- 本文首发于我个人的知乎专栏,眼见面包板专栏万年未更新了,把这篇文章转载过来 -
不知各位同学是否了解,很多大型科技公司,除了做要直接在市场上卖的产品,另外也搞前沿技术研究——虽然这个前沿还没有前瞻到与量产产品完全不相干的程度,但也算是一种近未来的技术投资。
比如之前我写过好些 Intel 在半导体制造方面的前瞻技术——其中的很多尚未真正走出实验室、成功量产。作为芯片、AI 领域的大热门,英伟达也有这样一个专门的团队或机构,名为 NVIDIA Research。出自 NVIDIA Research,最终走向产品化的东西典型如 OptiX、光线追踪算法和硬件、Volta 的 SM 架构、自动化 VLSI floorplan 工具、视频 Super Slow Motion、DLSS 和 DLAA 等等...
前不久英伟达 GTC 活动上,我也是第一次有机会听到英伟达首席科学家 Bill Dally 去谈 NVIDIA Research。虽然其实总体的干货也不算多,但起码是了解他们究竟在做什么的好机会,多少也算是增长见识吧;而且机会的确是很难得。
很遗憾的是,主题演讲的 PPT 不能对外分享~所以我只能极尽所能地把我听到的东西,用文字记录下来。国内应该算是独此一家吧(独此一人?很嚣张)...另外因为是前瞻技术,有错误的地方请轻拍;毕竟人家是前沿技术专家,我肯定无法做到什么都懂...

GTC 2024 现场堪称接踵摩肩
承载 30 倍性能提升的 NVLink在正式谈 NVIDIA Research 以前,先简单说两句 Blackwell GPU(不想看这个的,可以直接跳过这个小标题下的一整段)。这次 GTC 活动,最火的应该是 Blackwell GPU 芯片,及其构成的 B200、GB200、GB200 NVL72 等系统。这里面有道有趣的数学题。
其实在面向媒体的 pre-briefing 上,英伟达就提到了相比于前代 Hopper 架构 GPU 的 30 倍性能提升。不过这个 30 倍究竟是怎么来的呢?即便是加速器,芯片隔代 30 倍性能提升,这事儿别说摩尔定律不答应,先进封装不答应,苹果也不答应啊...

GB200 NVL72
我在当时的报道文章里写了,Blackwell GPU 本身作为一颗芯片,考虑第二代 Transformer 引擎,以及两颗几乎达到 reticle-limit 光刻机限制尺寸的 chiplet,芯片层面的推理性能提升 5 倍,听起来是很合理的。
但是,到了系统层面,尤其是构成 GB200-NVL72 系统,也就是那个总共包含 72 颗 Blackwell GPU,及 36 颗 Grace CPU 的一整台设备,还有 NVSwitch 交换芯片的交换机,30 倍的推理性能提升就有意义了。那么芯片层面 5 倍性能提升,究竟是怎么在系统层面就做到 30 倍提升的呢?
其实黄仁勋在主题演讲中有给出下面这张 PPT:
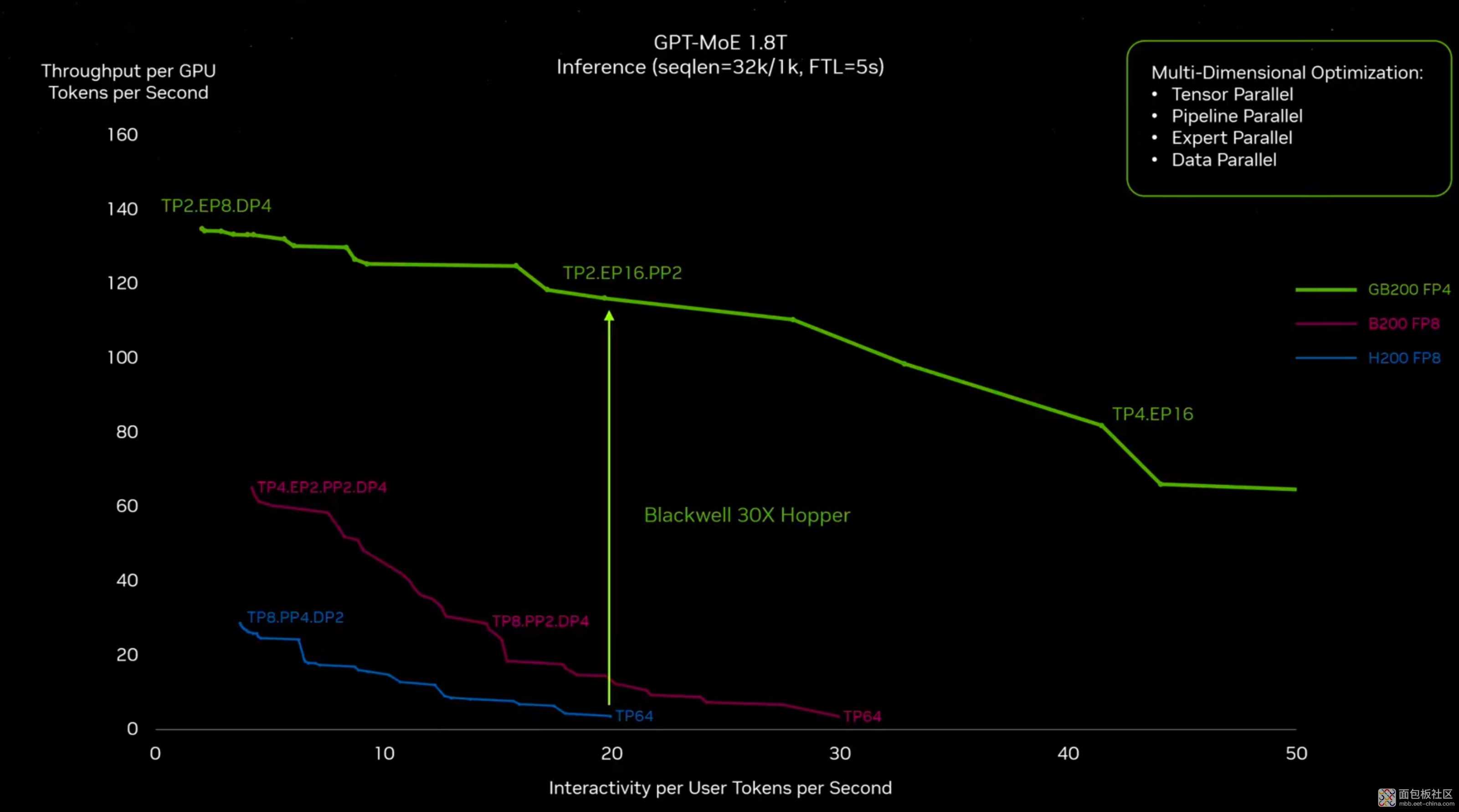
这张折线图咋看呢?首先整个图表达的是 1.8 万亿参数的 GPT 模型推理。横坐标代表的是模型的可交互性,可以理解为 AI 模型和每个用户对话时,AI 模型的打字速度;纵坐标可以理解为数据中心的吞吐。我们总是期望这两个值越高越好。
基于不同的优化,包括数据并行、tensor 并行、管线并行等等相关优化和配置,找到它们在坐标轴中的不同位置——基于不同的配置、软件分布,也就有了不同的 run time。(如图中 TP2 EP8 DP4 代表跨 2 颗 GPU 做 tensor 并行,8 颗 GPU 做 expert 并行, 4 颗 GPU 做数据并行)
图中的蓝线表示的是 Hopper 架构的 H200 构成的相同 GPU 数量的系统(从 pre-briefing 给的资料来看,应该也是总共 72 颗 GPU,或者相似数量)在推理时的情况。
而绿线表示的就是 GB200-NVL72,它相较蓝线的提升就有 30 倍。这里比较有趣的其实是中间那根紫线,它表示的是啥呢?就是如果不改变 Hopper 基础架构,只是单纯把这个上代架构的芯片做大,以及两片 die 封装在一起,则它也能带来提升,只不过提升是相对有限的。也就是说光扩大 GPU 芯片的规模,成效并不显著。
这里黄仁勋的原话是“如果我们不改变 Hopper 架构,仅是造更大的芯片,用上 10TB/s 的片间互联,得到 2080 亿晶体管的巨大芯片”。这句话可能透露了 Blackwell 在处理器架构层面,相比上代 Hopper 的变动并不大:芯片层面着眼的主要应该就是 GPU 规模增大,以及增加先进封装(所以 PPT 上标注的紫线是 B200)。
那么 30 倍性能提升主要来自哪儿呢?毫无疑问,包括 Transformer 引擎对于 FP4 的支持,以及更重要的最新一代的 NVLink——不光是带宽 1.8TB/s(似乎高了 10+ 倍?),还有 SHARPv4 什么的。
而且我猜,对比的这张图里,看到的 H200 构成的系统,应该是更加传统的搭配了 x86,以及 PCIe 连接的方案。那么换用英伟达自己的 Grace CPU,搭配与 Blackwell GPU 之间的高速连接,处理器之间通信效率的显著提升,30 倍也就合情合理了。
其实 GTC 期间面向分析师有个 AI Architecture 的 Q&A 活动,我就一直在尝试举手想问问这个 30 倍性能提升是不是主要来自 NVLink,也就跨芯片通信方面的提升和优势,无奈一直没有被轮到。

一片 Grace CPU + 两片 Blackwell GPU
不过实际上英伟达的相关负责人在不同场合也做了一些解读,尤其是 Ian Buck(Hyperscale & HPC副总裁)在两场分析师 Q&A 会上明确提到了新一代 NVLink 是期望构建起更大的“NVLink domain”,我的理解就是一个高速互联的域内,容纳更多全连接(all-to-all)的 GPU(应该是 576 个),以适配现在的多模态、多 MoE 模型需求,像 GPT-4 这样的~
换句话说,GB200-NVL72 作为一个系统,其实是这次英伟达推的重点。而且这也印证了,这个时代远不是靠摩尔定律就能支撑向前的了,甚至 more than Moore 也不行(你看不是用了先进封装么),系统层面的改良和优化也必须上才行......EDA、Foundry 厂普遍也都在倡导这样的观念~
回过头来说 NVIDIA Research。上面说这一大堆的,和 NVIDIA Research 有啥关系呢?
NVIDIA Research 在干啥?其实 NVLink, NVSwitch 这类东西,都是出自 NVIDIA Research,而且是归总到“networks”这个大类中的。据 Bill Dally 所说,2011 年的时候,他去找老黄聊了聊要面向 HPC 开发 networking 技术的问题,老黄问他:“我们为什么要做 networking?我们不是一家开发 GPU 的公司吗。”不过最终黄仁勋还是做出了支持,而且是资金上 100% 的支持。
感觉就我们所处的这个时代,尤其近两年听英伟达在数据中心 GPU 方面的投入,数据交换和互联也算得上是英伟达的核心技术要素之一了。但在当年,这件事却并不是理所应当的。是不是还挺惊讶于时代变迁的?现在有实力的芯片厂商们,普通从系统层面入手,也显得很有道理——不知道未来游戏显卡会不会也变这样...
从大方向来看,NVIDIA Research 切分成了供给侧(Supply)和需求侧(Demand)。供给侧这边的技术是直接为 GPU 服务的,包括存储系统、编程系统、网络(networks)、架构、VLSI、电路什么的。需求侧则是指针对 GPU 的需求,包括几个图形技术相关的团队,几个 AI 团队,还有一些垂直业务方向,包括机器人、自动驾驶汽车、气候模拟等。
对英伟达现有业务熟悉的同学,应该很清楚图形、AI,以及上面提到的垂直领域小组研究,是非常清晰地反映到了英伟达现在发布的产品中的。

除了这些以外,NVIDIA Research 似乎还包含了两个机动小组。比如一个团队做所谓的“Moonshots”,当然肯定不是说的登月,据说 Volta 架构就是来自这里;还有个例子是光线追踪核心,也就是图形卡上的 RT core——当时从架构和图形团队找来了一群人,就开始讨论说怎么才能做实时光追。
研究之下就有了 TTU(tree traversal unit)树遍历单元,也就是用来做 BVH 遍历和三角形与光线相交测试加速的,“产品团队的人觉得这很好,它就变成了 RT core,用到了 Turing 这一代产品上。”Bill 说。
除了 Moonshots,另有一个“Study Group”小组,研究的东西更具未来向。比如说量子模拟相关的研究,最初是 2017, 2018 年前后有人提出了其发展潜力,甚至“替代 GPU”,随后成立量子研究小组。“然后我就从 NVIDIA Research 团队找了一帮物理学方向的 PhD,大概 10 个人,一起去研究量子技术发展到哪儿了,我们能做到怎样的参与度,将来会怎么发展。我们还写了一份很不错的报告呈交给了董事会。”
“我们当时发现,这项研究要投入商用,真正对财务产生正向影响,还比较遥远。”Bill谈到,“现在其实也还是这样。但这对人们来说是个巨大的市场”,“模拟量子计算机是个巨大的市场,我们就开发了构建相关软件的策略,也就是现在 CuQuantum。”“我们实际是为那些淘金者(指正在搞量子计算研究的那波人)提供工具。现在这其实也是个很成功的业务了。”
有关 NVIDIA Research 本身还有一点值得一提,Bill 在开场的时候特意强调了他们衡量自己的工作成绩,绝对不是发表 paper 的多少。“公关(PR)可能对这类事情比较热衷,但我们还是希望真正对技术产生影响。”在 Bill 看来,同类科技企业的前沿科学研究团队存在两种典型的错误,其一是发一堆 paper,看起来是很成功的研究实验室,团队内部有来自不同领域的人才。“但这种团队和公司是脱节的,对公司而言根本不发挥什么作用。”
还有一种错误是“内部的项目都是由产品团队给予的资金支持”,这决定了“他们距离实际产品并不会很远”,“这些人在做的实际上就是产品开发,而不是研究。”而 NVIDIA Research 期望做到的,一方面是要拉远和产品之间的距离,另一方面也要对公司切实地产生影响。换句话说就是找寻两者间的平衡点。
所以 NVIDIA Research 有三条原则。我理解第一点是投资回报的合理性(这一条尚不能确定,现场没有听得很清楚);其二是研究需要对产品产生影响,“我们也写很多 paper,平均到人头,和其他任何研究实验室的产量一样多。但这不是我们的目标。目标还是要影响英伟达的产品”;
其三是要产品团队的人加入到研究项目中来。“我们以前将一项研究搞定,发表 paper,然后跟产品团队的人去聊。这时候就发现已经太晚了。如果我们真的要影响产品,还是需要他们在研究项目启动的第一天就加入进来。因为我们需要理解他们(产品开发)存在哪些限制,他们需要给产品加入些什么,以及还有兼容性相关的很多问题。”

谈两个技术转化,RTX 与 CuDNN其实应该谈来自 NVIDIA Research 3 个典型的技术成果转化的,还有一个是 NVSwitch,文章第一部分已经先说了。所以这部分就谈另外俩 Bill 特别提到的技术转化吧,即 RTX 和 CuDNN。
就英伟达的市场宣传,RTX 我个人理解应该是一系列技术的集合。不过一般人将其定义窄化到了光线追踪,毕竟什么 GeForce RTX 2080 这类产品名称,最先强调的不就是光线追踪特性么。
Bill 说光线追踪的源起是一个小团队(好像原本是一家独立的公司),当时这个团队的负责人在开发能够在 GPU 上跑光线追踪的软件。英伟达发现以后就把这公司给收了,然后很快把负责人拉到了 Research 团队。软件成果最终是转化成了 OptiX 的,而且“重构(re-form)了我们的专业图形核心”。
“几年以后,我们纠集了一批光线追踪的专家。我们需要在当下去理解什么是好的光线追踪渲染。”即要把实时光追做到何种程度(听到似乎项目名称叫 100x Ray Tracing),“究竟该怎么做?我们最终发现需要几样不同的东西,首先就是转化成了 RT core 的 TTU(树遍历单元)”,“另外我们也增加了光线三角形相交单元”。
“但其实这还不够,可能让我们做到了 10x 吧。我们还是需要其他东西。所以接下来我们就决定,需要一种超采样技术,现在就叫 DLSS,只需要对低分辨率做光线追踪即可,超分以后得到 4 倍像素。”“不过我们真正需要的关键一环,现在是真的做到了”,“此前随 Turing 架构一起到来的 RT core 还是用于特效的(was used for effects),包括反射、阴影之类的东西。它还不是完整实时的 path trace(路径追踪)。
“《赛博朋克 2077》是首个完全路径追踪的 3A 游戏。如果你们没见过的话,真的应该去看一下,效果非常好。”相信关注 PC 和游戏的同学,对这部分应该如数家珍了。不过这里传递的一点是,RT core, DLSS, path trace 其实是来自 NVIDIA Research 的组合拳。
“最终,真正把我们带到那儿的,还是对于 Importance Sampling 这种方法的理解。如果一个场景内有百万条光线,你是不可能对每条光线做投射的。所以你需要决策对哪些做采样。”“我们做出了一种名为 ReSTIR 的新算法,最后以 RTXDI 技术名称落地,真正以高效的方式对光线的采样,投射更少的光线就能达成很高的画质。”
“RT core,超采样(DLSS),以及有效的 Importance Sampiling,才让我们真正做到了 100x,真正做到了游戏中的实时光追。”

说完光追,再来谈 CuDNN,也就是 CUDA Deep Neural Network,当然就是用来做深度神经网络加速的库。了解 AI 的同学应该不陌生。Bill 说 2010 年前后,他跟一名同事一起吃早饭,当时就提到在互联网上找(识别)猫的事情。那个时候还需要 16000 颗 CPU 来做这件事。
“我就说 CPU 不行啊,我们应该让这样的东西跑在 GPU 上。”Bill 说道,“当时我们团队内的一名编程系统研究员也鼓励我这么做。最后出来的软件就是 CuDNN。”“其实这比 AlexNet 还早了 2 年。”“我们当时就意识到 AI 会是个影响深远的东西。我们就真的开始着手构建软件栈了。”
“那个时间点放在 Kepler 架构上已经有点太晚了,所以我们着眼的是 Pascal、Maxwell,加入了一些特性;真正严肃对待是在 Volta 这一代上;到 Ada 平台,就是我们期望看到的了。”看看这个演进,要不怎么说英伟达现在股价的高涨不是一朝一夕之功呢。
再谈几个有趣的技术:硅光、用 AI 设计芯片、AIPC
上面这些其实还是更为普罗大众所知的东西,Bill 当天谈了 NVIDIA Research 旗下各小组的一些研究。受限于篇幅,无法一一介绍。这里给一些我个人觉得还挺有趣的技术研究。
首先聊聊电路方面的研究吧:因为我见识浅薄,之前一直以为 fabless 企业是不需要把投入放在半导体的电路层面的。不过 NVIDIA Research 还真是有个 Circuit Research 的团队,“让我们的 GPU 更好”。
比如说 short reach links(短距离连接)——很遗憾无法给你们看图,Grace Hopper 整颗芯片上,连接 Grace CPU 和 Hopper GPU 的就是这个 short reach links,也包括 HBM 内存连接。目前基于 TSV 做 die 堆叠的方案,已经实现了 0.1-0.5mm 距离内 0.1pJ/bit 的能耗水平。
这次新发布的 Blackwell,连接两片 die 的技术名称完全没听清(好像是 ISNRP,Incredibly Short Reach NP),能耗量级是 1-2mm 0.2pJ/bit。基于先进封装的片内通信能耗,和要走 PCIe 5 这种通道互联的量级差异起码有 20 倍以上。
Grace Hopper 和 Grace Blackwell 的 CPU 到 GPU 通信连接是多年前就完成的,能耗量级 10-15mm 1pJ/bit——这应该是一种走基板的通信了,虽然和 Blackwell 片内两片 die 互联不能比,但还是比 PCIe 5 要节能了 5 倍以上。
所以实际上,英伟达常年来也坚持给自家芯片的互联命名,还是有道理的。似乎这种事,在 fabless 企业内也只有英伟达、苹果这类企业做得到,互联的某些层级还是有自家的标准和技术在里头的。组成自有成套、成规模的生态就是任性啊...
还有 long reach links(长距离连接)——至少是芯片与芯片间(封装与封装之间)的传输了,这部分据说英伟达在考虑光通信(photonics),只不过现在成本和功耗都还不理想。但 Bill 认为让硅光成本降下来,降到可比肩铜(电传输)的程度还是有戏的,毕竟“铜差不多发展到头了”。
“目前我们正在努力去尝试波分复用(dense wavelength division multiplexing)技术”,“在传输芯片里用锥形激光源”,“对不同色光做调制,以每种色光较低的 bit 率做密集波分”,“达到每根 fiber 最高 TeraBits 带宽”;“接收端的芯片也有个环形谐振器(ring resonator),对色光做检测。”(这一段如果有描述错误的轻拍啊,我已经尽力把我听到的做我能理解的还原了)
“这些现在已经在我们实验室里了,只不过还没准备好量产。”“不过我们有信心,最终可以把能耗降到 2pJ/bit 的量级,能耗和成本都能比肩电传输。”
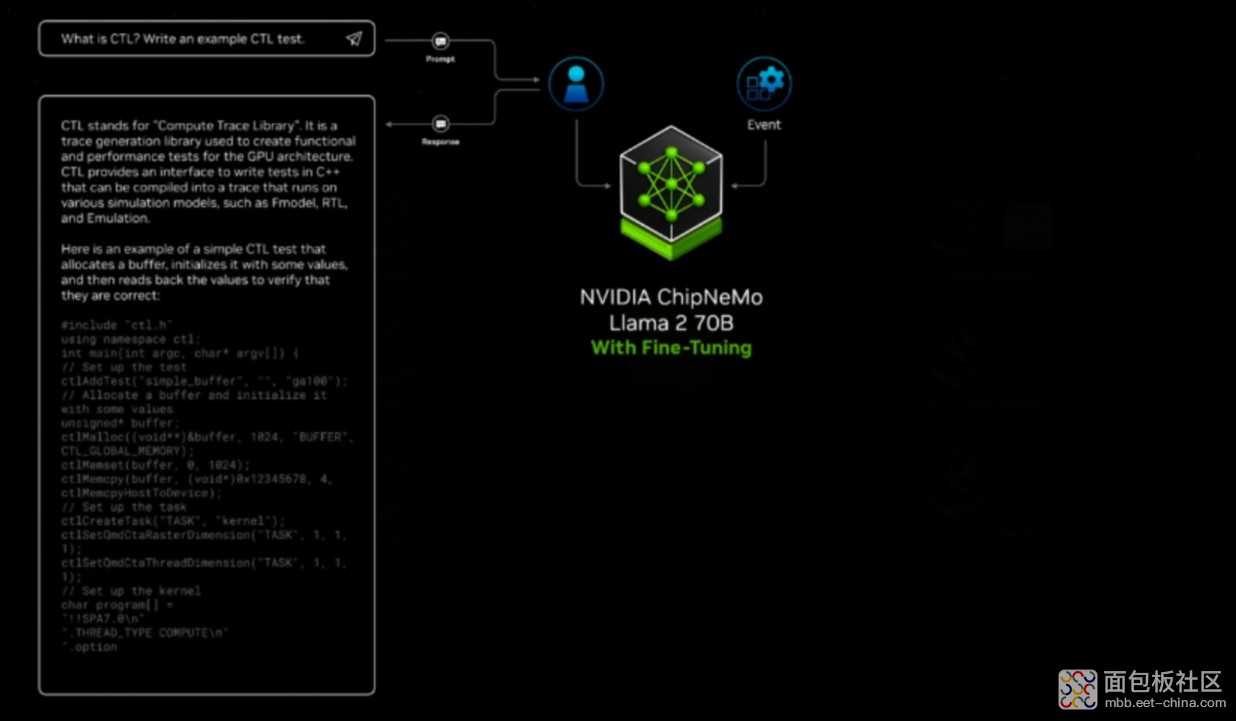
这部分的第二个技术,我想谈一下借助生成式 AI 来做芯片设计的 ChipNeMo。黄仁勋在主题演讲里也提了一下。应该是去年 GPT 和生成式 AI 大火以后,下半年好像就陆续有研究团队说,借助于 ChatGPT 来设计芯片的,全程自己不需要写一行代码,单纯就是跟 GPT 各种聊,让它写,最后的芯片就能跑起来。
我个人是相信这类新闻的,因为我自己去年数据库概念这门课,最后交给老师的 project,几乎所有代码都是 ChatGPT 写的,虽然程序框架和设计肯定是我自己做的,而且也花了大量时间 debug。芯片设计,如果不是那么复杂的话,也是类似的——只不过和 ChatGPT 聊的人自己还是要具备相应的业务能力的。
去年我采访的一些 EDA 企业认为,做复杂芯片设计的话,这种方式还是异想天开。但起码协助芯片设计是能做到的嘛。ChipNeMo 是英伟达内部的一个,用于芯片设计辅助的生成式 AI,也是 NVIDIA Research 做的。
预训练互联网数据得到 70b/130b 参数规模的 Llama 2 基础模型;然后进行芯片设计专门的训练,据说给到了 48GB 的设计文档、RTL 代码之类的数据,都喂进去;最后再进行监督 fine-tune——得到 ChipNeMo 聊天模型。
在英伟达内部,ChipNeMo 的一部分职责是给一些初级水平的芯片设计者用,他们有问题就可以直接问 ChipNeMo 了。另外一个职责是,对 bug 报告做总结——硅工们发现了 bug 会记录下来,这类报告可能会非常复杂、也很长,对旁人来说也很难理解,ChipNeMo 是可以给出容易理解的总结的。另外 ChipNeMo 自己也能生成 Verilog,不过这就只供参考了。

再介绍个所谓的 Efficient AI 研究,据说是 NVIDIA Research 最近才成立的研究团队,致力于让 AI 跑得更高效。当然其中涵盖很多不同的技术,比如说剪枝、稀疏化什么的。其中一项研究成果是 AWQ(Activation-aware Weight Quantization)权重量化,某些网络权重甚至可以降到 2bit,“某些权重会比其他权重更重要;有时需要表达高分辨率,有时则只需要很低的分辨率...”,而这些优化会“让你的网络跑起来更高效”。
“我们也会主动去发现神经网络,去找到最高效的模型。”说得还是挺泛的啊,但总体要表达的都是让 AI 更为高效,这应该也是现在很多 GPU/AI 芯片公司在做的事情。
其中一个例子就是基于 AWQ,让 LLM 跑在边缘或者端侧设备上——对英伟达来说,现阶段最重要的主题,其实还不是 LLM 跑在 PC 上,而是跑在 Jetson Nano 这样的边缘平台上。不过 AI PC 肯定也是这其中的一个重要议题。好像过去大半年 Intel 中国研究院也在搞这个东西吧,毕竟大家都要推 AI PC。

最后再聊一个基于 DaaS(Data as a Service)的快速 GPU 存储访问的项目吧。对某些场景、某些系统来说,比如说电商的推荐系统,请求大量数据可能没办法一下都塞进主内存里。所以 NVIDIA Research 有个项目是把存储系统,直接挂到 GPU 上。
一般的传统方法是文件系统请求要通过 CPU,即便是 GPU Direct 也如此。GPU Direct 的数据路径是直接走往 GPU 内存的,但 IO 操作最后还是 CPU 来给存储设备发信号,让存储设备直接把数据给到 GPU。这里的问题还是 CPU 太慢,100 万 IOPS 量级。
英伟达已经有了个原型方案,似乎产品化已经很快了,用 DaaS 方法。在 CPU 初始化安全认证访问以后,CPU 好像就不在数据请求的回路中了,GPU 可以“directly queue”,请求 IO 设备,达成 50 倍的存储带宽。“它能让你进行细粒度的存储操作,这很关键。”“你可能不需要 4k block 数据获取,而是小块的数据,需求更高频的 IOPS,在不需要大量 over fetch 的情况下就能做到。”

篇幅太长了,更多的就不说了——从芯片聊到软件了(软件还是大篇幅)。其实还是有很多可以去谈的东西,比如说 Bill 提到最近在搞 Automatic Fusion,针对 DNN 程序的 kernel fusion,提高推理的效率——据说自动 kernel fusion 的效果远优于程序员手动 fuse。
还有各类编程系统研究——其实也就是把各种原本只能 CPU 跑的东西,实现 GPU 的加速计算;以及内部的多 die 实验研究,像 Grace Hopper, Grace Blackwell 之类就是 NVIDIA Research 大量研究迭代后的产物;
更多 AI 视觉生成类应用;地球数字孪生 Earth-2,以及气候、天气相关的高精度研究;汽车 ADAS 相关动态驾驶场景“自监督重构”的研究,在做名为 PARA-drive 的感知基础模型;以及用强化学习来设计 GPU 上的 NV-ENC 视频编码器等等等等...
可能对很多日常就一直在关注英伟达的同学来说,上面很多内容也不能算多新鲜。这里还有一些内容是我没写的,比如机器人、汽车的部分我基本都没写,一方面是我自己也不大感兴趣,另一方面是今年 GTC 其实机器人相关的更新是个重点——所以机器人后面我是打算另外写文章的。
期望这些东西大家还感兴趣吧。说再多 AI 要改变世界的废话都是无用功,这些东西都是在潜移默化中发生的。不知各位发现没有,英伟达自己内部就在大量应用 AI 技术,包括生成式 AI,用 AI 来做产品。自家芯片和系统驱动着 AI,然后 AI 应用又在推动芯片和系统设计与结构进步。还挺有趣的吧...




 /5
/5 







文章评论(0条评论)
登录后参与讨论