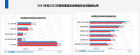
Redis on flash简介:Redis on Flash 涉及到的是Redis的分层存储技术,即将数据存放在不同地方。Redis自2016年以来支持Redis on Flash。从2019年开始, Redis企业版(Redis Enterprise)宣布支持英特尔Optane DC持久性内存,它在DRAM和SSD之间提供了一个新的持久性内存层。 Redis企业版(Redis Enterprise)简介:Redis企业版软件(Redis Enterprise)是企业级的数据库软件,也是一款实时数据平台,为全球超过8500家知名企业提供实时数据服务。具有线性可扩展性、高可用性、持久性、备份和恢复、地理分布、分层内存访问、多租户、安全性等8大核心功能、拥有RediSearch、RedisJSON等7大【Redis企业版特有模块】,可以任何规模在云、本地和混合部署中运行现代应用程序,提供无服务器、多模型的数据库解决方案。Redis企业版的核心优势是采用Redis on flash分层存储技术即【内存+闪存+磁盘】的存储方式,其Active-Active地理分布式架构允许跨地理位置同时进行数据读写操作、拥有亚毫秒延迟和极高吞吐量。 虹科Redis企业版的Redis on Flash (RoF)一直是非常受欢迎的企业功能之一,RoF将高达80%的数据集存储在SSD而不是昂贵的DRAM中,同时还能够保持亚毫秒级延迟和Redis的高吞吐量。在典型部署中,Redis on Flash可提供高达70%的TCO折扣。 目前,两项实践项目证明,Redis on Flash可以提供高达3.7倍的性能,在Redis上运行大型数据集可以保持超高性价比的TCO(总拥有成本): AWS宣布全面推出新一代实例Amazon EC2 I4i,该实例由第三代Intel Xeon可扩展处理器(代号 Ice Lake)和基于AWS Nitro SSD NVMe的存储提供支持。Amazon EC2 I4i承诺将会为Redis客户提供显著提升的功能。 Redis宣布将Redis on Flash数据引擎开放给任何与RocksDB兼容的数据库,并将Speedb宣布的新技术作为首选。 因此,随着公司对低延迟微服务架构的需求增加,AWS的Amazon EC2 I4i实例+ Redis企业版的Redis on Flash数据引擎将会给用户带来超凡的性能体验。 Amazon EC2 I4i和Speedb为Redis on Flash带来了什么? 首先,我们先深入了解一下Redis on Flash的新功能。AWS 正在提供新的 Amazon EC2 I4i(“i”代表 Intel)实例,I4i实例使用最新技术、Intel Ice Lake处理器和AWS Nitro SSD,与上一代I3实例相比,I4i实例提高了读写能力(IOPS)并减少了延迟。 除了硬件之外,Redis企业版一直在寻找能够让RoF提供更高性能的方法。Redis Enterprise发现,如果将数据引擎开放给客户,会帮助企业看到创新机会并提高企业创新速度。目前,Redis企业版的RoF对任何与RocksDB兼容的数据引擎开放。Speedb提供RocksDB存储引擎的嵌入式解决方案,与Redis团队建立战略合作,重新设计了RocksDB的内部数据结构,为大容量实时数据集提供可节省CPU、高性能大规模且降低成本的存储方式。 通过亚毫秒级测试发现,无论我们使用的是I4i还是I3的AWS EC2实例,Speedb都可以将RoF的性能提高50%。带有Speedb的 RoF目前提供预览版本,具体可以联系虹科云科技团队获得更多信息及试用服务。 Redis on Flash的基准测试 1.Redis on Flash的应用场景 基于AWS的I4i实例和Speedb数据引擎,Redis企业版(Redis Enterprise)非常荣幸能够第一个全面测试 Amazon EC2 I4i 实例的 AWS 合作伙伴,并使用Redis on Flash的新Speedb数据引擎对其进行测试 这里想要强调一下,Redis on Flash能够智能的对大型数据集进行分层,其目的是利用比DRAM每GiB价格更低的NVMe SSD,从而使得Redis企业版(Redis Enterprise)能够以DRAM实例30%的TCO(总拥有成本)就可以获得Redis级性能,如果加上AWS的I4i实例将会有更高的性能。 在获得基准测试结果之前,我们可以明确一下客户在何种场景下可以选择RoF: 数据迁移DRAM 成本高昂。如果将小于总数据集进行迁移需要额外的、成本高昂的 DRAM ,那么用户可以考虑Redis企业版的Redis on Flash。 需要批量进行数据处理。如果企业需要为关键业务应用程序处理大量数据,且需要在处理数据的同时保持应用程序的低延迟和高吞吐量,那么用户可以考虑Redis企业版的Redis on Flash。 2.进行基准测试 1)Redis on Flash性能比较 我们在四个 AWS 实例上比较了 Redis on Flash 的性能: i3.8xlarge – 244GB RAM 4xNVMe SSD 驱动器 总计 7.6TB I4i.4xlarge – 128GB RAM 1xNVMe SSD 驱动器 总计 3.75TB I4i.8xlarge – 256GB RAM 2xNVMe SSD 驱动器 总计 7.5TB I4i.16xlarge – 512GB RAM 4xNVMe SSD 驱动器 总共 15TB 2)数据引擎的性能比较 我们比较了两个数据引擎的性能: RocksDB Speedb 测试参数: 我们使用了 1KiB 的值大小,涵盖了大多数标准 Redis 用例 我们测试了 50% 和 85% 的 RAM 命中率(即直接从 RAM 处理的许多请求) 我们测试了 20:80 RAM:Flash 比率 我们对各种读写比率进行了基准测试:1: 1、4:1 和 1:4 所有测试均使用两台服务器完成 以下是我们根据实例类型运行的数据库大小: I4i.4xlarge: 500GB + replication. 5 Primary shards + 5 Replica shards i3.8xlarge: 1TB + replication. 10 Primary shards + 10 Replica shards I4i.8xlarge: 1TB + replication. 10 Primary shards + 10 Replica shards I4i.16xlarge: 2TB + replication. 20 Primary shards + 20 Replica shards 在每种配置中,我们测试了在保持亚毫秒客户端延迟(不包括网络)的同时可以实现多少操作/秒。 3)测试结果 下图显示了 i3 与 I4i 以及 RocksDB 与 Speedb: 我们可以看到以下改进: 下图显示了 Speedb 上 I4i 的缩放比例和不同的读写比率: 我们可以看到以下结果和改进: 智能缩放,我们可以看到I4i上的RoF与Speedb几乎是线性缩放的。 4xlarge → 8xlarge 的因子为 ~1.55x-1.8x 8xlarge → 16xlarge 的缩放因子为 ~1.85x-1.95x 第二个值得注意的结果是I4i上的 RoF与Speedb对应用程序访问模式(读:写比率)非常不可知,这意味着性能保持稳定且可预测。当使用多个不同的应用程序或访问模式随时间变化时,这对用户而言可能有极大的用处。 下图显示了Redis on Flash整体3.7 倍的性能提升(吞吐量操作/秒):



 标签: 缓存
标签: 缓存