
加法器
使用环境:Quartus II 8.0 + DE2(Cyclone II EP2C35F627C6)
1、半加器:
代码:
module half_adder(ina,inb,sum_out,carry_out,clk,rst);
input ina;
input inb;
input clk;
input rst;
output sum_out;
output carry_out;
reg sum_out;
reg carry_out;
always @(posedge clk or negedge rst)
begin
if(!rst)
begin
sum_out <= 1'b0;
carry_out <= 1'b0;
end
else
begin
sum_out <= ina^inb;
carry_out <= ina&inb;
end
end
endmodule
综合后的RTL视图:
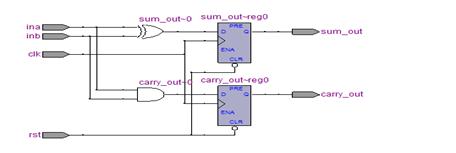
仿真波形图:
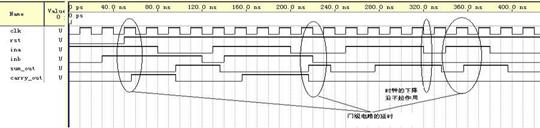
小结:半加器最后输出经过了一级D触发器。注意:组合电路要考虑门电路的传输延迟时间,以及由此引起的竞争。
我们把门电路两个输入信号同时向相反的逻辑电平跳变(一个从1变为0,另一个从0变为1)的现象叫做竞争。消除竞争—冒险现象的方法有
a、接入滤波电容。b、引入选通脉冲。 c、修改逻辑设计
2、全加器
全加器和半加器的区别在于全家器多了一个进位输入端。
组合逻辑代码:
module full_adder(ina,inb,carry_in,sum_out,carry_out);
input ina;
input inb;
input carry_in;
output sum_out;
output carry_out;
//combinational logic
assign sum_out = (ina^inb)^carry_in;
assign carry_out = (ina&inb)|((ina^inb)&carry_in);
endmodule
综合后的RTL视图:

时序逻辑实现代码:
module half_adder(ina,inb,carry_in,sum_out,carry_out,clk,rst);
input ina;
input inb;
input carry_in;
input clk;
input rst;
output sum_out;
output carry_out;
reg sum_out;
reg carry_out;
//second method: sequential logic
always @(posedge clk or negedge rst)
begin
if(!rst)
begin
sum_out <= 1'b0;
carry_out <= 1'b0;
end
else
begin
sum_out <= (ina^inb)^carry_in;
carry_out <= (ina&inb)|((ina^inb)&carry_in);
end
end
endmodule
综合后的RTL视图:
??
3 行波进位加法器(串行进位加法器)
源代码:
module ripple_adder4b(ina,inb,sum_out);
parameter ADDER_WIDTH = 4;
parameter SUM_WIDTH = 5;
input [ADDER_WIDTH-1:0] ina;
input [ADDER_WIDTH-1:0] inb;
output [SUM_WIDTH -1:0] sum_out;
wire [ADDER_WIDTH-1:0] carry_out;
full_adder u1 (ina[0],inb[0],1'b0,sum_out[0],carry_out[0]);
full_adder u2 (ina[1],inb[1],carry_out[0],sum_out[1],carry_out[1]);
full_adder u3 (ina[2],inb[2],carry_out[1],sum_out[2],carry_out[2]);
full_adder u4 (ina[3],inb[3],carry_out[2],sum_out[3],carry_out[3]);
assign sum_out[4] = carry_out[3];
endmodule
综合后的RTL视图

行波进位加法器串行进位链的总延时时间与字长成正比,字长越长,延时时间就越长。在用可编程逻辑器件实现这种加法器时会设置专门的进位链,也能达到较高的性能,通常称为快速行波进位加法器。
4位超前进位加法器
源代码:
module fast_adder4b(ina,inb,carry_in,sum_out,clk,rst_n);
parameter ADDER_WIDTH = 4;
parameter SUM_WIDTH = 5;
input [ADDER_WIDTH-1:0] ina;
input [ADDER_WIDTH-1:0] inb;
input carry_in;
input rst_n;
input clk;
output [SUM_WIDTH -1:0] sum_out;
reg [SUM_WIDTH -1:0] sum_out;
wire [ADDER_WIDTH-1:0] sg;
wire [ADDER_WIDTH-1:0] sp;
wire [ADDER_WIDTH-1:0] sc;
assign sg[0]=ina[0]&inb[0];
assign sg[1]=ina[1]&inb[1];
assign sg[2]=ina[2]&inb[2];
assign sg[3]=ina[3]&inb[3];
assign sp[0]=ina[0]^inb[0];
assign sp[1]=ina[1]^inb[1];
assign sp[2]=ina[2]^inb[2];
assign sp[3]=ina[3]^inb[3];
assign sc[0]= sg[0]|(sp[0] & carry_in); //超前进位逻辑
assign sc[1]= sg[1]|(sp[1] & (sg[0] | (sp[0] & carry_in)));
assign sc[2]= sg[2]|(sp[2] & (sg[1] | (sp[1] & (sg[0] | (sp[0] & carry_in)))));
assign sc[3]= sg[3]|(sp[3] & (sg[2] | (sp[2] & (sg[1] | (sp[1] & (sg[0] | (sp[0] & carry_in)))))));
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
sum_out <= 5'b00000;
else
begin
sum_out[0] <= sp[0] ^ carry_in; //求和逻辑
sum_out[1] <= sp[1] ^ sc[0];
sum_out[2] <= sp[2] ^ sc[1];
sum_out[3] <= sp[3] ^ sc[2];
sum_out[4] <= sc[3];
end
end
endmodule
综合后的RTL视图:

8流水结构加法器
我们对一个8bit的加法器采用两个4bit的加法器,采用两级流水结构实现。
源代码:
module pipe_adder8b(ina,inb,sum_out,clk,rst_n);
parameter ADDER_WIDTH = 8;
parameter SUM_WIDTH = 9;
parameter HALF_ADDER_WIDTH = 4;
input [ADDER_WIDTH-1:0] ina;
input [ADDER_WIDTH-1:0] inb;
input rst_n;
input clk;
output [SUM_WIDTH -1:0] sum_out;
reg [SUM_WIDTH -1:0] sum_out;
reg [HALF_ADDER_WIDTH-1:0] ina_lsb;
reg [HALF_ADDER_WIDTH-1:0] ina_msb;
reg [HALF_ADDER_WIDTH-1:0] inb_lsb;
reg [HALF_ADDER_WIDTH-1:0] inb_msb;
reg [HALF_ADDER_WIDTH-1:0] ina_msb1;
reg [HALF_ADDER_WIDTH-1:0] inb_msb1;
reg [HALF_ADDER_WIDTH:0] sum11;
wire [HALF_ADDER_WIDTH:0] sum1;
wire [HALF_ADDER_WIDTH:0] sum2;
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
ina_lsb <= 4'b0000;
ina_msb <= 4'b0000;
inb_lsb <= 4'b0000;
inb_msb <= 4'b0000;
end
else
begin
ina_lsb <= ina[3:0];
ina_msb <= ina[7:4];
inb_lsb <= inb[3:0];
inb_msb <= inb[7:4];
end
end
fast_adder4b u1 (ina_lsb,inb_lsb,1'b0,sum1,clk,rst_n);
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
ina_msb1 <= 4'b0000;
inb_msb1 <= 4'b0000;
end
else
begin
ina_msb1 <= ina_msb;
inb_msb1 <= inb_msb;
end
end
fast_adder4b u2 (ina_msb1,inb_msb1,sum1[4],sum2,clk,rst_n);
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
sum11 <= 4'b0000;
else
sum11 <= sum1;
end
always @(posedge clk or negedge rst_n)
begin
if(!rst_n)
sum_out <= 9'b0000_00000;
else
sum_out <= {sum2,sum11[3:0]};
end
endmodule
综合后的RTL视图:

时序仿真图:





 /1
/1 







文章评论(0条评论)
登录后参与讨论