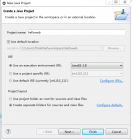
一、selenium2.0简述 与一般的浏览器测试框架(爬虫框架)不同,Selenium2.0实际上由两个部分组成Selenium+webdriver,Selenium负责用户指令的解释(code),webdriver则负责对浏览器进行控制和页面解析。所以使用Selenium2.0时需要相应版本的webdriver和浏览器,程序运行过程中会通过webdriver启动一个真实的浏览器。由于webdriver+浏览器的组合,Selenium不存在对js、ajax解析的问题,它直接使用浏览器对网站代码进行解析获取web代码的执行结果,所以Selenium是最佳的web自动化测试框架,同时也是完美的js/ajax页面爬虫。 二、环境准备 Selenium支持数种语言开发,这里我使用的是java。 1、javaSDK ,最新版即可,编译器使用的是eclipse 2、Selenium ,版本:Selenium-java-3.141(文末附下载) 3、chrome浏览器 ,版本:chrome-75(32位)支持多种浏览器,我习惯chrome(文末附下载) 4 、webdriver ,版本:chromedriver-75(32位)版本很多,需要与浏览器版本对应(文末附下载) 三、安装软件 1、将Selenium-java-3.141解压,找到jar文件 libs目录内还有几个 2、安装chrome 属性查看其安装路径,记住这个安装路径: “C:\Users\ThinkPad\AppData\Local\Google\Chrome\Application\chrome.exe” 3、chromedriver 将下载的chromedriver.exe放到C盘根目录即可 四、测试项目 1、新建一个java项目 Add External JARs,找到刚才Selenium-java-3.141中的jar文件,点击打开将jar文件引入项目 不要忘了libs目录中还有 3、给项目新建一个main class 4、输入下面的测试代码 5、运行 程序会启动一个chrome浏览器并自动进入百度首页,数秒后将输出当前页面代码 五、更多学习资料 至此你已经学会了如何从零开始创建一个webdriver项目,篇幅有限很多内容不能详细写了,不过我们还是准备了更多学习资料, 现在关注公众号“零基础爱学习”回复“SW”获得下面的资料: 1、Selenium-java-3.141 2、chrome-75(32位) 3、chromedriver-75(32位) 4、Selenium常用方法,如:元素定位、浏览器控制等 参考链接:https://blog.csdn.net/qq_22003641/article/details/79137327

 标签: 爬虫
标签: 爬虫