
巫婆手中的毒苹果是童年世界的噩梦,然而现实中毒苹果也是真实存在的。在佛罗里达海滩、巴哈马、加勒比海和中南美洲的部分地区,有一种野苹果树,长着美丽妖娆的树枝,散发着浓郁的果香,却是世界上最毒的果树。其毒素隐藏在绿色的果肉中,误食后会出现口腔喉咙肿痛、胸部灼烧感、呼吸困难甚至会倒地昏迷,这种野生果树因而得名“死亡苹果”。
比尔-朗伯特(Beer-Lambert)定律的局限
当比尔-朗伯特定律在特定波长的浓度计算已经不能完成物质浓度计算,我们就需要通过该吸收光谱提取其他成分来判定物质信息。在复杂的测试体系中,很多精确复杂的数学方法已经被用来计算未知物质浓度 — 比如化学计量学。化学计量学在近些年越来越被大家熟知,得力于它的强大计算能力和各领域的大范围应用。
化学计量学的需求
在传统光谱分析失败的领域,化学计量学发挥重要作用,就比如说计算测量苹果的近红外反射光谱数据。为什么比尔-朗伯特定律在这个应用中不能发挥作用?首先,反射光谱存在很多不确定因素,比如:测试的方法;测试水果的内在散射的颗粒大小;苹果表面的状态等等。第二,近红外吸收光谱对于-OH,-NH,和-CH基团震动比较敏感。大多数有机化合物的吸收都在近红外这个波段,由于无数吸收光谱带的叠加,导致这个波段的近红外光谱无法计算。
近红外吸收光谱,不像其他近红外信息,不能简单地获得单个化合键的信息,因此类似于该领域的电磁谱已经被遗忘近十年。然而,化学计量学的发展已经打开了光谱信息的宝库,而该光谱信息可以通过光学光谱仪和光源简单的获得。
什么是真正的化学计量学?
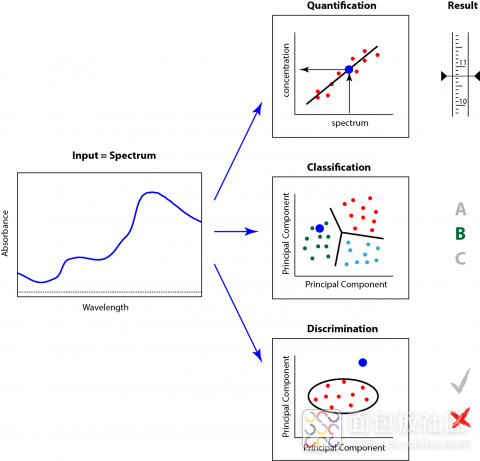
图1. 化学计量学在不同应用中的不同应用形式
图1中的化学计量学形式,通常会被问到3个问题:
1.定量:样品中确切的测量物有哪些?
汽油中十八烷烃的含量猜测
土壤中有机物含量的测定
2.分类:能指定确认样品中的哪些成分?
原材料的确认
3.辨别:样品是否符合质量标准?
偏差样品鉴定
批次样品生产过程中的监管流程
连续流程中不确定事件的早期判断
化学计量学的三步走
通过使用“测试集”与原始的“校正集”完全分离开的测量方法,对额外的已知样品光谱对模型进行有效性评估也是非常重要的。如果测量值的预测偏差在需求偏差和准确度范围内,那么该模型就可以用来测试新样品,从而获得感兴趣的数据结果(包括浓度或者组成员鉴别)。当我们使用一个完整建立好的化学计量学模型时,比如,一个苹果的简单NIR反射光谱,我们就可以用来评估测量样品的综合质量,比如苹果的甜度等等。
然而建立模型似乎是一个非常耗时的过程,排除对寄送样品所需的时间成本和昂贵的实验室测量成本,就其快速性,非破坏性,简单的预估等特点使得化学计量学还是有高的回报率的。NIR反射光谱是非常迅速的测量手段,比如说无需样品准备等等。
计量学背后的数学
那如何来精确计算呢?相对于单一值的算法(比如简单的线性拟合),我们现在必须选择使用整个数组的方法:PLS,SVM,PCA等等。幸运的是,我们在使用这些方法的时候,我们无需了解这些方法的具体细节及原理。事实上,即使这些方法看上去非常不一样,但是所获得的结果却很类似。
现在被大家认可的,且最常使用的定量方法是偏最小二乘法(PLS),它可以通过光谱数据(反映的“物质”)来最有效的分析解释物质的多样性及差别。另一个被普遍使用的分类方法叫支持向量机(SVM),而另一种用来将分析物与标准物进行区别的方法叫主成分分析方法(PCA)。软件工具
就像计量方法一样,数学分析方法作为一种软件处理工具,适用于对模型的开发。除了化学计量学整套程序软件(像数理统计软件“R”),或者MATLAB工具包,还有一些商业性质的化学计量学软件,比如Analyze IQ,GRAMS(Thermo Fisher),Unscrambler(Camo)or Pirouette(Infometrix)等等。这些软件为我们提供了数据建立,优化和测试化学计量学模型,再将这些数据捆绑到一起建立决定树状图,通过这些可以开发出更复杂的分析方法。
案例介绍:辨别苹果的甜度
波美度的测试非常耗时并且需要对每批的样品进行拆包,然后送到实验室进行检验。化学计量学的方法使用近红外反射光谱对其进行检测和计算,为客户提供快速、非破坏性测试等选择方案。在这个案例中,我们会展示化学计量学开发使用的大概步骤,并使用复杂分析方法测试并计算一个模型,比如:波美度。
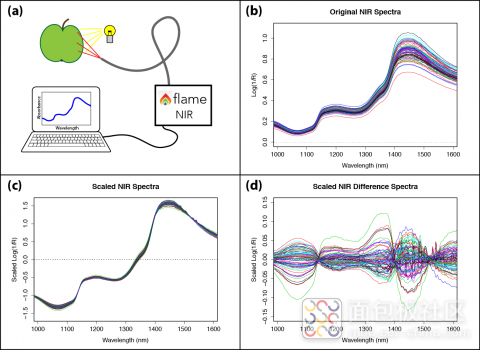
图2.(a)实验搭建;(b)红外反射光谱;(c)使用SNV对采样模型进行校正后的光谱;(d)校正后光谱和平均光谱间的差异
图2(a)为漫反射测量搭建形式并使用Flame-NIR(950-1650nm)光谱仪和卤钨灯光源采集76个姜黄色苹果红外反射光谱。使用的苹果包括成熟的和未成熟的,同时他们的波美度已经在实验室通过其他测量方法确定了。采集每个苹果上中轴线附近5个位置的光谱(图2b)。由于苹果外形的差异,使得测量过程中存在测量位置的差异,从而导致测量数据存在偏差,所以使用SNV(标准变量变换)的方法对其测量值进行前处理校正(图2c)。比如只有光谱数据之间的差异性才包含了测量物之间不同甜度的信息,所以我们用测量光谱减去所有光谱的平均值(这个过程叫做平均中心化,查看图2d),从而获得一组数据信息。
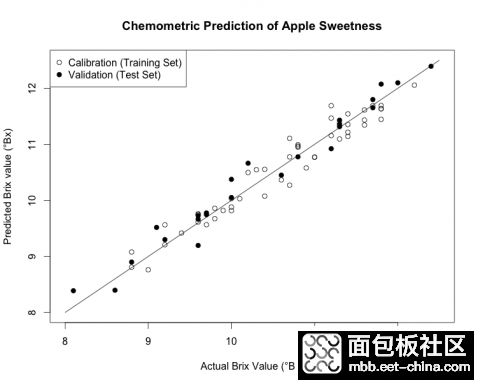
图3. 苹果真实甜度的对比图(使用实验室测量的波美度标记),并且根据红外反射光谱预测波美度
随机挑选1/3样品作为测试集,剩余2/3样品作为校正集,通过交叉验证方法建立甜度(波美度)指标的模型。尽管校正集训练结果良好,但是通过交叉验证方法可以提高模型对未知样品的预测精度,从而防止“过拟合”现象的发生。在此次模型建立过程中,当主成分数为5时模型性能最佳。模型的线性情况可以参考图3,在图中显示了校正集和预测集的糖度实测值和NIR预测值的散点图。两者数据间的偏差用预测标准偏差(SEP)来表示,如果偏差值小于0.3°Bx,我们就可以判断该模型准确有效。
案例分析:苹果品种鉴定
测量数据同样使用之前提出的数据前处理方式:使用SNV和平均-中心的比例尺,将共性和独特个性区分开。为了能辨清差异性,我们选择典型物质成分分析—通过数学分析方法来辨别光谱里的有效信息,而这类光谱能很好地展示不同品种苹果之间的差异。
正如数学结果所示,典型物质成分分布在所有波长定义的多维空间。该案例中,我们将苹果皮中主要成分光谱结合起来,包括类胡萝卜素(橙色),花青素(红色)和叶绿素a和b(600-700nm)。这些主成分信息能让我们根据重要维度获得更高维度数据,从而将有用信息从无用的噪音图谱中区分开。
针对目前的数据,不同光谱间的97%多样性可以通过两个主成分来解释分析。不同的苹果具有不同的“分数”,比如就像图4所示,将这两种典型物质结合后,就可以将光谱表达成不同维度的数据。同时,我们可以很轻松地将苹果分成三组:绿苹果,红苹果和黄-绿苹果。有了这个图表,我们可以以同样的方式测试未知样品的图谱,获得已知典型物质的分数,然后按照该表格将该苹果进行分类。
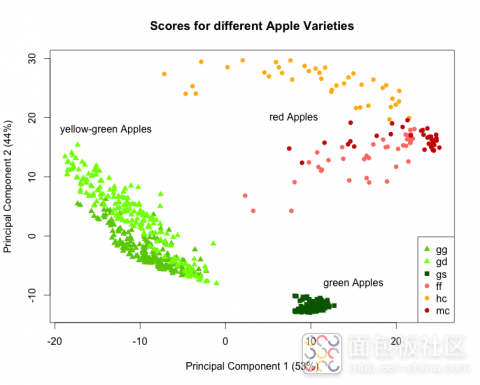
图4. 使用不同品种苹果可见光波段的反射图谱进行主成分分析。其中gg=姜黄苹果,gd=金黄苹果,gs=斯密斯奶奶苹果,ff=富士苹果,hc=蜂蜜松脆苹果,mc=麦金托什苹果
基于可见光波段的反射图谱可以将苹果分为黄苹果,绿苹果或者红苹果,并且可以作为分类工作的主要方法。“支持向量机”(SVM)作为常用的数学计算分析模型,经常被用于样品分类,即使在一些不明确分类的应用中,我们也可以使用。为了展示该方法,我们随机将我们的数据组分开,并将80%的可见光光谱(总共576个光谱)使用SVM分类模型将其分类。再进行交叉比对,并对最终模型中20%的数据进行结果认证,然后获得两模型参数的最佳值。那模型结果如何?在交叉比对中,分类错误率为0.3%,而在144个光谱的分开测试中,模型没有出现任何错误差值。
结 论
苹果反射光谱测量的装置搭建



 /5
/5 






文章评论(0条评论)
登录后参与讨论