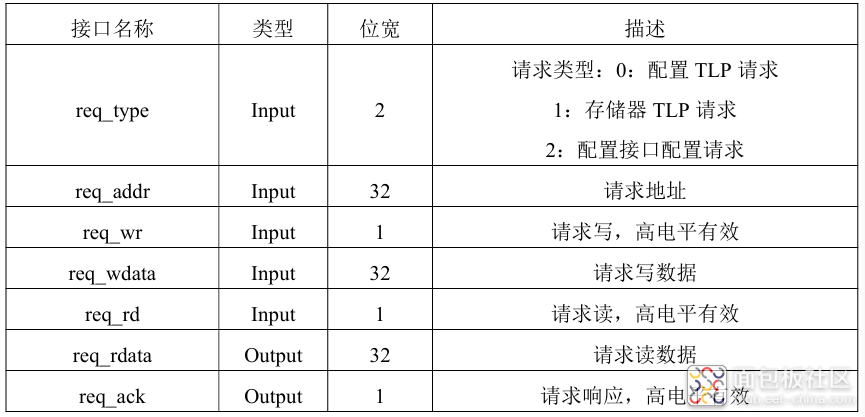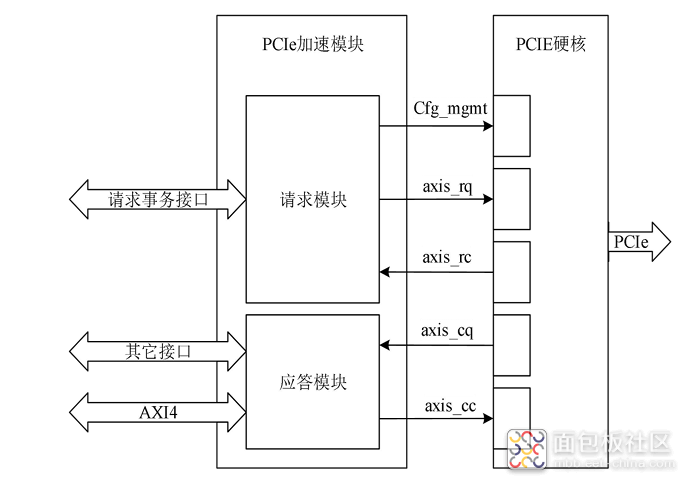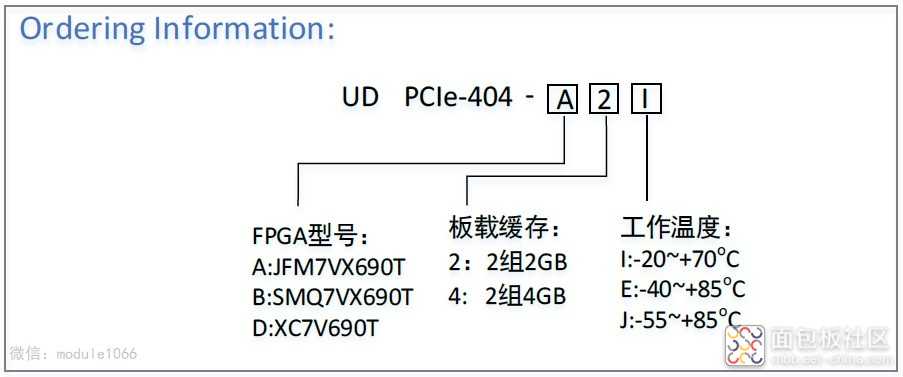
PCIe-404全国产化信号处理模块为标准PCIe全高的结构,对外支持PCIe3.0×8通信,也可以采用千兆以太网(RJ45连接器)、万兆以太网(或RapidIO、Aurora,QSFP+连接器)接口进行通信,支持多板级联,模块为100%国产化设计(同时也兼容进口器件)。FPGA芯片可选JFM7VX690T、SMQ7VX690T、BQR7VX690T,两组DDR3的存储容量分别可配置为2~4GByte。板载有1个FMC+(兼容FMC子板)全互联的接口,满足VITA57.1和VITA57.4规范,可以适配大多数ADC/DAC FMC或FMC+子卡。 应用行业: 无线电监测与测向定位、软件无线电处理平台 通信、卫星、雷达、图像等信号处理 数据采集存储、波形生成与回放 高速接口控制、脉冲处理、测控仪器 高性能计算、万兆或PCIe服务器硬件加速、算法验证平台、Net FPGA 产品特点 : 国产化率100%,与进口器件兼容 FPGA:可选配JFM7VX690T36、SMQ7VX690T、XC7V690T-2I FMC+HPC,24路GTX,LA、HA、HB都全互联,可适配各种FMC AD/DA卡,可适配国内外标准的各种FMC或FMC+子卡 板卡采用QSFP+连接器互联,带宽≥5GB/s 单电源+7.5V~+12V供电,支持插入标准服务器或单独千兆、万兆网口使用 板载GPS/BD模块,也支持IRIG-B码时统输入 使用50A电源对其供电,保证在FPGA全资源使用和高低温下工作稳定可靠 具有输入电压、电流监测功能 具有输入反接、过压、过流、过热保护功能 具有板载温度监测功能,支持2个4线风扇口管理 支持板载扩展FLASH(32kb EEPROM、256Mbit~256Gbit数据存储Flash) 可以支持FPGA多版本动态下载 UD PCIe-404 产品原理框图: 主要技术参数: 产品配置: PCIe3.0x8接口,支持带宽≥5GB/s 2组独立DDR3:64bit位宽,最大速率1600Mb/s,紫光2GB、4GB可选配 GPS/BD定位:中科微电子,带秒脉冲 4路光接口:QSFP+,支持UDP/IP、TCP/IP、RapidIO、Aurora协议,速率≥10.3125Gbps,可用于多板级联 温度监控:贴片GX18B20,可以检测PCB板、环境或散热片温度 电压监控:FPGA自带电压监控功能 LED灯:电源指示灯2颗,状态指示灯10颗 支持外触发、外时钟功能 FMC+接口:兼容FMC规范 对外接口: GPIO口:分2组各8路,共16路,支持3.3V或5V,速率最高40MHz RS232口:2路标准RS232电平,速率最高120Kbps RS422口:1路全双工,速率最高12Mbps,兼容RS485电平,可用于B码 RS485口:2路半双工,速率最高12Mbps,兼容RS422电平 千兆网口:1路,RJ45连接器, 支持10M/100M/1000M BASE-T 万兆网口:4路,QSFP+连接器,支持UDP/TCP协议(可做多卡级联用) 外触发接口:SMA,外接信号经过滞回比较器后再到FPGA,3.3V或5V电平 外时钟接口:两个SMA,外接差分信号直接到时钟分配芯片 外接电源口:直流+7.5V~+12V 输出电源:支持输出(500mA电流)+12V或+5V或+3.3V供外接天线使用 JTAG接口:支持2.0间接双排14芯连接器连接到下载器,有电平驱动和保护 其它特性: PCB板尺寸: 111.15mm ×220mm DC +7.5V~+12V(±5%),功耗15~55W(根据FPGA的频率和使用资源消耗) 工作温度:‐20~+70℃、‐40~+85℃、‐55~+85℃可选 测试程序: FPGA的所有管脚已例化 FPGA读写DDR3的IP、RS232/485/422/GPIO接口回环、PCIe接口识别到卡、获取GX18B20温度、千兆以太网PHY与计算机联通IP、LED跑马灯

 标签: pcie
标签: pcie