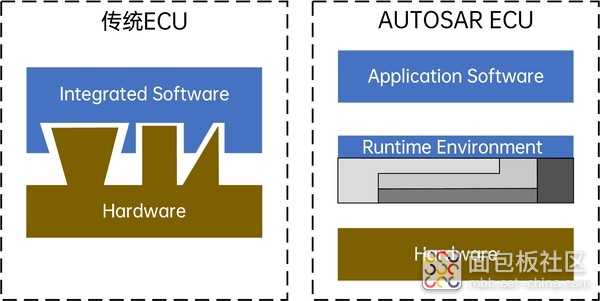
一、引言 随着汽车新四化“ 电动化、网联化、智能化、共享化 ”全面推进,几乎每一项新技术的诞生都离不开 汽车电子 的身影。其中, 电子控制单元 (Electronic Control Unit,ECU)作为汽车电子控制系统的核心。与 传统ECU 相比,采用 AUTOSAR (AUTomotive Open System ARchitecture,汽车开放系统架构)这种分层架构,极大降低了汽车嵌入式系统软、硬件耦合度。 图1 传统软件架构与AUTOSAR架构对比 此外,随着国内新能源汽车 相关控制器正向开发需求 的增长, AUTOSAR规范 越来越受到大家的关注,并且应用需求也越来越大。国内一些 主流整车厂 以及 零部件供应商 都开始致力于符合AUTOSAR规范的车用控制器软件开发。 二、汽车电子控制系统 汽车电子控制系统 由传感器(Sensor)、电子控制单元(Electronic Control Unit,ECU)和执行器(Actuator)组成。 图2 汽车电子控制系统基本构成 传感器 作为 信号输入装置 ,用来检测和采集各种信息,如温度、压力、转速等,可以将非电量信号转换为电信号传给电子控制单元。 ECU 也即 汽车嵌入式系统 (Automotive Embedded System,AES),ECU对传感器的信号进行处理,通过 控制算法 向执行器发出控制指令。硬件部分主要由微控制器(Microcontroller,MCU)及外围电路组成;软件部分主要包括硬件抽象层(Hardware Abstraction Layer,HAL)、嵌入式操作系统及底层软件和应用软件层。 执行器 为执行某种控制功能的装置,用于 接收来自ECU的控制指令 ,并对控制对象实施相应的操作。 三、ECU开发流程中总线通讯:ARXML 规则下的标准化协作 ECU 实际开发流程 中,从需求分析与定义到系统集成测试, 总线通讯 贯穿始终。 比如在 需求分析与定义阶段 ,开发团队首先要梳理 整车功能需求 ,明确各 ECU 需要实现的功能及彼此间的 数据交互需求 。 基于这些需求,工程师使用 ARXML (AUTOSAR Extensible Markup Language)文件 定义 ECU 间的通讯协议 ,包括选择 CAN、Flexray 还是 SOME/IP 总线,以及详细规划报文结构、信号编码等内容。 以 CAN 总线 为例,ARXML 文件中会明确 CAN 报文的 ID、数据长度、信号位置及编码方式等信息。开发人员依据这些规范进行 代码实现 ,确保各个 ECU 在 CAN 总线上准确收发数据。 在 集成测试阶段 ,ARXML 文件提供的标准化描述,能帮助测试人员快速搭建测试用例,验证 ECU 间的通讯逻辑是否符合预期。比如,通过对比 ARXML 定义的信号与实际总线上抓取的数据 ,精准定位通讯异常问题,极大提升开发效率与系统稳定性。 四、ADTF:汽车数据与时间触发框架(Automotive Data and Time-Triggered Framework) ADTF 作为一款 专业的汽车数据与时间触发框架软件 ,是一个 基于层级 和 面向服务 的系统架构。 图3 ADTF 系统架构 大家也可以看出来, ADTF 同样采用 模块化的设计 ,与 AUOSAR CP 架构层级设计有异曲同工之妙 。基于Runtime来封装底层服务,通过 插件开发 可以生成各类工具箱,完成ECU开发中各类测试任务。比如在 总线类数据的解析 与 测试领域 有着卓越表现。它具备强大的 多总线数据处理能力 ,比如adtf_car_communication_toolbox、adtf_device_toolbox。能够 无缝接入 CAN、Flexray、SOME/IP 等多种汽车总线 ,并基于 ARXML 规则 对总线数据进行解析。 五、应用案例 在 ADTF Car Communication Toolbox 中,基于 “AUTOSAR ARXML 文件对汽车总线通信数据进行解码,实现了 CAN、FlexRay 和 SOME/IP 等总线协议的解析。 图4 Decoding CAN using arxml database 图5 Decoding FlexRay using arxml database 图6 Decoding SOMEIP using arxml database 该工具包通过 集成 ARXML 解析能力 , 使 ADTF 具备汽车总线通信的解码功能 ,适用于 车载网络开发 、 测试与分析场景 ,帮助工程师将原始总线数据转换为可理解的信号流,提升汽车电子系统的开发效率。 六、结语 在汽车电子技术飞速发展的当下, 基于 ARXML 规则的总线通讯标准化与高效解析能够加快ECU开发流程 。 ADTF 具备多总线数据解析与测试能力,深度结合 ARXML 规则,为 CAN、Flexray、SOME/IP 等总线数据处理提供测试解决方案。 无论是 ECU 开发过程中的协议验证,还是整车集成测试中的问题定位,ADTF 都能快速部署完成测试开发。



 标签: 数据
标签: 数据