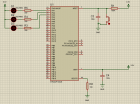
• 实验环境 本次实验是通过Proteus+MDK一起模拟完成的。Proteus模拟实际电路,MDK编译代码。Proteus版本是8.9,MDK版本是5.21。需要注意的是,Proteus需要安装8.8以上版本,器件库里面要支持STM32F103C6。 • 实验目的 通过点亮三个LED,我们俗称的流水灯,来了解STM32的GPIO是怎么配置的。我们实验设置了Systick,即系统滴答时钟,延时也是通过这个滴答时钟来配置的,可以通过这个实验学习一下,怎么配置Systick,以及Systick中断怎么用。 • 主控: STM32F103C6(本来想用C8的,但是Proteus只有C6,本质上只有Flash和SRAM大小的区别,所有没有必要纠结) • 时钟: 没有用外部晶振,因为Proteus只支持一种时钟树,所以这里采用内部晶振,做实验够了。 • 复位电路: 复位电路如图,包含了上电复位电路一个10K电阻(图上用的是100K实际应该都是可以的)+一个100nF电容。按键复位电路,包含了一个自复位按键,按下后,RST管脚就会短路到GND,MCU就会复位。 • IO说明: 我们利用PA1、PA2、PA3来分别控制3个LED灯,输出低电平的时候,LED灯点亮。 • 代码目录概述: APP文件夹:主要包含应用函数的.C文件。 BSP文件夹:主要包含底层硬件驱动的.C文件。 MDK-ARM文件夹:主要包含STM32的启动的.S文件。 StdPeriph_Driver文件夹:主要包含ST官方提供的标准外设驱动.C文件(不是HAL库哦)。 CMSIS文件夹:系统内核配置文件,标准库自带的。 • 代码内容概述: ↓↓↓ GPIO初始化,先打开GPIOA的时钟,然后把PA1、PA2、PA3设置成推挽输出,代码如下: GPIO_InitTypeDef GPIO_InitStructure; RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); GPIO_InitStructure.GPIO_Pin = LED1_Pin | LED2_Pin | LED3_Pin; GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP; GPIO_Init(GPIOA, &GPIO_InitStructure); ↓↓↓ Systick也要初始化,这里滴答时钟设置成1ms进一次中断,代码如下: void bsp_InitSysTick(void) { if (SysTick_Config(SystemCoreClock / 1000)) { /* Capture error */ while (1); } } ↓↓↓这里我们使用的是内部时钟,所以在初始化外设后还要把MCU设置成使用内部时钟,代码如下: void RCC_Configuration(void) { RCC_DeInit(); RCC_HSICmd(ENABLE); while(RCC_GetFlagStatus(RCC_FLAG_HSIRDY) == RESET); RCC_HCLKConfig(RCC_SYSCLK_Div1); RCC_PCLK1Config(RCC_HCLK_Div2); RCC_PCLK2Config(RCC_HCLK_Div1); RCC_ADCCLKConfig(RCC_PCLK2_Div4); RCC_PLLConfig(RCC_PLLSource_HSI_Div2,RCC_PLLMul_10); RCC_PLLCmd(ENABLE); while(RCC_GetFlagStatus(RCC_FLAG_PLLRDY) == RESET); RCC_SYSCLKConfig(RCC_SYSCLKSource_PLLCLK); while(RCC_GetSYSCLKSource() != 0x08); } ↓↓↓ 更详细代码及工程文件,关注回复编号2001就能获取!!

 标签: 入门
标签: 入门

