服务类库,包括服务发现、负载均衡、日志、跟踪等等,同时提供了一个可扩展的RPC库,以供用户使用。但Gokit的组件相对独立,而且很多组件都是不可配置的,这会导致底层实现较为复杂。Micro:该框架用于处理复杂和高度可分布式的系统,具有良好的可扩展性和服务发现功能。但是,在使用micro时,需要解决API网关、负载均衡和安全问题等复杂问题。Gin:是一个轻量级且快速的HTTPWeb框架,适用于创建RESTAPIs和中较大规模的Web应用程序。通过它可以快速创建服务,但要注意的是,它仅仅是一个Web框架,所以它并不能处理微服务框架所应该处理的所有东西。三、Go语言与微服务架构与分布式系统的联系Go语言在微服务架构和分布式系统中发挥了重要作用。它的简洁的语法和强大的并发能力使得开发者可以快速编写高性能的分布式应用程序。此外,Go语言的内置支持和丰富的生态系统,使得开发者可以轻松地实现微服务之间的通信和协同工作。四、Go-Zero的核心特性简洁与高效:Go-Zero的设计理念强调简洁与高效,它提供了丰富的组件和工具,帮助开发者快速构建微服务应用。同时,Go-Zero注重性能优化,通过合理的资源分配和并发控制,确保系统在高负载下仍能保持稳定运行。自动化与智能化:Go-Zero支持自动化代码生成和配置管理,降低了开发者的手动操作成本。此外,它还具备智能负载均衡、容错处理等功能,提高了系统的可用性和可靠性。可扩展与可定制:Go-Zero具有良好的可扩展性,支持水平扩展和垂直扩展,满足不同规模的业务需求。同时,开发者可以根据项目需求,自定义组件和插件,实现高度定制化的功能。五、服务之间如何通信所有的微服务都是独立部署,运行在自己的进程容器中,所以微服务与微服务之间的通信就是IPC(InterProcessCommunication),翻译为进程间通信。进程间通信的方案已经比较成熟了,现在最常见的有两大类:同步调用、异步消息调用。同步调用同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。同步调用的有两种实现方式:分别是REST和RPCREST:REST基于HTTP,实现更容易,各种语言都支持,同时能够跨客户端,对客户端没有特殊的要求,只要具备HTTP的网络请求库功能就能使用。RPC:rpc的特点是传输效率高,安全性可控,在系统内部调用实现时使用的较多。基于REST和RPC的特点,我们通常采用的原则为:向系统外部暴露采用REST,向系统内部暴露调用采用RPC方式。六、go-zero和gin区别Go-Zero和Gin都是基于Go语言的Web框架,但二者有一些区别:设计思路不同:Go-Zero的设计思路是面向SOA的微服务框架,提供了丰富的微服务组件和代码生成工具,帮助开发者快速构建微服务应用系统。而Gin则是一个轻量级的Web框架,适用于构建小型Web应用系统。组件不同:Go-Zero提供了很多微服务组件,包括RPC调用、流控、服务注册等等,适用于复杂微服务系统的开发。Gin则提供了一些Web开发需要的基本组件,比如HTTP接口、路由、中间件等,适用于小型Web系统的开发。代码生成工具:Go-Zero提供了一些代码生成
-
一、QT概述Qt是1991年由HaavardNord和EirikChambe-Eng开发的跨平台C++图形用户界面应用程序开发框架。发展至今,它既可以开发GUI程序,也可以开发非GUI程序,比如控制台工具和服务器。Qt是一个跨平台的C++应用程序框架,支持Windows、Linux、MacOSX、Android、嵌入式系统等。也就是说,Qt可以同时支持桌面应用程序开发、嵌入式开发和移动开发,覆盖了现有的所有主流平台。开发者只需要编写一次代码,而后在发布到不同平台之前重新编译即可。Qt的工具家族丰富,目前包括QtCreator、QtEmbedded、QtDesigner快速开发工具、国际化工具等。Qt实质上是用C++编写的大型类库,它为跨平台应用开发提供了一个完整的框架。Qt框架包含大量的类,支持GUI、数据库、网络、多媒体等各种应用的编程。Qt还对标准C++语言进行了扩展,引入了信号与槽、属性等机制,为跨平台和GUI程序的对象间通信提供了极大的方便。Qt还提供了一种自创的编程语言QML,它是类似于JavaScript的声明性语言。Qt提供了一个用QML编写的库QtQuick,它类似于QtC++类库,区别是QtQuick中的各种控件被称为QML类型(type)。QML用于描述程序的用户界面,将用户界面描述为对象树,每个对象具有自己的各种属性。Qt也支持Python,Qt类库的Python绑定版本比较多,比较常用的是PyQt和PySide二、Qt6软件特性Qt6是一款专业实用的编程开发工具。Qt6最新版优化了稳定性、功能性,并且包含Qt5.15中的所有常用功能以及为Qt6 添加的新功能。Qt6软件大大扩展了支持平台的范围,支持AppleSilicon上的macOS,同时改进了对WebAssembly的支持。QT6.0加入了许多新功能,以更好地支持现代工作负载,包括开始应用C++17,官方提到,Qt6现在要求使用的C++17兼容编译器,以便在开发QT应用程序时,使用较新的C++语言结构。另外,QT6还更新CMake构建系统,且采用全新的图形架构,并以QtQuick统一2D与3D开发体验。三、软件优点Qt6的架构变化Qt6中进行了一些更广泛的架构更改,包括:Qt6现在依赖于C++17兼容的编译器,这有助于清理和改进代码库,并为用户提供更现代的API在处理大型数据集和性能方面改进了低级容器类持续更新QML语言,使其更安全、更易于使用四、QML访问C++Qt集成了QML引擎和Qt元对象系统,使得QML很容易从C++中得到扩展,在一定的条件下,QML就可以访问QObject派生类的成员,例如信号、槽函数、枚举类型、属性、成员函数等。QML访问C++有两个方法:一是在Qt元对象系统中注册C++类,在QML中实例化、访问;二是在C++中实例化并设置为QML上下文属性,在QML中直接使用。第一种方法可以使C++类在QML中作为一个数据类型,例如函数参数类型或属性类型,也可以使用其枚举类型、单例等,功能更强大。五、C++类的实现C++类要想被QML访问,首先必须满足两个条件:一是派生自QObject类或QObject类的子类,二是使用Q_OBJECT宏。QObject类是所有Qt对象的基类,作为Qt对象模型的核心,提供了信号与槽机制等很多重要特性。Q_OBJECT宏必须在private区(C++默认为private)声明,用来声明信号与槽,使用Qt元对象系统提供的内容,位置一般在语句块首行。Projects选择QtQuickApplication,工程名为Hello。六、Qt版本Qt的版本可以根据许可类型分为商业许可和开源许可,开源许可又分为GPLv2/GPLv3和LGPLv3。(1)商业版:商业许可需要付费,Qt公司目前采用的是按年付费的方式。商业许可允许开发者不公开项目的源代码。商业许可的Qt安装包里有更多的模块,某些模块只有在商业许可的版本中才有。(2)开源版:采用GPLv2/GPLv3许可。若用户编写的程序使用了GPL许可的Qt代码,则用户程序也必须使用GPL许可,也就是用户代码必须开源,但是允许商业化销售。GPLv3还要求用户公开相关硬件信息。简单来说,就是你“免费”使用的东西必须也“免费”提供给别人使用。根据开发目标的不同,Qt提供了3种安装包。安装包具有针对不同主机平台的版本,而且采用了不同的许可协议。
-
在现代软件开发中,图形用户界面(GUI)是用户与程序交互的重要组成部分。Qt框架提供了一种强大的方式来构建跨平台的GUI应用程序,其中QML(QtMeta-ObjectLanguage)和C++的交互是一个重要的主题。本篇博文将深入探讨如何在QML中创建和操作C++对象,实现双向的交互。在Qt中,任何QML代码都可以访问QObject派生类实例的属性、方法和信号。以下是一个简单的C++类CppObject,演示了如何在QML中创建并操作该类的对象。由于QML引擎与Qt元对象系统的集成,可以从QML中访问任何从QObject继承的类的属性、方法和信号,C++代码既可以在应用中集成,也可以在插件中集成。QML访问C++数据主要有三种方法:1、将C++类的属性暴露给QML;2、从C++定义QML类型;3、用Context属性在QML中嵌入C++对象;自定义数据类型16种基础数据类型以外的其它数据类型是QML所无法识别的,可将它定义为复杂数据类型,结构体数据类型属于复杂数据类型中的一种。由于QObject子类都可以注册为QML对象类型,所以构造结构体对应的自定义类来与QML交互是可行的。创建自定义对象在Qt中,我们可以使用QObject作为基类创建自定义对象。首先,我们需要在C++中定义一个继承自QObject的类,并将其注册到QML中,使得QML可以访问到这个对象。具体的步骤如下:创建一个新的C++类,例如MyObject,并继承自QObject。在MyObject类中声明需要在QML中访问的属性和函数,并使用Q_PROPERTY和Q_INVOKABLE宏进行标记。在MyObject类中添加需要在QML中访问的信号,并使用Q_SIGNAL宏进行标记。在MyObject类中添加相应的槽函数,并在函数实现中处理信号的逻辑。在Qt的主程序中,使用qmlRegisterType函数将MyObject类注册到QML引擎中。如何实现可以被QML访问的C++类C++类要想被QML访问,首先必须满足两个条件:一是派生自QObject类或QObject类的子类,二是使用Q_OBJECT宏。QObject类是所有Qt对象的基类,作为Qt对象模型的核心,提供了信号与槽机制等很多重要特性。Q_OBJECT宏必须在private区(C++默认为private)声明,用来声明信号与槽,使用Qt元对象系统提供的内容,位置一般在语句块首行。下面例子在QtCreator3.1.2中创建,Projects选择QtQuickApplication,工程名为Gemini,Component选择QtQuick2.2,然后在自动生成的文件中添砖加瓦。QML访问C++一个C++类要想被QML访问,必须满足两个条件:1、从QObject类或QObject类的子类派生继承2、使用Q_OBJECT宏这和使用信号与槽的前提条件是一样的。QObject类是所有Qt对象的基类,作为Qt对象模型的核心,提供了信号与槽机制等很多重要特性。这两个条件是为了让一个类能够进入Qt强大的元对象系统(meta-objectsystem)中,而使用元对象系统,一个类的某些方法或属性才可能通过字符串形式的名字来调用。我们知道,QML其实是对JavaScript的扩展,融合了QtObject系统,它是一种新的解释型的语言,QML引擎虽然由QtC++实现,但QML对象的运行环境,说到底和C++对象的上下文环境是不同的,是平行的两个世界。如果你想在QML中访问C++对象,那么必然要找到一种途径来在两个运行环境之间建立沟通桥梁。Qt提供了两种在QML环境中使用C++对象的方式:(1)在C++中实现一个类,注册到QML环境中,QML环境中使用该类型创建对象。(2)在C++中构造一个对象,将这个对象设置为QML的上下文属性,在QML环境中直接使用该属性。
-
一、什么是WebRTCWebRTC(WebReal-TimeCommunications)是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输。WebRTC包含的这些标准使用户在无需安装任何插件或者第三方的软件的情况下,创建点对点(Peer-to-Peer)的数据分享和电话会议成为可能。WebRTC只是一个媒体引擎,上面有一个JavaScriptAPI,所以每个人都知道如何使用它(尽管浏览器实现仍然各不相同),本文对WebRTC(网页实时通信)的相关内容进行简要介绍。二、WebRTC简介WebRTC,名称源自网页实时通信(WebReal-TimeCommunication)的缩写,是一个支持网页浏览器进行实时语音通话或视频聊天的技术,是谷歌2010年以6820万美元收购GlobalIPSolutions公司而获得的一项技术。WebRTC提供了实时音视频的核心技术,包括音视频的采集、编解码、网络传输、显示等功能,并且还支持跨平台:windows,linux,mac,android。虽然WebRTC的目标是实现跨平台的Web端实时音视频通讯,但因为核心层代码的Native、高品质和内聚性,开发者很容易进行除Web平台外的移殖和应用。很长一段时间内WebRTC是业界能免费得到的唯一高品质实时音视频通讯技术。1、webrtc是什么浏览器为音视频获取传输提供的接口2、webrtc可以做什么浏览器端到端的进行音视频聊天、直播、内容传输3、数据传输需要些什么IP、端口、协议客户端、服务端三、如何使用WebRTCWebRTC易于使用,只需极少步骤便可建立媒体会话。有些消息在浏览器和服务器之间流动,有些则直接在两个浏览器(成为对等端)之间流动。建立WebRTC会话建立WebRTC连接需要如下几个步骤:获取本地媒体(getUserMedia(),MediaStreamAPI)在浏览器和对等端(其它浏览器或终端)之间建立对等连接(RTCPeerConnectionAPI)将媒体和数据通道关联至该连接交换会话描述(RTCSessionDescription)四、面向网络的实时通信借助WebRTC,您可以为应用添加基于开放标准运行的实时通信功能。它支持在对等设备之间发送视频、语音和通用数据,使开发者能够构建强大的语音和视频通信解决方案。这项技术适用于所有现代浏览器以及所有主要平台的原生客户端。WebRTC采用的技术是开放网络标准,以常规JavaScriptAPI的形式在所有主流浏览器中提供。对于原生客户端(例如Android和iOS应用),可以使用具备相同功能的库。WebRTC项目属于开源项目,受Apple、Google、Microsoft和Mozilla等公司支持。五、WebRTC使用入门WebRTC标准概括介绍了两种不同的技术:媒体捕获设备和点对点连接。媒体捕获设备包括摄像机和麦克风,还包括屏幕捕获设备。对于摄像头和麦克风,我们使用navigator.mediaDevices.getUserMedia()来捕获MediaStreams。对于屏幕录制,我们改为使用navigator.mediaDevices.getDisplayMedia()。点对点连接由RTCPeerConnection接口处理。这是在WebRTC中两个对等方之间建立和控制连接的中心点。六、使用WebRTC协议进行音视频通信的步骤如下:1、获取本地媒体流:使用navigator.mediaDevices.getUserMedia方法获取本地摄像头或麦克风的媒体流。2、创建PeerConnection:使用newRTCPeerConnection(configuration)方法创建一个PeerConnection实例,其中configuration是PeerConnection的配置参数,例如STUN/TURN服务器地址等。3、添加ICECandidate:通过监听icecandidate事件获取到本地的ICECandidate,然后使用addIceCandidate方法将其添加到PeerConnection中。4、发送SDP:通过createOffer或者createAnswer方法生成本地的SDP(SessionDescriptionProtocol),并使用setLocalDescription方法设置到PeerConnection中5、接收SDP:通过信令服务器将远端的SDP发送给本地,然后使用setRemoteDescription方法设置到PeerConnection中。6、媒体流交换:当PeerConnection连接成功后,可以通过addTrack或者addStream方法将本地的媒体流添加到PeerConnection中,并且通过监听ontrack事件获取到远端的媒体流。7、关闭连接:使用close方法关闭PeerConnection。这些步骤可以使用WebRTC库来简化实现。在实际应用中,还需要考虑网络环境、协议版本兼容性、安全问题等因素。
-
Kubernetes,简称K8s,是一个开源系统,用于自动化部署、扩展和管理容器化应用程序。它提供了基本机制来部署、维护和扩展应用程序,支持跨多个主机的容器应用。K8s是Go语言开发的,建立在Docker之上,可以看作是Docker的上层架构。它的主要功能包括应用部署、维护、扩展,集群管理、安全防护、准入机制、多应用支撑、服务注册与发现、智能负载均衡、故障发现与自我修复、服务滚动升级、在线扩容、资源配额管理等。K8s通过容器的方式来管理应用程序,使得容器集群能够运行在用户期望的状态,并解决容器跨机器通信的问题。DevOps(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。容器技术是k8s中最关键的技术,通过容器技术可以将一台实体服务器资源虚拟化为多个隔离的容器,容器之间有较高的隔离级别,可像一台独立的服务器般部署程序并对外提供服务。简单来说,可以把容器简单视为一个特殊的进程,该进程与其他进程相隔离,在自己的命名空间下使用网络接口和文件,并且该进程只能使用硬件的部分资源。容器技术的基础是linux命令空间和cgroups,其中:(1)容器的隔离是基于linux命令空间来实现的,命名空间提供了一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的命名空间中,来实现资源隔离的目的。不同命名空间的进程,可以享有一份独立的系统资源。(2)硬件资源的限制是通过cgroups实现的,cgroups是一个linux内核功能,它被用来限制一个进程或者一组进程的资源(cpu、内存、带宽等)使用,被限制的进程不能过分使用为其他进程保留的资源。容器技术与微服务概念相得映彰,微服务概念强调将一个大的系统拆分为若干微服务,每个微服务实现系统的特定功能,通过这个方式来减少系统的耦合。一般而言,一个微服务所需的系统资源并不需要很多,使用一个容器来部署一个微服务便成了一件很合适的事情,毕竟容器创建简单、资源可控,隔离性好、扩容方便。Kubernetes中的CRD(CustomResourceDefinition,自定义资源定义)允许用户扩展API服务器以支持新的自定义资源。使用CRD,用户可以定义自己的KubernetesAPI资源类型,并在Kubernetes集群中创建、管理和操作这些自定义资源。CRD的创建和使用通常涉及以下几个步骤:创建CRD定义:创建一个CRD定义文件,例如customresource.yaml,其中包含自定义资源的结构和属性。CRD定义文件使用KubernetesAPI对象的规范来定义自定义资源的模式、版本和行为。apiVersion:apiextensions.k8s.io/v1kind:CustomResourceDefinitionmetadata: name:mycustomresources.samples.example.comspec: group:samples.example.com versions: -name:v1 served:true storage:true scope:Namespaced names: plural:mycustomresources singular:mycustomresource shortNames: -mcrkube-scheduler调度过程和原理kube-scheduler是Kubernetes集群中的一个核心组件,负责根据预定义的调度策略将Pod分配到集群中的合适节点上运行。下面是kube-scheduler的调度过程和原理的简要描述:获取未调度的Pod:kube-scheduler会定期从KubernetesAPI服务器获取所有未调度的Pod的列表。筛选:kube-scheduler会对未调度的Pod进行筛选,剔除不符合调度要求的Pod。这包括检查系统保留节点、Pod的亲和性和反亲和性要求(如NodeSelector、NodeAffinity等)、污点(Taints)等。只有符合筛选条件的Pod才会进入下一步的调度过程。评分:对于剩下的可调度Pod,kube-scheduler会对每个节点进行评分,根据一系列算法为每个节点计算出一个分数。评分算法可以根据用户自定义的策略进行配置,常见的因素包括节点资源利用率、节点的可用性、亲和性和反亲和性等。选择节点:根据评分结果,kube-scheduler会选择具有最高分数的节点来运行Pod。如果多个节点具有相同的最高分数,kube-scheduler会根据预定义的调度策略(如最少负载、随机选择等)来决定最终的调度结果。更新调度结果:获取到调度结果后,kube-scheduler将更新Pod的调度信息,并将其更新到KubernetesAPI服务器中。这样其他组件(如kubelet)就会根据调度结果来将Pod放置到相应的节点上运行。监控和重调度:kube-scheduler会定期监控已调度的Pod以确保其正常运行。如果发现某个节点不可用或Pod处于非运行状态,kube-scheduler将重新进行调度,将Pod迁移到其他合适的节点上。kubernetes内部需要5套证书,手动创建或者自动生成,分别为:1.etcd内部通信需要一套ca和对应证书。2.etcd与外部通信也要有一套ca和对应证书。3.APIserver间通信需要一套证书。4.apiserver与node间通信需要一套证书。5.node和pod间通信需要一套ca证书。目前来说还不能实现把所有的业务都迁到kubernetes上,如存储,因为这个是有状态应用,出现错误排查很麻烦,所以目前kubernetes主要是运行无状态应用。所以一般而言,负载均衡器运行在kubernetes之外,nginx或者tomcat这种无状态的应用运行于kubernetes集群内部,而数据库如mysql,zabbix,zoopkeeper等有状态的,一般运行于kubernetes外部,通过网络连接,实现kubernetes集群的pod调用这些外部的有状态应用。Kubernetes引入Pod主要基于下面两个目的:-可管理性有些容器天生就是需要紧密联系,一起工作。Pod提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes以Pod为最小单位进行调度、扩展、共享资源、管理生命周期。-通信和资源共享Pod中的所有容器使用同一个网络namespace,即相同的IP地址和Port空间。它们可以直接用localhost通信。同样的,这些容器可以共享存储,当Kubernetes挂载volume到Pod,本质上是将volume挂载到Pod中的每一个容器。
-
跨平台高手必修课--Flutter动态化解决方案实战之手把手带你自研一套Flutter动态热更新框架。Flutter作为跨平台首选框架,未来可期,但动态化问题一直是行业诟病的问题。所以,各大公司都急需一套成熟且高效的动态化解决方案,因此,动态化方面的人才缺口巨大。在本文中,我将带大家从0到1自主研发一套Flutter动态化框架,并深入掌握跨平台动态化解决方案,助力你在跨平台技术上有质的飞跃。一、首先,我们先来认识Flutter:Flutter是Google开源的构建用户界面(UI)工具包,帮助开发者通过一套代码库高效构建多平台精美应用,支持移动、Web、桌面和嵌入式平台。[5]Flutter开源、免费,拥有宽松的开源协议,适合商业项目。Flutter可以方便的加入现有的工程中。在全世界,Flutter正在被越来越多的开发者和组织使用,并且Flutter是完全免费、开源的。它也是构建未来的GoogleFuchsia应用的主要方式。Flutter组件采用现代响应式框架构建,这是从React中获得的灵感,中心思想是用组件(widget)构建你的UI。组件描述了在给定其当前配置和状态时他们显示的样子。当组件状态改变,组件会重构它的描述(description),Flutter会对比之前的描述,以确定底层渲染树从当前状态转换到下一个状态所需要的最小更改。二、Flutter的特点和优势Flutter具有以下特点和优势:跨平台开发:Flutter允许开发人员使用单个代码库构建应用程序,可在多个平台上运行,包括iOS、Android、Web和桌面操作系统。这简化了跨平台开发的流程,减少了开发成本和工作量。响应式UI:Flutter采用响应式编程模型,允许开发人员根据数据的变化自动更新UI。这意味着UI可以根据应用程序状态的变化实时更新,提供流畅的用户体验。热重载(HotReload):Flutter的热重载功能允许开发人员在应用程序运行时快速查看和调试代码更改。开发人员可以实时看到UI的变化,加快了开发周期,提高了开发效率。自绘引擎:Flutter使用Skia图形引擎进行渲染,这意味着应用程序的每个像素都可以通过Flutter进行绘制。这样可以实现高度自定义的UI设计和动画效果,并提供卓越的性能。丰富的UI组件:Flutter提供了一套丰富而强大的UI组件,可以用于构建漂亮和现代化的用户界面。这些组件具有高度的可定制性,使开发人员能够创建独特的应用程序界面。开发效率:Flutter的热重载、响应式UI和丰富的UI组件使开发人员能够更快速地开发应用程序。单个代码库的使用也简化了代码维护和版本控制的过程。社区支持和生态系统:Flutter拥有庞大的开发者社区和活跃的生态系统。开发人员可以从社区中获取大量的资源、插件和解决方案,加快开发进程,并且可以与其他开发者进行交流和合作。良好的性能:由于Flutter使用自绘引擎和硬件加速,应用程序可以实现卓越的性能。Flutter应用程序通常具有快速的响应时间、流畅的动画效果和较低的内存占用。三、Flutter可以用来做什么?Flutter是一个开源的移动应用程序开发框架,它主要用于移动平台的应用程序开发。Flutter具有许多优势,可以用于开发各种类型的应用程序,包括游戏、社交、生产力和移动应用等。以下是Flutter可以用于开发的一些应用程序类型:游戏:Flutter可以用于开发各种类型的游戏,包括桌面游戏、移动游戏和嵌入式游戏。Flutter提供了高性能的虚拟现实开发工具,可以帮助开发者创建逼真的3D游戏和交互式应用程序。社交应用:Flutter可以用于开发社交应用程序,包括WhatsApp和Facebook等平台。Flutter提供了跨平台的开发工具,可以让开发者使用同一代码库开发多个平台的应用程序。生产力应用:Flutter可以用于开发生产力应用程序,例如任务管理应用程序、金融应用程序和调查应用程序等。Flutter提供了可扩展的开发环境,可以让开发者在不同设备上使用同一代码库进行开发。移动应用:Flutter可以用于开发跨平台的移动应用程序,包括iOS和Android等平台。Flutter提供了丰富的组件和库,可以帮助开发者快速构建原生移动应用程序。桌面应用:Flutter可以用于开发桌面应用程序,包括桌面工具、应用程序和游戏等。Flutter提供了丰富的组件和库,可以帮助开发者快速构建原生桌面应用程序。总的来说,Flutter是一个非常强大的框架,可以用于开发各种类型的应用程序,包括游戏、社交、生产力和移动应用等。开发者可以使用Flutter的高性能、可扩展性和跨平台特性,快速构建具有吸引力和可用性的应用程序。四、Flutter安装安装Flutter的过程通常涉及以下几个步骤:1、下载FlutterSDK。访问Flutter官网,选择并下载最新版本的FlutterSDK2、解压FlutterSDK。将下载的FlutterSDK解压到指定的文件夹,例如,在Windows系统中,通常建议将解压后的文件夹放在`C:\Users\你的用户名\flutter`路径下。3、配置环境变量。在系统环境变量中添加FlutterSDK的路径到`PATH`变量中,例如,在Windows系统中,可以在`系统属性`的`环境变量`部分添加`ANDROID_HOME`和`FLUTTER_STORAGE_BASE_URL`等变量,并相应地设置值。4、安装AndroidStudio或VisualStudioCode。如果计划开发Android应用,需要安装AndroidStudio,并确保安装了AndroidSDKCommand-lineTools;如果计划开发iOS应用,可以选择安装VisualStudioCode并安装Flutter插件。5、配置Flutter和Dart插件。在AndroidStudio或VisualStudioCode中,通过设置菜单找到并安装Flutter和Dart插件。6、运行flutterdoctor。在命令行中,运行`flutterdoctor`来检查并解决可能遇到的问题,如缺少必要的依赖项或环境变量设置不正确完成这些步骤后,就可以在Flutter中创建和运行你的第一个项目了
-
如何轻松应对复杂应用的微服务架构设计?如何实现高效的容器化组件管理,快速成为Go高薪工程师?本文将结合经典IM项目,带你深入微服务架构精髓,探究主流微服务框架Go-Zero框架底层运作机制和框架自研之道,让你从分布式系统架构设计、容器化部署管理、高并发性能提升、系统监控等,多维度掌握Go开发高薪技能,助力你快速成为行业急需人才。一、什么是Go-Zerogo-zero是一个集成了各种工程实践的web和rpc框架。通过弹性设计保障了大并发服务端的稳定性,经受了充分的实战检验。go-zero包含极简的AP!定义和生成工具goct,可以根据定义的api文件一键生成Go,i0s,Android,Kotlin,Dart,TypeScript,Javascript代码,并可直接运行。使用go-zero的好处:轻松获得支撑千万日活服务的稳定性·内建级联超时控制、限流、自适应熔断、自适应降载等微服务治理能力,无需配置和额外代码微服务治理中间件可无缝集成到其它现有框架使用极简的API描述,一键生成各端代码自动校验客户端请求参数合法性大量微服务治理和并发工具包二、go-zero框架的特点高性能go-zero采用了高性能的go标准库,整个框架的性能非常高效。同时,在框架中还采用了一些其它优化技术,例如连接池复用等,使得整个框架在性能方面得到了较为优秀的表现。轻量级go-zero框架非常轻量级,它的整个代码量也非常的少。同时,go-zero还采用了很多简洁的语法,使得开发效率更高。异步IO对于一个高性能的微服务框架来说,异步IO是必不可少的。go-zero框架中的异步IO采用了协程的方式调度,使得整个框架的性能得到了大幅提升。中间件支持go-zero框架提供了丰富的中间件支持,包括日志、限流、认证、缓存等,这些中间件可以帮助开发者轻松实现更多的功能。三、go-zero框架的使用在学习任何一款框架之前,你首先需要明确所需的环境和前置条件。对于go-zero框架而言,你需要首先安装Go语言的开发环境,然后使用go命令安装go-zero框架。四、怎么安装golang1.下载Go安装文件首先,需要访问Go官方网站下载Windows版本的Go安装包,可以选择根据操作系统和处理器位数选择相应的版本。下载完成后,打开安装文件进行安装。2.安装Go在安装程序中,需要指定安装目录。建议选择默认的安装路径,以避免因路径问题导致安装失败。在安装过程中,请遵循程序的提示进行操作。安装完成后,检查是否成功安装Go,可以在命令行界面输入命令,如果安装成功,将输出Go版本信息。3.macbrew安装安装目录在/usr/local/opt/go#查看可用go版本brewsearchgo#安装gobrewinstallgobrewinstallgo@<version>#升级brewupdatebrewupgradego配置GOPATHGOPATH是Golang的工作区,它包含了你的源代码、第三方代码包、编译生成的文件等。默认情况下,GOPATH路径为“%USERPROFILE%go”(USERPROFILE为当前用户名)。你可以修改GOPATH路径,建议将GOPATH设置为一个单独的文件夹路径。打开环境变量设置,新增GOPATH变量,将其值设置为你想要的工作区路径,例如“D:gowork”。将此路径添加到环境变量Path中,这样你就可以在所有文件夹下使用go命令了。4.在Linux中安装Golang下载安装包在Linux中安装Golang有多种方式,包括使用包管理器安装、使用二进制文件安装、从源代码编译安装等。这里我们介绍使用包管理器进行安装的方法。首先,更新源列表:sudoapt-getupdate然后,使用以下命令安装Golang:sudoapt-getinstallgolang配置GOPATH同样,在Linux中也需要配置GOPATH。和在Windows中一样,将GOPATH设置为一个单独的文件夹路径。在终端中输入以下命令:echo'exportGOPATH=$HOME/go'>>~/.bashrcecho'exportPATH=$PATH:$GOPATH/bin'>>~/.bashrcsource~/.bashrc以上命令将GOPATH设置为$HOME/go,将$GOPATH/bin添加到PATH环境变量中。五、总结:只需要在生成的代码中填入自己的配置以及逻辑即可,咱们使用go-zero可以轻松做到如下效果:轻松获得支撑千万日活服务的稳定性,内建级联超时控制、限流、自适应熔断、自适应降载等微服务治理能力,无需配置和额外代码,微服务治理中间件可无缝集成到其它现有框架使用,极简的API描述,一键生成各端代码,自动校验客户端请求参数合法性,大量微服务治理和并发工具包。
-
一、什么是pytorchPyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。除了Facebook外,它已经被Twitter、CMU和Salesforce等机构采用。二、为什么使用PyTorch?机器学习研究人员喜欢使用PyTorch。截至2022年2月,PyTorch是PapersWithCode上最常用的深度学习框架,该网站用于跟踪机器学习研究论文及其附带的代码存储库。PyTorch还有GPU加速,使代码运行得更快,你可以专注于操作数据和编写算法。三、PyTorch库的优势通过将模型应用到例证,深度学习允许我们执行很多复杂任务,如机器翻译、玩战略游戏以及在杂乱无章的场景中识别物体等。为了在实践中做到这一点,我们需要灵活且高效的工具,以便能够适用于这些复杂任务,能够在合理的时间内对大量数据进行训练。我们需要已被训练过的模型在输入变量变化的情况下正确执行。接下来看看我们决定使用PyTorch的一些原因。PyTorch很容易被推广,因为它很简单。许多研究人员和实践者发现它易于学习、使用、扩展和调试。它是Python化的,虽然和任何复杂领域一样,它有注意事项和最佳实践示例,但对于以前使用过Python的开发人员来说,使用该库和使用其他Python库一样。更具体地说,在PyTorch中编写深度学习机是很自然的事情。PyTorch为我们提供了一种数据类型,即张量,通常用来存储数字、向量、矩阵和数组。此外,PyTorch还提供了操作它们的函数,我们可以使用这些函数来增量编程。如果我们愿意,还可以进行交互式编程,就像平常使用Python一样。如果你知道NumPy,那么你对交互式编程应是非常熟悉的。PyTorch具备2个特性,使得它与深度学习关联紧密。首先,它使用GPU加速计算,通常比在CPU上执行相同的计算速度快50倍。其次,PyTorch提供了支持通用数学表达式数值优化的工具,该工具用于训练深度学习模型。四、创建数据Tensors张量是一种特殊的数据结构,它和数组还有矩阵十分相似。在Pytorch中,Tensors可以在gpu或其他专用硬件上运行来加速计算之外,其他用法类似Numpy。importtorchimportnumpyasnp#直接从数据创建data=[[1,2],[3,4]]x_data=torch.tensor(data)x_data.shape#全为1x_ones=torch.ones_like(x_data)#retainsthepropertiesofx_dataprint(f"OnesTensor:\n{x_ones}\n")#全为0x_rand=torch.rand_like(x_data,dtype=torch.float)#overridesthedatatypeofx_dataprint(f"RandomTensor:\n{x_rand}\n")#查看tensor类型tensor=torch.rand(3,4)print(f"Shapeoftensor:{tensor.shape}“)print(f"Datatypeoftensor:{tensor.dtype}”)print(f"Devicetensorisstoredon:{tensor.device}")步骤2:自动梯度计算在Pytorch中可以使用tensor进行计算,并最终可以从计算得到的tensor计算损失,并进行梯度信息。在Pytorch中主要关注正向传播的计算即可。#x=torch.ones(2,2,requires_grad=True)x=torch.tensor([[1,2],[3,4]],dtype=float,requires_grad=True)print(x)y=x+2print(y)print(y.grad_fn)#y就多了一个AddBackwardz=y*y*3out=z.mean()print(z)#z多了MulBackwardprint(out)#out多了MeanBackward#计算公式:out=0.25((x+2)*(x+2)*3)out.backward()print(x.grad)步骤3:拟合曲线接下来我们将尝试使用Pytorch拟合一条曲线,我们首先的创建待你和的参数,并加载待训练的数据。#需要计算得到的参数w=torch.ones(1,requires_grad=True)b=torch.ones(1,requires_grad=True)#数据x_tensor=torch.from_numpy(x)y_tensor=torch.from_numpy(y)#目标模型#y=wx+b定义损失defmse(label,pred):diff=label-predreturntorch.sqrt((diff**2).mean())pred=x_tensor*w+bloss=mse(y_tensor,pred)#执行20次参数更新for_inrange(20):#重新定义一下,梯度清空w=w.clone().detach().requires_grad_(True)b=b.clone().detach().requires_grad_(True)#正向传播pred=x_tensor*w+b#计算损失loss=mse(y_tensor,pred)print(loss)#计算梯度loss.backward()五、完整代码(GPU)使用GPU训练只需要把训练数据、模型放入GPU中即可指定是否使用GPU训练模型device=torch.device("cuda:0"iftorch.cuda.is_available()else"cpu")模型放入GPU中model.to(device)数据放入GPU中inputs=torch.from_numpy(x_train).to(device)labels=torch.from_numpy(y_train).to(device)importtorchimporttorch.nnasnnimportnumpyasnpclassLinear_yy(torch.nn.Module): def__init__(self,in_dim,media_dim,out_dim): super(Linear_yy,self).__init__() self.linear_1=torch.nn.Linear(in_dim,media_dim) self.linear_2=torch.nn.Linear(media_dim,out_dim) defforward(self,x): x=self.linear_1(x) x=self.linear_2(x) returnx in_dim=1media_dim=2out_dim=1model=Linear_yy(in_dim=in_dim,media_dim=media_dim,out_dim=out_dim)device=torch.device("cuda:0"iftorch.cuda.is_available()else"cpu")model.to(device)epochs=1000learning_rate=0.0001optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)loss_faction=torch.nn.MSELoss()forepochinrange(epochs): epoch+=1 #注意转行成tensor inputs=torch.from_numpy(x_train).to(device) labels=torch.from_numpy(y_train).to(device) #梯度要清零每一次迭代 optimizer.zero_grad() #前向传播 outputs=model(inputs) #计算损失 loss=loss_faction(outputs,labels) #返向传播 loss.backward() #更新权重参数 optimizer.step() ifepoch%50==0: print('epoch{},loss{}'.format(epoch,loss.item()))


