
- 面包板社区
- > > 标签
- > > TensorFlow
 标签: TensorFlow
标签: TensorFlow
相关帖子


相关博文
-
B y Toradex 胡珊逢 NXP iMX8M Plus 作为其第一款支持神经网络运算硬件加速的处理器,提供对多种框架的支持,例如 ArmNN 、 TensorFlowLite 、 ONNX , eIQ Poral 工具可以使用户能够轻松地训练自己地模型,或者将现成的模型转换为适合在 iMX8M Plus 进行加速的模型。本文将介绍如何在 Toradex 的 Verdin iMX8M Plus 计算机模块上使用现成训练好的 TensorFlow Lite 模型开发深度学习应用,以及自行训练模型并借助 eIQ Poral 对模型进行转换使其适合在计算机模块上使用。 深度学习应用开发流程中,一个重要的环节就是训练模型。这不仅需要合理地调整参数,还需要大量的样本数据以及充足算力的计算机。因此使用训练好的模型通常是一个不错的选择,尤其是在项目初期缺少样本数据的阶段。 TensorFlow Hub 提供了丰富的资源。这里我们将使用 ssd_mobilenet_v1 模型,以及一个使用 P ython 开发的 物体识别例程 介绍如何使用这些现成的模型。 Toradex 部分的默认 BSP 中没有集成深度学习所需的软件,但可以通过 Yocto Project 非常容易将 NXP 深度学习软件集成到 Verdin iMX8M Plus BSP 中,具体方法可以参考 该文章 。 然后下载包含 metadata 的模型文件,使用压缩工具直接解压下载的 tflite 文件(例如 lite-model_ssd_mobilenet_v1_1_metadata_2.tflite )即可获得标签文件 labelmap.txt ,该文件中存放了能够识别物体的名字。在应用中我们将会使用该文件来显示所识别物体。模型下载页面介绍了输入和输出数据的结构。例如需要输入 RGB 色彩格式数据。输出数据部分包含被识别物体在图片中的位置,所属分类,对应分类的可信度等。 下面代码为初始化 ssd_mobilenet 模型,并获取关于该模型的基本信息,例如输入图片的大小,后面将摄像头采集到的图片调整对应尺寸。 ------------------------------------- # Load the Tensorflow Lite model. interpreter = tflite.Interpreter(model_path=PATH_TO_CKPT) interpreter.allocate_tensors() # Get model details input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() height = input_details width = input_details ------------------------------------- 将采集到的数据放入模块进行推演运算。 ------------------------------------- # Perform the actual detection by running the model with the image as input interpreter.set_tensor(input_details ,input_data) interpreter.invoke() ------------------------------------- 最后获取被识别物体的位置,名称和相应的可信度。 ------------------------------------- boxes = interpreter.get_tensor(output_details ) classes = interpreter.get_tensor(output_details ) scores = interpreter.get_tensor(output_details ) ------------------------------------- 使用 O penCV 默认的配置读取摄像头时性能不是很理想,因此结合 Verdin iMX8M Plus 本身硬件特点,使用适当的 gstreamer pipeline 进行读取。 ------------------------------------- cv2.VideoCapture(" v4l2src device=/dev/video0 ! image/jpeg,width=1280,height=720,framerate=30/1 ! jpegdec ! videoconvert ! appsink", cv2.CAP_GSTREAMER) ------------------------------------- 最后通过下面命令启动应用程序。 ------------------------------------- root@verdin-imx8mp:~# export XDG_RUNTIME_DIR=/run/user/0 root@verdin-imx8mp:~# python3 tf-lite-detection-webcam.py --modeldir /home/root/PyOpenCV --graph lite-model_ssd_mobilenet_v1_1_metadata_2.tflite --labels labelmap.txt --resolution 1280x720 ------------------------------------- Verdin iMX8M Plus 可以通过 NPU 对应 TF Lite 进行硬件加速,能够实现以 4 0 fps 左右的速度进行物体识别。 在更多的时候,我们可能需要自行采集原始数据并对其进行标记,然后训练模型。下面我们将使用 TensorFlow 分类识别 ECG 心电信号 。这过程中会介绍如何在 PC 上使用 MIT-BIH 心律失常数据库 训练一个 Ten sorFlow 模型,然后使用 eIQ 将其转换为适合 iMX8M Plus 的 Ten sorFlow L ite 模型。 首先现从上面链接下载 Python 代码和心律数据。删除已经训练好的模块 ecg_model.h5 ,然后在 PC 上执行下面命令重新训练模型。根据 PC 性能,这过程会持续一段时间,最后重新生成 ecg_model.h5 文件。 ------------------------------------- $ python3 ecg.py ------------------------------------- 打开 eIQ 工具,使用默认配置将其转化为 Ten sorFlow L ite 模型 ecg_model.tflite 。 在模型转换后输入和输出的数据格式也会发生相应额变化,例如输入固定为 1*300*1 。 因此在代码中使用 reshape 函数对数据重新排列。 获得模型对每个心律信号可信度最高的预测。 结合数据库中实际诊断的结果生成一张对比矩阵图。 代码运行期间也记录以一些数据,如总共处理的 27657 个心电信号,首次运行时需要对 iMX8M Plus 的 NPU 进行 warmup ,因此耗时为 177 ms 。其后则能够以 7.5 ms 处理每个心电信号。 ------------------------------------- Total 27657signlas First 10 inferences' time: 177.1 ms First 10 inferences' time: 7.5 ms First 10 inferences' time: 7.5 ms First 10 inferences' time: 7.5 ms ------------------------------------- 总结 Verdin iMX8M Plus 得益于 NPU 能高效地处理神经网络计算。上面是一些简单的演示介绍,为了更好地发挥 NPU 性能,还需要对神经网络模块进行优化。通常现成的模型都是针对算力充足的 PC 所训练,甚至是 GPU 加速。而作为嵌入式系统处理器 iMX8M Plus ,还需要兼顾功耗, NPU 算力也无法和桌面级 GPU 相提并论。对模型的优化就显得尤为重要,常见的方法如 quantization ,牺牲少量的精度换取更快速的计算。
-
By Toradex秦海 1). 简介 随着嵌入式处理器性能的提升甚至一些嵌入式处理器已经开始集成针对人工智能和机器学习的硬件加速单元NPU,机器学习应用在嵌入式边缘设备的应用也慢慢展现。为此,NXP也发布了eIQ for i.MX软件工具包,用于在NXP的i.MX系列嵌入式处理器上面来支持目前比较常见的各种机器学习推理引擎,比如TensorFlow、Caffe等,具体的支持情况可以参考下图,其中ArmNN、TensorFlowLite、ONNX可以支持GPU/NPU硬件加速,而OpenCV和PyTorch目前只支持在CPU运行。 NXP eIQ协议栈通过Neural Network Runtime (NNRT)模块来对不同的前端Runtime进行硬件加速支持,具体的架构可以参考下图,对于很多机器学习算法场景,通过硬件加速引擎可以很大提升算法推理性能。 本文的演示的平台来自于Toradex Apalis iMX8 ARM嵌入式平台,这是一个基于NXP iMX8QM ARM处理器,支持Cortex-A72+A53和Coretex-M4架构的计算机模块平台。 2). 准备 a). Apalis iMX8QM 4GB WB IT ARM核心版配合 Ioxra载板 ,连接调试串口UART1(载板X22)到开发主机方便调试。载板连接HDMI显示器。 3). Apalis iMX8 Ycoto Linux 编译部署以及配置 a). Apalis iMX8 Ycoto Linux通过Ycoto/Openembedded框架编译,具体的配置方法请参考 这里 ,参考如下修改后编译Reference-Multimedia image镜像 ./ iMX8 Ycoto layer中默认没有包含NXP Machine Learning和OpenCV 4.4.0版本支持,因此首先需要通过下面修改添加相关layer,详细的NXP Ycoto指南请参考i.MX Yocto Project User's Guide Rev. L5.4.70_2.3.0 ------------------------------- ### download related layers from NXP official repository $ repo init -u https://source.codeaurora.org/external/imx/imx-manifest -b imx-linux-zeus -m imx-5.4.70-2.3.0.xml $ repo sync $ DISTRO=fsl-imx-wayland MACHINE=imx8qmmek source imx-setup-release.sh -b build ### copy mechine learning layer meta-ml to Toradex ycoto environment $ cp -r …/sources/meta-imx/meta-ml …/oe-core/layers/ ### modify meta-ml layer …/layers/meta-ml/conf/layer.conf file to support ycoto dunfell --- a/layers/meta-ml/conf/layer.conf 2021-03-03 15:50:59.718815084 +0800 +++ b/layers/meta-ml/conf/layer.conf 2021-03-03 16:55:46.791158625 +0800 @@ -8,4 +8,4 @@ BBFILE_COLLECTIONS += "meta-ml" BBFILE_PATTERN_meta-ml := "^${LAYERDIR}/" BBFILE_PRIORITY_meta-ml = "8" -LAYERSERIES_COMPAT_meta-ml = "warrior zeus" +LAYERSERIES_COMPAT_meta-ml = "warrior zeus dunfell" ### copy opencv 4.4.0 related to Toradex ycoto environment $ cp -r …/sources/meta-imx/meta-bsp/recipes-support/opencv/ …/oe-core/layers/meta-toradex-nxp/recipes-support/opencv/ ### modify build/conf/bblayer.conf to add above extra layers --- a/build/conf/bblayers.conf +++ b/build/conf/bblayers.conf @@ -24,6 +24,9 @@ ${TOPDIR}/../layers/meta-openembedded/meta-python \ ${TOPDIR}/../layers/meta-freescale-distro \ ${TOPDIR}/../layers/meta-toradex-demos \ + ${TOPDIR}/../layers/meta-ml \ ${TOPDIR}/../layers/meta-qt5 \ \ \ ------------------------------- ./修改local.conf,增加mechine learning相关支持 ------------------------------- ### add python and opencv support ### +IMAGE_INSTALL_append = " python3 python3-pip opencv python3-opencv python3-pillow" ### add eIQ support ### +IMAGE_INSTALL_append = " arm-compute-library nn-imx tensorflow-lite armnn onnxruntime" +PACKAGECONFIG_append_pn-opencv_mx8 = " dnn jasper qt5 test" ### remove opencl conflict ### +PACKAGECONFIG_remove_pn-opencv_mx8 = "opencl" +PACKAGECONFIG_remove_pn-arm-compute-library = "opencl" ### option, add onnxruntime and armnn dev support to SDK ### +TOOLCHAIN_TARGET_TASK_append += " onnxruntime-dev armnn-dev " ACCEPT_FSL_EULA = "1" ------------------------------- ./编译image和SDK ------------------------------- # compile Reference-Multimedia image $ bitbake bitbake tdx-reference-multimedia-image # compile SDK bitbake tdx-reference-multimedia-image -c populate_sdk ------------------------------- b). Ycoto Linux image部署 参考 这里 通过Toradex Easy installer将上面编译好的image更新部署到模块,目前最新稳定版本为Ycoto Linux V5.1,最新测试版本为Ycoto Linux V5.2 4). TensorFlow Lite 测试 a). NXP iMX8 eIQ TensorFlow Lite支持特性和协议栈框图如下 ./ TensorFlow Lite v2.3.1 ./ Multithreaded computation with acceleration using Arm Neon SIMD instructions on Cortex-A cores ./ Parallel computation using GPU/NPU hardware acceleration (on shader or convolution units) ./ C++ and Python API (supported Python version 3) ./ Per-tensor and Per-channel quantized models support b).示例应用测试 ./ Image预装的TensorFlow Lite测试示例应用位置 /usr/bin/tensorflow-lite-2.3.1/examples ./基于mobilenet model测试“label_image”示例应用 ------------------------------- $ cd /usr/bin/tensorflow-lite-2.3.1/examples/ ### Run on CPU $ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt Loaded model mobilenet_v1_1.0_224_quant.tflite resolved reporter invoked average time: 44.999 ms 0.780392: 653 military uniform 0.105882: 907 Windsor tie 0.0156863: 458 bow tie 0.0117647: 466 bulletproof vest 0.00784314: 835 suit ### Run with GPU acceleration $ ./label_image -m mobilenet_v1_1.0_224_quant.tflite -i grace_hopper.bmp -l labels.txt -a 1 Loaded model mobilenet_v1_1.0_224_quant.tflite resolved reporter INFO: Created TensorFlow Lite delegate for NNAPI. Applied NNAPI delegate. invoked average time: 13.103 ms 0.784314: 653 military uniform 0.105882: 907 Windsor tie 0.0156863: 458 bow tie 0.0117647: 466 bulletproof vest 0.00784314: 668 mortarboard ### TensorFlow Lite Python API predefined example script run, no option to choose CPU or GPU, run with GPU acceleration by default if libneuralnetworks.so or libneuralnetworks.so.1 is found in the /usr/lib directory, otherwise run on CPU $ python3 label_image.py INFO: Created TensorFlow Lite delegate for NNAPI. Applied NNAPI delegate. Warm-up time: 5052.5 ms Inference time: 12.7 ms 0.674510: military uniform 0.129412: Windsor tie 0.039216: bow tie 0.027451: mortarboard 0.019608: bulletproof vest ------------------------------- c).更多示例和benchmark测试,C++ API应用开发以及当前eIQ对于TensorFlow Lite不同模型的限制等更多信息可以参考NXP i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 Chapter 3 TensorFlow Lite,从上面简单测试可以看出NPU加速下mobilenet模型要比CPU运行性能更好。 5). Arm Compute Library 测试 a). ACL(ARM-Compute Library)是专为ARM CPU & GPU优化设计的计算机视觉和机器学习库,基于NEON & OpenCL支持的SIMD技术,但在iMX8平台目前只支持CPU NEON加速,另外因为其为ARM NN架构的计算引擎,因此一般来说建议直接使用ARM NN。NXP iMX8 eIQ ACL支持特性如下 ./ Arm Compute Library 20.02.01 ./ Multithreaded computation with acceleration using Arm Neon SIMD instructions on Cortex-A cores ./ C++ API only ./ Low-level control over computation b).示例应用测试 ./ Image预装的ACL测试示例应用位置 /usr/share/arm-compute-library/build/examples ./ MobileNet v2 DNN model,随机输入量测试 ------------------------------- $ cd /usr/share/arm-compute-library/build/examples $ ./graph_mobilenet_v2 Threads : 1 Target : NEON Data type : F32 Data layout : NHWC Tuner enabled? : false Cache enabled? : false Tuner mode : Normal Tuner file : Fast math enabled? : false Test passed ------------------------------- c).更多示例测试和参数说明可以参考NXP i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 Chapter 4 Arm Compute Library。 6). Arm NN 测试 a). Arm NN是适用于CPU,GPU和NPU的开源推理引擎,该软件桥接了现有神经网络框架(例如TensorFlow、TensorFlow Lite、Caffe或ONNX)与在嵌入式Linux平台上运行的底层处理硬件(例如CPU、GPU或NPU)。这样,开发人员能够继续使用他们首选的框架和工具,经Arm NN无缝转换结果后可在底层平台上运行,NXP iMX8 eIQ ARM NN支持特性和协议栈框图如下 ./ Arm NN 20.02.01 ./ Multithreaded computation with acceleration using Arm Neon SIMD instructions on Cortex-A cores provided by the ACL Neon backend ./ Parallel computation using GPU/NPU hardware acceleration (on shader or convolution units) provided by the VSI NPU backend ./ C++ and Python API (supported Python version 3) ./ Supports multiple input formats (TensorFlow, TensorFlow Lite, Caffe, ONNX) ./ Off-line tools for serialization, deserialization, and quantization (must be built from source) b). Apalis iMX8 $Home目录下创建如下测试使用目录以供后续测试使用 ------------------------------- $ mkdir ArmnnTests $ cd ArmnnTests $ mkdir data $ mkdir models ------------------------------- c). Caffe示例应用测试 ./ Image包含如下ARM NN Caffe模型测试示例,本文随机选择CaffeAlexNet-Armnn进行测试 /usr/bin/CaffeAlexNet-Armnn /usr/bin/CaffeCifar10AcrossChannels-Armnn /usr/bin/CaffeInception_BN-Armnn /usr/bin/CaffeMnist-Armnn /usr/bin/CaffeResNet-Armnn /usr/bin/CaffeVGG-Armnn /usr/bin/CaffeYolo-Armnn ./部署模型和输入数据文件到模块 ------------------------------- ###从 这里 下载,bvlc_alexnet_1.caffemodel模型文件,部署到Apalis iMX8 ~/ArmnnTests/models;shark.jpg输入文件,部署到Apalis iMX8 ~/ArmnnTests/data $ cd ArmnnTests ### Run with C++ backend, CPU without NEON $ CaffeAlexNet-Armnn --data-dir=data --model-dir=models --compute=CpuRef Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 2 with value: 0.706227 Info: Top(2) prediction is 0 with value: 1.26575e-05 Info: Total time for 1 test cases: 15.842 seconds Info: Average time per test case: 15841.653 ms Info: Overall accuracy: 1.000 ### Run with ACL NEON backend, CPU with NEON $ CaffeAlexNet-Armnn --data-dir=data --model-dir=models --compute=CpuAcc Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 2 with value: 0.706226 Info: Top(2) prediction is 0 with value: 1.26573e-05 Info: Total time for 1 test cases: 0.237 seconds Info: Average time per test case: 236.571 ms Info: Overall accuracy: 1.000 ### Run with GPU/NPU backend $ CaffeAlexNet-Armnn --data-dir=data --model-dir=models --compute=VsiNpu Info: ArmNN v20200200 , size = 618348Warn-Start NN executionInfo: = Prediction values for test #0 Info: Top(1) prediction is 2 with value: 0.706227 Info: Top(2) prediction is 0 with value: 1.26573e-05 Info: Total time for 1 test cases: 0.304 seconds Info: Average time per test case: 304.270 ms Info: Overall accuracy: 1.000 ------------------------------- d). TensorFlow示例应用测试 ./ Image包含如下ARM NN TensorFlow模型测试示例,本文随机选择TfInceptionV3-Armnn进行测试 /usr/bin/TfCifar10-Armnn /usr/bin/TfInceptionV3-Armnn /usr/bin/TfMnist-Armnn /usr/bin/TfMobileNet-Armnn /usr/bin/TfResNext-Armnn ./部署模型和输入数据文件到模块 ------------------------------- ###从 这里 下载,inception_v3_2016_08_28_frozen.pb模型文件,部署到Apalis iMX8 ~/ArmnnTests/models;shark.jpg, Dog.jpg, Cat.jpg输入文件,部署到Apalis iMX8 ~/ArmnnTests/data $ cd ArmnnTests ### Run with C++ backend, CPU without NEON $ TfInceptionV3-Armnn --data-dir=data --model-dir=models --compute=CpuRef Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 0.454895 Info: Top(2) prediction is 160 with value: 0.00278846 Info: Top(3) prediction is 131 with value: 0.000483914 Info: Top(4) prediction is 56 with value: 0.000304587 Info: Top(5) prediction is 27 with value: 0.000220489 Info: = Prediction values for test #1 Info: Top(1) prediction is 283 with value: 0.481285 Info: Top(2) prediction is 282 with value: 0.268979 Info: Top(3) prediction is 151 with value: 0.000375892 Info: Top(4) prediction is 24 with value: 0.00036751 Info: Top(5) prediction is 13 with value: 0.000330214 Info: = Prediction values for test #2 Info: Top(1) prediction is 3 with value: 0.986568 Info: Top(2) prediction is 0 with value: 1.51615e-05 Info: Total time for 3 test cases: 1477.627 seconds Info: Average time per test case: 492542.205 ms Info: Overall accuracy: 1.000 ### Run with ACL NEON backend, CPU with NEON $ TfInceptionV3-Armnn --data-dir=data --model-dir=models --compute=CpuAcc Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 0.454888 Info: Top(2) prediction is 160 with value: 0.00278851 Info: Top(3) prediction is 131 with value: 0.00048392 Info: Top(4) prediction is 56 with value: 0.000304589 Info: Top(5) prediction is 27 with value: 0.000220489 Info: = Prediction values for test #1 Info: Top(1) prediction is 283 with value: 0.481286 Info: Top(2) prediction is 282 with value: 0.268977 Info: Top(3) prediction is 151 with value: 0.000375891 Info: Top(4) prediction is 24 with value: 0.000367506 Info: Top(5) prediction is 13 with value: 0.000330212 Info: = Prediction values for test #2 Info: Top(1) prediction is 3 with value: 0.98657 Info: Top(2) prediction is 0 with value: 1.51611e-05 Info: Total time for 3 test cases: 4.541 seconds Info: Average time per test case: 1513.509 ms Info: Overall accuracy: 1.000 ### Run with GPU/NPU backend $ TfInceptionV3-Armnn --data-dir=data --model-dir=models --compute=VsiNpu Info: ArmNN v20200200 , size = 1072812Warn-Start NN executionInfo: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 0.454892 Info: Top(2) prediction is 160 with value: 0.00278848 Info: Top(3) prediction is 131 with value: 0.000483917 Info: Top(4) prediction is 56 with value: 0.000304589 Info: Top(5) prediction is 27 with value: 0.00022049 Warn-Start NN executionInfo: = Prediction values for test #1 Info: Top(1) prediction is 283 with value: 0.481285 Info: Top(2) prediction is 282 with value: 0.268977 Info: Top(3) prediction is 151 with value: 0.000375891 Info: Top(4) prediction is 24 with value: 0.000367508 Info: Top(5) prediction is 13 with value: 0.000330214 Warn-Start NN executionInfo: = Prediction values for test #2 Info: Top(1) prediction is 3 with value: 0.986568 Info: Top(2) prediction is 0 with value: 1.51615e-05 Info: Total time for 3 test cases: 5.617 seconds Info: Average time per test case: 1872.355 ms Info: Overall accuracy: 1.000 ------------------------------- e). ONNX示例应用测试 ./ Image包含如下ARM NN ONNX模型测试示例,本文随机选择OnnxMobileNet-Armnn进行测试 /usr/bin/OnnxMnist-Armnn /usr/bin/OnnxMobileNet-Armnn ./部署模型和输入数据文件到模块 ------------------------------- ###从 这里 下载,mobilenetv2-1.0.onnx模型文件,部署到Apalis iMX8 ~/ArmnnTests/models;shark.jpg, Dog.jpg, Cat.jpg输入文件,部署到Apalis iMX8 ~/ArmnnTests/data $ cd ArmnnTests ### Run with C++ backend, CPU without NEON $ OnnxMobileNet-Armnn --data-dir=data --model-dir=models --compute=CpuRef Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 17.1507 Info: Top(2) prediction is 207 with value: 15.3666 Info: Top(3) prediction is 159 with value: 11.0918 Info: Top(4) prediction is 151 with value: 5.26187 Info: Top(5) prediction is 112 with value: 4.09802 Info: = Prediction values for test #1 Info: Top(1) prediction is 281 with value: 13.6938 Info: Top(2) prediction is 43 with value: 6.8851 Info: Top(3) prediction is 39 with value: 6.33825 Info: Top(4) prediction is 24 with value: 5.8566 Info: Top(5) prediction is 8 with value: 3.78032 Info: = Prediction values for test #2 Info: Top(1) prediction is 2 with value: 22.6968 Info: Top(2) prediction is 0 with value: 5.99574 Info: Total time for 3 test cases: 163.569 seconds Info: Average time per test case: 54523.023 ms Info: Overall accuracy: 1.000 ### Run with ACL NEON backend, CPU with NEON $ OnnxMobileNet-Armnn --data-dir=data --model-dir=models --compute=CpuAcc Info: ArmNN v20200200 Info: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 17.1507 Info: Top(2) prediction is 207 with value: 15.3666 Info: Top(3) prediction is 159 with value: 11.0918 Info: Top(4) prediction is 151 with value: 5.26187 Info: Top(5) prediction is 112 with value: 4.09802 Info: = Prediction values for test #1 Info: Top(1) prediction is 281 with value: 13.6938 Info: Top(2) prediction is 43 with value: 6.88511 Info: Top(3) prediction is 39 with value: 6.33825 Info: Top(4) prediction is 24 with value: 5.8566 Info: Top(5) prediction is 8 with value: 3.78032 Info: = Prediction values for test #2 Info: Top(1) prediction is 2 with value: 22.6968 Info: Top(2) prediction is 0 with value: 5.99574 Info: Total time for 3 test cases: 1.222 seconds Info: Average time per test case: 407.494 ms Info: Overall accuracy: 1.000 ### Run with GPU/NPU backend $ OnnxMobileNet-Armnn --data-dir=data --model-dir=models --compute=VsiNpu Info: ArmNN v20200200 , size = 602112Warn-Start NN executionInfo: = Prediction values for test #0 Info: Top(1) prediction is 208 with value: 8.0422 Info: Top(2) prediction is 207 with value: 7.98566 Info: Top(3) prediction is 159 with value: 6.76481 Info: Top(4) prediction is 151 with value: 4.16534 Info: Top(5) prediction is 60 with value: 2.40269 Warn-Start NN executionInfo: = Prediction values for test #1 Info: Top(1) prediction is 287 with value: 5.98563 Info: Top(2) prediction is 24 with value: 5.49244 Info: Top(3) prediction is 8 with value: 2.24259 Info: Top(4) prediction is 7 with value: 1.36127 Info: Top(5) prediction is 5 with value: -1.69145 Error: Prediction for test case 1 (287) is incorrect (should be 281) Warn-Start NN executionInfo: = Prediction values for test #2 Info: Top(1) prediction is 2 with value: 11.099 Info: Top(2) prediction is 0 with value: 3.42508 Info: Total time for 3 test cases: 0.258 seconds Info: Average time per test case: 86.134 ms Error: One or more test cases failed ------------------------------- f).除了上述推理引擎前端,TensorFlow Lite也是支持的,更多示例测试和参数说明以及ARMNN C++ API/Python API开发流程可以参考NXP i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 Chapter 5 Arm NN。 7). ONNX 测试 a). ONNX也是一款开源的机器学习推理引擎,NXP iMX8 eIQ ONNX支持特性和协议栈框图如下 ./ ONNX Runtime 1.1.2 ./ Multithreaded computation with acceleration using Arm Neon SIMD instructions on Cortex-A cores provided by the ACL and Arm NN execution providers ./ Parallel computation using GPU/NPU hardware acceleration (on shader or convolution units) provided by the VSI NPU execution provider ./ C++ and Python API (supported Python version 3) b).示例应用测试 ./ ONNX Runtime提供了一个onnx_test_runner(BSP以及预装于/usr/bin)用于运行ONNX model zoo提供的测试模型,下面几个模型是在iMX8 eIQ测试过的模型 MobileNet v2, ResNet50 v2, ResNet50 v1, SSD Mobilenet v1, Yolo v3 ./ MobileNet v2模型测试 ------------------------------- ###从这里下载模型文件压缩包,然后在Apalis iMX8设备上$Home目录解压出文件夹mobilenetv2-7 $ cd /home/root/ ### Run with ARMNN backend with CPU NEON $ onnx_test_runner -j 1 -c 1 -r 1 -e armnn ./mobilenetv2-7/ … Test mobilenetv2-7 finished in 0.907 seconds, t result: Models: 1 Total test cases: 3 Succeeded: 3 Not implemented: 0 Failed: 0 Stats by Operator type: Not implemented(0): Failed: Failed Test Cases: ### Run with ACL backend with CPU NEON $ onnx_test_runner -j 1 -c 1 -r 1 -e acl ./mobilenetv2-7/ … Test mobilenetv2-7 finished in 0.606 seconds, t result: Models: 1 Total test cases: 3 Succeeded: 3 Not implemented: 0 Failed: 0 Stats by Operator type: Not implemented(0): Failed: Failed Test Cases: ### Run with GPU/NPU backend $ onnx_test_runner -j 1 -c 1 -r 1 -e vsi_npu ./mobilenetv2-7/ … Test mobilenetv2-7 finished in 0.446 seconds, t result: Models: 1 Total test cases: 3 Succeeded: 3 Not implemented: 0 Failed: 0 Stats by Operator type: Not implemented(0): Failed: Failed Test Cases: ------------------------------- c).更多示例测试和参数说明以及C++ API可以参考NXP i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 Chapter 6 ONNX Runtime。 8). OpenCV 测试 a). OpenCV是大家熟知的一款开源的传统机器视觉库,它包含一个ML模块可以提供传统的机器学习算法,可以支持神经网络推理(DNN模型)和传统机器学习算法(ML模型),NXP iMX8 eIQ OpenCV支持特性如下 ./ OpenCV 4.4.0 ./ C++ and Python API (supported Python version 3) ./ Only CPU computation is supported ./ Input image or live camera (webcam) is supported b).示例应用测试 ./ BSP预装OpenCV测试模型数据如下 DNN示例应用- /usr/share/OpenCV/samples/bin 输入数据、模型配置文件- /usr/share/opencv4/testdata/dnn ./Image classification DNN示例应用测试 ------------------------------- ###从 这里 下载,模型文件squeezenet_v1.1.caffemodel和配置文件model.yml复制到/usr/share/OpenCV/samples/bin ###复制数据文件到执行目录 $ cp /usr/share/opencv4/testdata/dnn/dog416.png /usr/share/OpenCV/samples/bin/ $ cp /usr/share/opencv4/testdata/dnn/squeezenet_v1.1.prototxt/usr/share/OpenCV/samples/bin/ $ cp /usr/share/OpenCV/samples/data/dnn/classification_classes_ILSVRC2012.txt /usr/share/OpenCV/samples/bin/ $ cd /usr/share/OpenCV/samples/bin/ ### Run with default image $ ./example_dnn_classification --input=dog416.png --zoo=models.yml squeezenet ### Run with actual camera(/dev/video2) input ./example_dnn_classification --device=2 --zoo=models.yml squeezenet ------------------------------- c).更多示例测试和说明可以参考NXP i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 Chapter 8 OpenCV machine learning demos。 9). 总结 本文基于NXP eIQ机器学习工具库在iMX8嵌入式平台简单演示了多种机器学习推理引擎示例应用,并简单对比了CPU NEON和GPU进行模型推理的性能表现,实际进行相关应用开发的时候还会遇到很多学习模型到实际推理模型转换的问题,本文就不做涉及。 参考文献 i.MX Machine Learning User's Guide Rev. L5.4.70_2.3.0 i.MX Yocto Project User's Guide Rev. L5.4.70_2.3.0 https://developer.toradex.cn/knowledge-base/board-support-package/openembedded-core
-
每一个智能工厂,对于质检,安全都有工厂必须遵守的条例,良品率越高,对工厂带来的是纯利润的上升。我们一起分享在 TensorFlow 中,如何去解决现代工厂中面临的这一系列问题。 TensorFlow 与生产环境的关系 TensorFlow 是现在应用最广泛的深度学习开发库,经过几年的发展,版本的不断迭代,现在开发的功能已经逐步完善。在实际的工程化运行环境中间,除了我们利用人工智能去研发解决问题之外,我们还需要对人工智能进行工程化,使我们研发的人工智能模型,能够高效的运行在生产环境中间。 现在已经有许多大的互联网公司提供了人工智能从数据处理到模型开发及部署的基础设施,这些基础设施可以保证使用者运用比较好的公有云系统来完成人工智能研发。 互联网以及传统企业所积累的大数据,由于私密性,从数据的来源到人工智能模型的产生与应用,都只能在密闭的环境下进行内循环,最终的目的是用人工智能模型来服务企业本身,导致公有云上的基础设施无法为企业所用。那么整个人工智能系统都必须要在私有的环境下完成研发,生产到运维的所有过程。 谷歌所搭建的 KubeFlow 平台,正是解决人工智能在私有化应用中的问题,在企业私有云环境中间搭建了这么一套完整的运行完成之后,可以保证整个人工智能周期的私密性。 未来的人工智能发展一定是伴随着支撑人工智能的公有云设施及私有云设施相互促进相互发展的一个过程。 TensorFlow 将如何帮助提升良品率? 在智能生产领域中间不管哪个行业,只要它生产实际的产品,都会涉及到产品的质量检验这个过程,好的质量检验流程能够提升良品率。所以以往的质量检验一般是用一些自动化的设备,然后辅助人工进行整个检查的过程,但是在这个过程中间,由于自动化设备固定的识别模式,然后人由于不能长期的高效的维持在最好的状态之下进行检验,最后导致有一些产品,会出现漏检的现象。例如在电子元器件芯片行业中间芯片的检测是需要拿到显微镜下由人工去看,由于人的不稳定因素造成最后的检测结果会出现一些问题。引入人工智能的方式去做质量检测,会起到非常好的效果。 利用 TensorFlow 去进行质量检测,会有几种可行的办法: 一种就是利用计算机视觉去检测产品的外观,外观包括产品的变形,缺陷等。非常大的一个物体,以及显微镜观测的细小颗粒部分,都可以利用 TensorFlow 实时高精度的去完成检测。 另外一种是利用一些传感器或者是自动化设备,对产品进行一些常规的测试。存在的问题是,如果有多种因素做一个综合判定的时候,只能用经验来做判断,而这种判断需要公司的非常有经验的员工来参与,有经验的员工的培养本身就是一个巨大的成本。那么 TensorFlow 去处理这些问题,他可以把工人的经验转换成为人工智能的模型,最终使整个的检测过程不需要人工去干预。 TensorFlow 与物联网技术之间的联系 TensorFlow 可以看成是数据处理的一种方式,物联网是数据回环的一套基础架构。那么在物联网体系中,利用 TensorFlow 等人工智能技术去处理问题,会显得实时,便捷,高效。 这几年我们在生活过程中间越来越多的运用到人工智能技术。比如我们过机场地铁安检的时候人脸识别,用支付宝进行人脸识别付款,这些都是人工智能的应用。我们深深惊叹这些技术的便捷性的时候,实际上对完成人工智能处理设备来说,它就是相当于整个物联网系统中的一个端点设备,完成了数据的采集,识别过程。 除了人脸之外,还有我们的声音,文字,以及在生产过程中间所获得的各种数据,整个的人工智能的角度来讲,都是属于数据获取。往往数据的获取就是依赖整个物联网系统的端点设备,有的端点设备只是进行数据采集,但是有的端点设备除了进行数据采集之外,还会返回结果。那么从端点进行数据采集,对数据进行处理,进行人工智能的识别,最后再把结果下发了整个过程,就是物联网在实际的应用过程中的一个非常好的体现。 随着物联网的设备越来越多,物联网又具有去中心化的特点。那么我们把整个人工智能模型部署到云端进行数据识别,会对云端产生相当大的压力。所以在物联网的端点,或者是路由侧,通常会加入 TensorFlow 的模型用于识别。这样的话,数据不不需要实时的传送到云端进行处理,具有离线,实时性的特点。 针对物联网设备越来越丰富,需要大量的边缘设备去处理数据的特点, Google 在物联网方向,从云端到端点设备提供了丰富的 AI 解决方案。TensorFlow 的应用中,专门对移动端,嵌入式设备做了扩展,即大家熟悉的 TensorFlow Lite,除了软件层面,Google 在物联网的硬件端也推出了 Edge TPU, 这个硬件方案可以对物联网网关,端点的 AI 识别,同时也在基于单片机的应用中推了 Sparkfun 解决方案。更不用说云端 AI 相关的丰富的服务了。随着大量的物联网设备为人们的生活提供便携性的服务,AI 在我们的生活中,也就无处不在了。
-
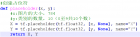
一、序言 前面已经逐步从单神经元慢慢“爬”到了神经网络并把常见的优化都逐个解析了,再往前走就是一些实际应用问题,所以在开始实际应用之前还得把“框架”翻出来,因为后面要做的工作需要我们将精力集中在业务而不是网络本身,所以使用框架可以减少非常多的工作量,有了前面自己实现神经网络的经验,现在理解框架的一些设置也比较容易了。本篇我们就使用比较常见的Tensorflow来重置一下前面的工作。 备注一下Tensorflow的安装: 1)安装python3.6,高版本不支持 2)pip install tensorflow即可 二、softmax 在开始前需要先说下这里使用的一个新的技术“softmax”,前面我们解决的问题是“从一堆图片里识别出数字是否是9”,这里使用softmax我们可以搞定更加高深一点的问题,比如: “识别出图片中的数字是几” 这就厉害了,前面我们只能识别是不是,即”二分类“,这里借助softmax我们可以识别图片是数字几的概率,即”多分类“。 从技术上来说其实变化不大,神经网络整体结构不变,但是还记得我们之前神经网络中使用的”激活函数“不?一般最后一层使用sigmoid,意思是将输出转为0-1之间的区间值,表示为”是数字9“的概率是多少。这里使用softmax替代sigmoid,此外输出也不是一个数,而是10个数,比如: 它的含义如下: 0的概率:10% 1的概率:20% 3的概率:30% 4的概率:70% ... 相应的输入的label自然也是十个数,比如: 它表示我们输入的图片是数字”4“,此种表示方式称为"one_hot_label"。此种输入与输出形式就是"多分类"的基础,此外我们使用的mnist数据集可以直接将label数据转为one hot形式,只需要"one_hot_label=True"。 除了输入输出形式不一样,softmax的传播函数和反向传播肯定与sigmoid不一样了,不过借助Tensorflow强大的功能这些我们都不需要操心啦。下面我们就逐步来实现一个基于Tensorflow的神经网络。 三、创建占位符placeholder 其实这里的输入x,y代表的分别是输入图片的向量大小784和label的向量大小10。tf是tensorflow的实体,这里tf.placeholder其实就是定义了两个空的数组: (784, None)和(10, None) placeholder得到的一维向量在后面的作用是"占位",占位的意思是在tensorflow构建神经网络时先把位置占好,真正运行时就按这个占位的样子往里面扔数据,比如X是784,输入的img也不管你啥形状了,反正就按784将输入截成一段一段的。 四、初始化参数w、b 整体上来说与前面初始化参数差不多,变化的除了使用tf来产生随机数,还将wGroup和bGroup合并为parameters(tf框架只给输入一个参数名)。 五、传播函数 这里tf.matmul()就是实现矩阵w与IN的乘积,再通过tf.add()实现加b。但这里的"传播函数"并没有真的做传播运算,它只是按神经网络的结构将各种运算”安排“好,运算到最后一层没有使用激活函数来计算结果,而是直接返回A。剩下的运算放到了”损失函数“中。 六、损失函数 这里的tf.transpose()只是一个转置操作,之所以不用A.T这种方式,其实可以想到,此处的A并不是一个矩阵,它是一长串计算的结果,只有当神经网络运行起来了A才会是一个矩阵。所以这里的A其实是一系列“运算”的合集,使用tf.transpose()就是叠加了一个转置运算。 tf.reduce_mean()在这里就是计算"损失"的,不过暂时也不是真的计算了,只是将这个运算"安排"好了,最终结果返回为costFun 七、完整实现 等等,还没有说"反向传播"呢?不要慌,这里慢慢来。 在model中,placeholder、initialize_parameters、forward、costCAL都是前面讲过的,只是"构建"神经网络计算的过程。 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(costFun) 这一句就是构建反向传播,其中AdamOptimizer表明使用Adam优化算法,minimize指明使用的损失函数,其实总结起来就是我们的反向传播需要使用Adam优化算法来使costFun构建的损失函数趋向于最小。 _ , cost = sess.run( , feed_dict={X: train_img, Y: train_label}) 这一句就是真的运行网络了,feed_dict就是按前面"占位符"的形状将train_img和train_label输入到网络中, 是指明网络的“向前传播+反向传播”和损失计算。 parameters = sess.run(parameters) 只是将优化后的参数按原样输出回来。 八、总结 本节只是简单将之前实现过的神经网络用Tensorflow再实现了一次,其次还引入了softmax将二分类扩展为多分类。Tensorflow是后面研究的基础,可能再开一章单独讲一讲。 本节完整实现代码请关注公众号“零基础爱学习”回复AI14获取。
-
第一次阅读本专题的朋友可移步,阅读之前的文章: 物联网到底是什么? 完美支持 Android Things 的开发板都在这里了 Android Things 开发环境搭建 Android 与 Android Things,父子还是兄弟? Android Things中的I2C 前面絮叨了这么多,好像还没有一个总体的概念,我们如何写一个完整的代码呢? 现在深度学习很火,那我们就在 Android Things 中,利用摄像头抓拍图片,让 TensorFlow 去识别图像,最后用扬声器告诉我们结果。 是不是很酷?说基本的功能就说了这么长一串,那垒代码得垒多久啊? 项目结构 我们就从 Android Studio 的环始境开始说起吧。 启动 Android Studio 之后,务必把 SDK Tools 的版本升级到 24 及以上。然后再把 SDK 升级到 Android 7.0 及以上。让 Android Studio 自己完成相关组件的更新,导入项目,项目的结构如下: 代码中的 TensorflowImageClassifier 是用于跟 TensorFlow 做交互的,还有摄头的 handler 级及图像处理相关的代码。我们再来看看外部的引用库。 包括了 Android Things 和 TensorFlow 的相关库,当然,Android 的 API 的版本是24。gradle 的依赖和 Manifest 中的 filer 是和之前搭建开发环境的讲解一致的。 引用的 TensorFlow 的库,是 aar 打包的 Tensorflow-Android-Inference-alpha-debug.aar,这就意味着我们不需要 NDK 环境就能够编译整个项目了。 主要是留意 dependencies 这一项,包括了 TensorFlow 的库和 Android Things 的库: 再申请了摄头相关的权限。补充一下,Android Things 是不支持动态权限的申请的。 硬件连接 接下来便是硬件如何连接了。 硬件清单如下: Android Things 兼容的开发板,比如 Raspberry Pi 3 Android Things 兼容的摄像头,比如 Raspberry Pi 3 摄头模块 元器件: 1 个按钮,见面包板 2 个电阻,这块儿必须要说明一下:由于硬件连接的示意图是接的 5V 的电压,一般来说 GPIO 和 LED 的承压能力是 3V,有些 GPIO 是兼容 5V 的,所以中间需要串联 100~200 欧的电阻。 1 个 LED 灯 1 个面包板 杜邦线若干 可选:扬声器或者耳机 可选:HDMI输出 连完了硬件,我们这时候就要理解操作流程了。 操作流程 按照前面讲解的内容,用 Andorid Studio,连接 ADB,配置好开发板的 Wi-Fi,然后把应用加载到开发板上。 操作流程如下: 重启设备,运行程序,直到 LED 灯开始闪烁; 把镜头对准猫啊,狗啊,或者一些家具; 按下开关,开始拍摄图片; 在 Raspberry Pi 3 中,一般在 1s 之内,可以完成图片抓拍,经 Tensorflow 处理,然后再通过 TTS 放出声音。在运行的过程中 LED 灯是熄灭的; Logcat 中会打印出最终的结果,如果是有显示设备连接的话,图片和结果都会显示出来; 如果有扬声器或者是耳机的话,会把结果语音播报出来。 由于代码的结构特别简单,注意一下几段关健的操作即可。想必图形、摄头的操作在Android 的编程中大家都会了,所以不做讲解了。 主要是看 LED 的初始化操作: 有必要说一下,ImageClassifierActivity 是应用唯一的 Activity 的入口。在 Manifest 中已经有定义,它初始化了 LED, Camera, TensorfFlow 等组件。其中,我们用到的 Button 是 BCM32 这个管脚,用到的 LED 是 BCM6 管脚,相关的初始化在这个 Activity 中已经完成。 这部分代码是捕捉按键按下的代码。当按下按键时,摄头开始捕捉数据。 把摄像头拍摄的数据转成 Bitmap 数据之后,我们会调用 TensorFlow 来处理图像。 这个函数调用了 TensorFlow 进行处理,最后把结果输出到 logcat 中。如果代码中调用了 tts 引擎,那么则把结果转成语音读出来。看来,最重要的就是 TensorFlowClassifier 类的 recognizeImage() 这个接口了。我们继续往下看。 这是最后的一步,调用 TensorFlow 进行图像识别: 把 Bitmap 图像转成 TensorFlow 能够识别的数据; 把数据拷到 TensorFlow 中; 识别出图像,给出结果。 调用 TensorFlow 的过程还是挺好玩的,也挺方便。那么,为啥 TensorFlow 一下子就能够识别出是什么图片呢?Tensorflow 的官网给出的解答: www.tensorflow.org/tutorials/image_recognition 有一点需要提示,TensorFlow 的图像识别分类可以用提交到网络服务器识别,也可以在本地用离线数据识别。可以先把 200M 左右的识别数据放在本地,然后进行本地识别。现在大概能分出 1000 个类别的图像,哪 1000 个类别呢?项目代码中已经包含了哦。 是不是运用 TensorFlow 来处理物联网的数据会特别简单,不光是 TensorFlow, Firebase 也可以用到 Android Things 中来。这功能,强大的没话说了! 今天提到的这个项目,来源于 Google 在 GitHub 上维护的项目,项目的地址是 github.com/androidthings/sample-tensorflow-imageclassifier 当然,GitHub 上还有很多 Android Things 的代码可以参考。 是不是迫不急待的自己写一个应用呢?实际上,这个项目稍加改动便能有新的玩法。例如加上一个红外感应器,一旦有生物在附近就马上拍图片,并且识别。 展开你的脑洞吧 :-) 后记 这一篇文章是这个专题的最后一篇了。写完整个专题,发现 Android Things 带给开发者太多太多的便利,如何烧写文件?如何运用 SDK?甚至如何用 Google 的其它服务做物联网相关的数据处理?都有太多太多的现成的方案供我们选择,感叹使用 Android Things 进行物联网应用开发实在太方便了! 您如果有任何涉及到 Android Things 方面的想法,都欢迎大家在下方留言,我们会把好的建议转交给 Android Things 的产品部门。也许在某一天,你的建议就是 Andorid Things 的一部分。
相关资源
-

-
TensorFlow深度学习从入门到进阶-张德丰
-
深度学习全书:公式+推导+代码+TensorFlow-全程案例-陈昭明(epub格式,附阅读器安装程序)
-
走向TensorFlow2.0:深度学习应用编程快速入门-赵英俊(epub格式,附阅读器安装程序)
-
TensorFlow深度学习算法原理与编程实战-蒋子阳
-
TensorFlow:实战Google深度学习框架-郑泽宇-顾思宇
-
-
分布式人工智能:基于TensorFlow、RTOS与群体智能体系
-
基于TensorFlow框架的语音控制移动机器人实训项目设计.
-
-
-
基于TensorFlow的四旋翼无人机着陆地标识别
-
内容简介TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用。本书为TensorFlow入门参考书,旨在帮助读者以快速、有效的方式上手TensorFlow和深度学习。书中省略了烦琐的数学模型推导,从实际应用问题出发,通过具体的TensorFlow示例介绍如何使用深度学习解决实际问题。书中包含深度学习的入门知识和大量实践经验,是走进这个前沿、热门的人工智能领域的优选参考书。第2版将书中所有示例代码从TensorFlow0.9.0升级到了TensorFlow1.4.0。在升级API的同时,第2版也补充了更多只有TensorFlow1.4.0才支持的功能。另外,第2版还新增两章分别介绍TensorFlow高层封装和深度学习在自然语言领域应用的内容。本书适用于想要使用深度学习或TensorFlow的数据科学家、工程师,希望了解深度学习的大数据平台工程师,对人工智能、深度学习感兴趣的计算机相关从业人员及在校学生等。图书在版编目(CIP)数据TensorFlow:实战Google深度学习框架/郑泽宇,梁博文,顾思宇著.—2版.—北京:电子工业出版社,2018.2ISBN978-7-121-33066-7Ⅰ.①T…Ⅱ.①郑…②梁…③顾…Ⅲ.①人工智能-算法-研究Ⅳ.①TP18中国版本图书馆CIP数据核字(2017)第285250号
-
AlphaGo如何战胜人类围棋大师——智能硬件TensorFlow实践清华出版社高清PDF书籍
-
图书在版编目(CIP)数据从AI模型到智能机器人:基于Python与TensorFlow/高焕堂著.—北京:电子工业出版社,2019.9ISBN978-7-121-37011-3
-
-
21个项目玩转深度学习:基于TensorFlow的实践详解
-
-
Tensorflow实战Google深度学习框架
-
《机器学习实战:基于Scikit-Learn和TensorFlow》高清中文PDF内容简介本书主要分为两个部分。第一部分为第1章到第8章,涵盖机器学习的基础理论知识和基本算法——从线性回归到随机森林等,帮助读者掌握Scikit-Learn的常用方法;第二部分为第9章到第16章,探讨深度学习和常用框架TensorFlow,一步一个脚印地带领读者使用TensorFlow搭建和训练深度神经网络,以及卷积神经网络。作者简介AurelienGeron是机器学习方面的顾问。他曾是Google软件工程师,在2013年到2016年主导了YouTube视频分类工程。2002年和2012年,他还是Wifirst公司(一家法国的无线ISP)的创始人和首席技术官,2001年是Ployconseil公司(现在管理电动汽车共享服务Autolib)的创始人和首席技术官。


