原创
AMEYA360行业新闻:始于硬件却也被硬件所限的深度学习
2022-12-5 15:05
984
12
12
分类:
无人机
AI的浪潮其实早在20世纪就被多次掀起过,但真正成为人们不可忽视的巨浪,还是这十几年的事,因为这时候AI有了天时地利人和:算法与模型,大到足够训练这些模型的数据集,以及能在合理的时间内训练出这些模型的硬件。
但从带起第一波深度学习的AlexNet,到如今的GPT-3和TuringNLG等,人们不断在打造更大的数据集和更大的模型,加上大语言模型的兴起,对训练的要求也就越来越高。可在摩尔定律已经放缓的当下,训练时间也在被拉长。
基于Hopper架构的H100GPU/英伟达
以英伟达为例,到了帕斯卡这一代,他们才真正开始考虑单芯片的深度学习性能,并结合到GPU的设计中去,所以才有了Hopper这样超高规格的AI硬件出现。但我们在训练这些模型的时候,并没有在硬件规模上有所减少,仍然需要用到集成了数块HopperGPU的DGX系统,甚至打造一个超算。很明显,单从硬件这一个方向出发已经有些不够了,至少不是一个“高性价比”的方案。
软硬件全栈投入
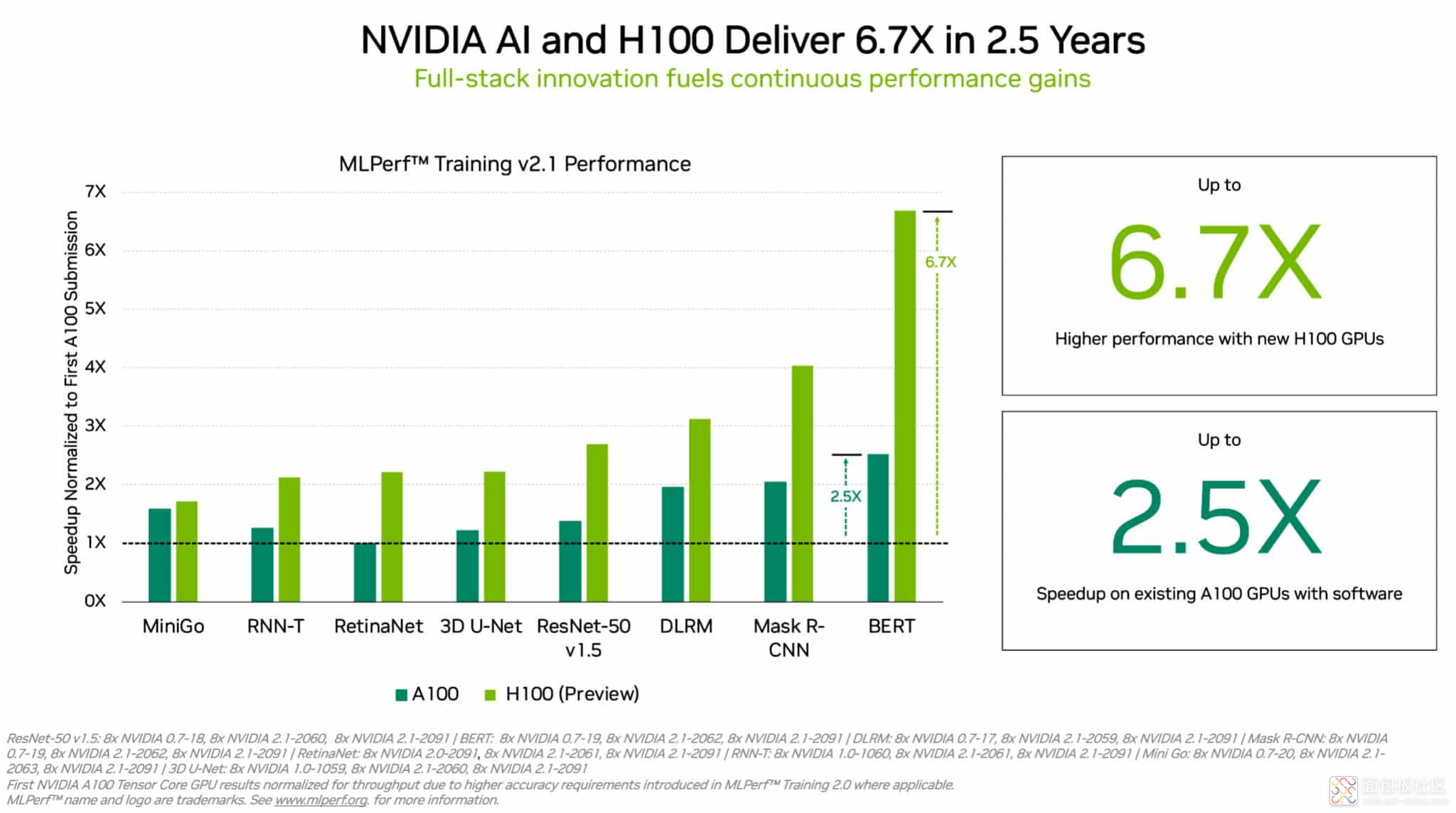
硬件推出后,仍要针对特定的模型进行进一步的软件优化,因此即便是同样的硬件,其AI性能也会在未来呈现数倍的飞跃。从上个月的MLPerf的测试结果就可以看出,在A100GPU推出的2.5年内,英伟达就靠软件优化实现了最高2.5倍的训练性能提升,当然了最大的性能提升还是得靠H100这样的新硬件来实现。
BillDally表示这就是英伟达的优势所在,虽然这几年投入进深度学习硬件的资本不少,但随着经济下行,不少投资者已经丧失了信心,所以不少AI硬件初创公司都没能撑下去,他自己也在这段时间看到了不少向英伟达投递过来的简历。
他认为不少这些公司都已经打造出了自己的矩阵乘法器,但他们并没有在软件上有足够的投入,所以即便他们一开始给出的指标很好看,也经常拿英伟达的产品作为对比,未来的性能甚至比不过英伟达的上一代硬件,更别说Hopper这类新产品了。



 /5
/5 






文章评论(0条评论)
登录后参与讨论