
回答问题之前先来看看什么是压缩。当你有天走在路上,碰见熟人对你说:“吃了?”你一定知道他是在打招呼,既不是要请客也不是让你“没吃赶紧回家吃去”。这一句简单的“吃了”是礼貌和问好的体现,也是一种信息的压缩。笼统地说,把一系列已有信息通过一定 方法处理,使得其长度缩短,并且信息含量基本或者完全不变,就称之为压缩。
我们都知道,计算机采用的是2进制系统。一个连续的n位二进制数集,就可以用来表示 2 n 个字符。目前的国际标准是ASCII码:用一个字节即8位数的2进制码,来表示各种字符和字母。
现在我们只使用2位二进制码,来简单地演示由4个符号组成的字符串的压缩过程。
假设我们有这么一串20个字母的数据:
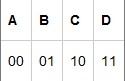
默认情况下,用2位2进制码来表示这四个字母:
每个字符在字符串种各自出现的次数并不相等:
A:6次 B:10次 C:3次 D:1次
而在计算机中,数据则是以2进制码的形式储存在硬盘上的:
00 00 01 00 00 01 01 10 01 00 01 01 01 10 01 01 00 01 11 10
压缩过程如下:
①注明每个字符的出现次数。把两个出现次数最小的字符圈到一起,看作一个新字符,新字符的次数为两个组成字符的次数之和。
②重复上述操作,直至完成对所有字符的处理。这种操作形成的结构看起来像棵树(下图),被称为——霍夫曼(Huffman)树。
③在每一层的分支线上,按下图所示分别标上0和1。
从最顶端往下读,每个字符都有唯一的分支编号连到它那里,无重复也无遗漏,这样就得到了ABCD这四个字符的新的代码:
用以上新编码代入原字符串中,得到:
10 10 0 10 10 0 0 110 0 10 0 0 0 110 0 0 10 0 111 110
整理一下得到新编码:
原编码:0000010000010110010001010110010100011110
新编码:1010010100011001000011000100111110
看!数据成功被压缩。这一段40位长度的内容被压缩到了34位,压缩率是85%。
回顾过程容易发现压缩的秘密:出现频率最多的"B"由一位二进制码“0”来表示,而出现频率较低的"C"和"D",则由长度增加了的三位二进制码来表示。通过合理分配不同长度的编码,肯定可以对数据进行一定程度的压缩。
另外可以证明,霍夫曼树就是此类编码替代的最优化的方案之一。因为假如存在一个字符的出现频率高于另一个字符,而它的变长码长度却长于另一个字符, 那么必然可以通过交换两者的位置,使得输出结果的总长度变短。有限次操作后可以达到无法再交换的情况,也就是霍夫曼树规则下的情况。
进一步思考几个问题
在压缩文件的时候,人们不禁会产生一些新想法或者遇到一些疑问:是否可以对压缩后的数据再次压缩?当2 n 的n变大后,遇到A:1010,B:10这样的情况,如何解读10101010?
就操作上来说,当然能反复编码,但通过对本文例子中得到的新编码再次操作后会发现,结果是不会有任何变化的。压缩的实质,在于消除特定字符分布上的 不均衡,通过将短码分配给高频字符,而长码对应低频字符实现长度上的优化。而数据经过一次压缩后,字符的分布已经几乎平均化了,很难更进一步的压缩了。
而第二个问题描述的情况是不会出现的的。从构造霍夫曼树操作上可以看到,一个字符无法在另一个字符的上层。只要操作正确,就一定可以构造出唯一的代码表,不存在歧义。
还有一个有趣的问题是:虽然把40字节的内容压缩到了34字节,但需要将相应的码表一并发送给接收方(没有对应码表,无法解压)。这不反而使得压缩后的数据比压缩前的还要长?
事实也确实如此。本文例子中,真正的最终结果体积是大于原文的。但这不意味了算法错误。这是因为“n”过小(例子中为2,实际通常为8)导致的。
总长度的不够使得节省出来的那部分容量还不足以弥补码表本身的储存空间。实际应用中,如果你非要去压缩一个只有几个字节的文件,得到的压缩包也经常 会大于文件本身。通常,压缩软件会在每压缩4kb到32kb数据后,重新生成并保存一个霍夫曼树。当分块过大时,统计上的整体平均,会掩盖小区域内的极度 不平均,损失了压缩的空间。比如存在一个这样的文件:
AAAAA……AAAAA(一万个)BBBBB……BBBBB(一万个)……ZZZZ(一万个)。
如果从整体上进行霍夫曼树操作,将不会产生任何压缩,但是这时候我们把它分成26块,压缩并各自保存相应的重新编码的霍夫曼树,压缩率将非常惊人,约等于12.5%。
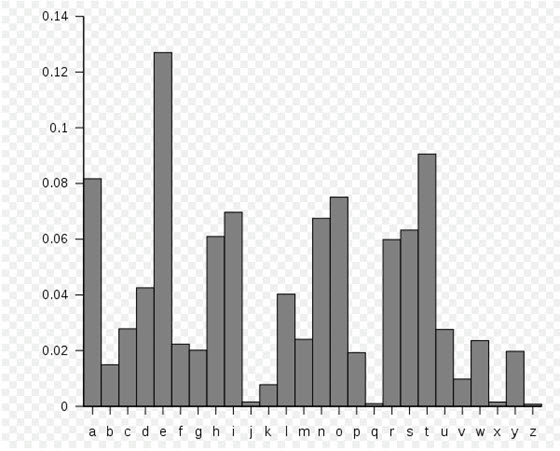
英语中各字母出现频率示意图
从上面字频图我们知道,在现实的文本中,英语字母使用频率各不相同,而且差别很大。有着很高的不平均度。所以大部分压缩软件对文本文件依然有着很高的压缩率。(文/果壳网)





 /3
/3 






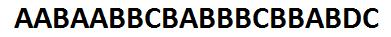{kind=link}
文章评论(0条评论)
登录后参与讨论