Linux内存管理 | 五、物理内存空间布局及管理
上章,我们介绍了物理内存的访问内存模型和组织内存模型,我们再来回顾一下:
物理内存的访问内存模型分为:
物理内存的组织模型:
- FLATMEM:平坦内存模型
- DISCONTIGMEM:不连续内存模型
- SMARSEMEM:稀疏内存模型
Linux内核为了用统一的代码获取最大程度的兼容性,对物理内存的定义方面,引入了:内存结点(node)、内存区域(zone),内存页(page)的概念,下面我们来一一探究。
更多干货可见:高级工程师聚集地,助力大家更上一层楼!
1、内存节点node
内存节点的引入,是Linux为了最大程度的提高兼容性,将UMA和NUMA系统统一起来,对于UMA而言是只有一个节点的系统。
下面的代码部分,我们尽可能的只保留暂时用的到的部分,不涉及太多的体系架相关的细节。
在Linux内核中,我们使用 typedef struct pglist_data pg_data_t表示一个节点
typedef struct pglist_data { ...
int node_id;
struct page *node_mem_map; unsigned long node_start_pfn;
unsigned long node_present_pages;
unsigned long node_spanned_pages;
...
}
pg_data_t;
node_id:每个节点都有自己的ID
node_mem_map:当前节点的struct page数组,用来管理这个节点的所有的页
node_start_pfn:这个节点的起始页号
node_present_pages:这个节点的真正可用的物理内存的页面数
node_spanned_pages:这个节点所包含的物理内存的页面数,包括不连续的内存空洞
例如,64M 物理内存隔着一个 4M 的空洞,然后是另外的 64M 物理内存。
这样换算成页面数目就是,16K 个页面隔着 1K 个页面,然后是另外 16K 个页面。
这种情况下,node_spanned_pages 就是 33K 个页面,node_present_pages 就是 32K 个页面。
内核使用了一个大小为 MAX_NUMNODES ,类型为 struct pglist_data 的全局数组 node_data[] 来管理所有的 NUMA 节点。
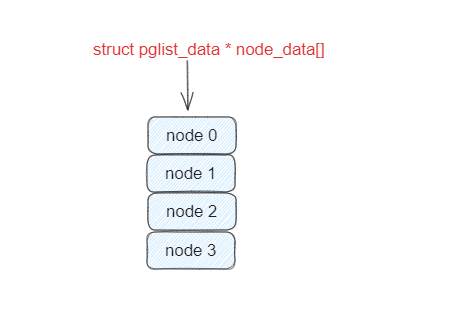
image-20231018065244586
2、内存区域zone
2.1 各区域的布局
每一个节点,都被分成了一个个区域zone,我们看一下zone的定义:
enum zone_type {
#ifdef CONFIG_ZONE_DMA ZONE_DMA,
#endif#ifdef CONFIG_ZONE_DMA32 ZONE_DMA32,
#endif ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM ZONE_HIGHMEM,
#endif ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE ZONE_DEVICE,
#endif __MAX_NR_ZONES
};
ZONE_DMA:用作DMA的内存。
DMA 是这样一种机制:要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。
CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。
ZONE_DMA32:对于 64 位系统,有两个 DMA 区域。除了上面说的 ZONE_DMA,还有 ZONE_DMA32。
ZONE_NORMAL:直接映射区,也就i是之前讲的从物理内存到虚拟内存的内核区域,通过加上一个常量直接映射。
ZONE_HIGHMEM:高端内存区
ZONE_MOVABLE:可移动区域,通过将物理内存划分为可移动分配区域和不可移动分配区域来避免内存碎片。
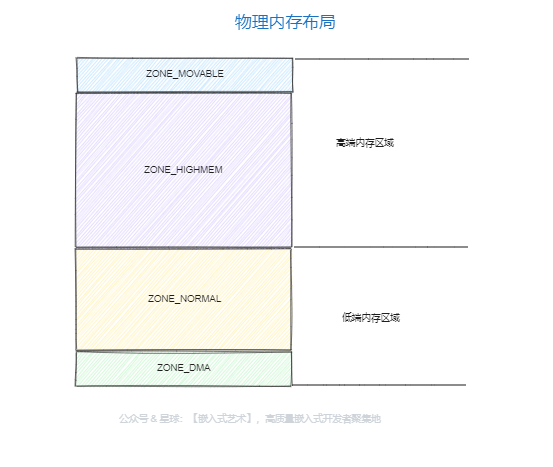
image-20231017072500328
2.2 各区域的管理
上面我们大致了解了,每个zone的布局情况,下面我们来看看内核是如何对其进行管理的。
接着上面介绍的pglist_data结构体
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it
's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
...
int node_id;
struct page *node_mem_map;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
...
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
...
} pg_data_t;
- nr_zones:用于统计 NUMA 节点内包含的物理内存区域个数,不是每个 NUMA 节点都会包含以上介绍的所有物理内存区域,NUMA 节点之间所包含的物理内存区域个数是不一样的。
事实上只有第一个 NUMA 节点可以包含所有的物理内存区域,其它的节点并不能包含所有的区域类型,因为有些内存区域比如:ZONE_DMA,ZONE_DMA32 必须从物理内存的起点开始。这些在物理内存开始的区域可能已经被划分到第一个 NUMA 节点了,后面的物理内存才会被依次划分给接下来的 NUMA 节点。因此后面的 NUMA 节点并不会包含 ZONE_DMA,ZONE_DMA32 区域。
ZONE_NORMAL、ZONE_HIGHMEM 和 ZONE_MOVABLE 是可以出现在所有 NUMA 节点上的。
- node_zones[MAX_NR_ZONES]:node_zones该数组包括了所有的zone物理内存区域
- node_zonelists[MAX_ZONELISTS]:是 struct zonelist 类型的数组,它包含了备用 NUMA 节点和这些备用节点中的物理内存区域。
下面我们看一下struct zone结构体
struct zone {......
struct pglist_data *zone_pgdat; struct per_cpu_pageset __percpu *pageset; unsigned long zone_start_pfn;
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
......
struct free_area free_area[MAX_ORDER]; unsigned long flags;
spinlock_t lock;
......
} ____cacheline_internodealigned_in_
- zone_start_pfn:表示属于这个zone的第一个页
- spanned_pages:看注释我们可以知道,spanned_pages = zone_end_pfn - zone_start_pfn,表示该区域的所有物理内存的页面数,包括内存空洞
- present_pages:看注释我们可以知道,present_pages = spanned_pages - absent_pages(pages in holes),表示该区域真实存在的物理内存页面数,不包括空洞
- managed_pages:看注释我们可以知道,managed_pages = present_pages - reserved_pages,被伙伴系统管理的所有页面数。
- per_cpu_pageset:用于区分冷热页,
什么叫冷热页呢?咱们讲 x86 体系结构的时候讲过,为了让 CPU 快速访问段描述符,在 CPU 里面有段描述符缓存。CPU 访问这个缓存的速度比内存快得多。同样对于页面来讲,也是这样的。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
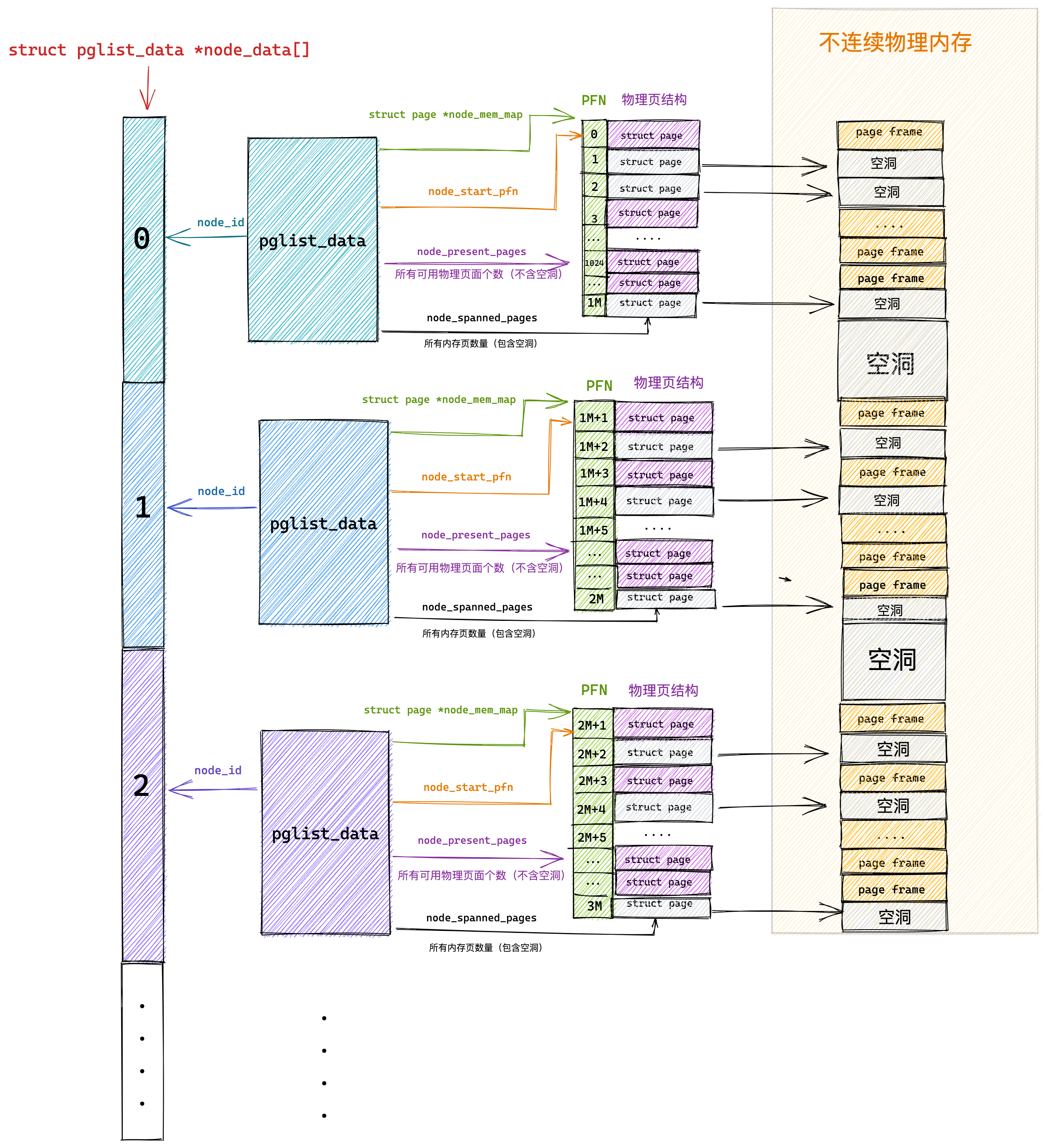
image.png
更多干货可见:高级工程师聚集地,助力大家更上一层楼!
3、内存页page
内存页是物理内存最小单位,有时也叫页帧(page frame),Linux会为系统的物理内存的每一个页都创建了struct page对象,并用全局变量struct page *mem_map来存放所有物理页page对象的指针,页的大小取决于MMU(Memory Management Unit),后者主要用来将虚拟地址空间转换为物理地址空间。
看一下page的结构体
struct page { unsigned long flags;
union {
struct { struct list_head lru; struct address_space *mapping; pgoff_t index;
unsigned long private;
};
struct { union {
struct list_head slab_list; struct { struct page *next; #ifdef CONFIG_64BIT int pages;
int pobjects;
#else short
int pages;
short
int pobjects;
#endif };
};
struct kmem_cache *slab_cache; void *freelist;
union {
void *s_mem;
unsigned long counters;
struct { unsigned inuse:
16;
unsigned objects:
15;
unsigned frozen:
1;
};
};
};
.....
}
我们能够看到struct page有很多union组成,union 结构是在 C 语言中被用于同一块内存根据情况保存不同类型数据的一种方式。这里之所以用了 union,是因为一个物理页面使用模式有多种。
- 第一种模式:直接用一整页,这一整页的物理内存直接与虚拟地址空间建立映射关系,我们把这种称为匿名页(Anonymous Page)。或者用于关联一个文件,然后再和虚拟地址空间建立映射关系,这样的文件,我们称为内存映射文件(Memory-mapped File),这种分配页级别的,Linux采用一种被称为伙伴系统(Buddy System)的技术。
- 第二种模式:仅需要分配小的内存块。有时候,我们不需要一下子分配这么多的内存,例如分配一个 task_struct 结构,只需要分配小块的内存,去存储这个进程描述结构的对象。为了满足对这种小内存块的需要,Linux 系统采用了一种被称为slab allocator的技术
上面说的两种,都是页的分配方式,也就是物理内存的分配方式,下一章,我们继续深入分析物理内存的这两种分配方式。

img



 /5
/5 






文章评论(0条评论)
登录后参与讨论