热度 16
2023-6-29 10:08
1134 次阅读|
0 个评论
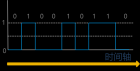
前言 实现延时通常有两种方法:一种是硬件延时,要用到定时器 / 计数器,这种方法可以提高 CPU 的工作效率,也能做到精确延时;另一种是软件延时,这种方法主要采用循环体进行。 01 使用定时器 / 计数器实现精确延时 单片机系统一般常选用 11.0592MHz 、 12 MHz 或 6MHz 晶振。第一种更容易产生各种标准的波特率,后两种的一个机器周期分别为 1 μ s 和 2 μ s ,便于精确延时。本程序中假设使用频率为 12MHz 的晶振。 最长的延时时间可达 216=65536 μ s 。若定时器工作在方式 2 ,则可实现极短时间的精确延时;如使用其他定时方式,则要考虑重装定时初值的时间(重装定时器初值占用 2 个机器周期)。 在实际应用中,定时常采用中断方式,如进行适当的循环可实现几秒甚至更长时间的延时。使用定时器 / 计数器延时从程序的执行效率和稳定性两方面考虑都是最佳的方案。 但应该注意, C51 编写的中断服务程序编译后会自动加上 PUSH ACC 、 PUSH PSW 、 POP PSW 和 POP ACC 语句,执行时占用了 4 个机器周期;如程序中还有计数值加 1 语句,则又会占用 1 个机器周期。这些语句所消耗的时间在计算定时初值时要考虑进去,从初值中减去以达到最小误差的目的。 02 软件延时与时间计算 在很多情况下,定时器 / 计数器经常被用作其他用途,这时候就只能用软件方法延时。下面介绍几种软件延时的方法。 短暂延时 可以在 C 文件中通过使用带 _NOP_( ) 语句的函数实现,定义一系列不同的延时函数,如 Delay10us( ) 、 Delay25us( ) 、 Delay40us( ) 等存放在一个自定义的 C 文件中,需要时在主程序中直接调用。如延时 10 μ s 的延时函数可编写如下: void Delay10us( ) { _NOP_( ); _NOP_( ); _NOP_( ); _NOP_( ); _NOP_( ); _NOP_( ); } Delay10us( ) 函数中共用了 6 个 _NOP_( ) 语句,每个语句执行时间为 1 μ s 。主函数调用 Delay10us( ) 时,先执行一个 LCALL 指令 (2 μ s) ,然后执行 6 个 _NOP_( ) 语句 (6 μ s) ,最后执行了一个 RET 指令 (2 μ s) ,所以执行上述函数时共需要 10 μ s 。 可以把这一函数当作基本延时函数,在其他函数中调用,即嵌套调用 ,以实现较长时间的延时;但需要注意,如在 Delay40us( ) 中直接调用 4 次 Delay10us( ) 函数,得到的延时时间将是 42 μ s ,而不是 40 μ s 。 这是因为执行 Delay40us( ) 时,先执行了一次 LCALL 指令 (2 μ s) ,然后开始执行第一个 Delay10us( ) ,执行完最后一个 Delay10us( ) 时,直接返回到主程序。依此类推,如果是两层嵌套调用,如在 Delay80us( ) 中两次调用 Delay40us( ) ,则也要先执行一次 LCALL 指令 (2 μ s) ,然后执行两次 Delay40us( ) 函数 (84 μ s) ,所以,实际延时时间为 86 μ s 。简言之,只有最内层的函数执行 RET 指令。 该指令直接返回到上级函数或主函数。如在 Delay80 μ s( ) 中直接调用 8 次 Delay10us( ) ,此时的延时时间为 82 μ s 。通过修改基本延时函数和适当的组合调用,上述方法可以实现不同时间的延时。 在 C51 中嵌套汇编程序段实现延时 在 C51 中通过预处理指令 #pragma asm 和 #pragma endasm 可以嵌套汇编语言语句。用户编写的汇编语言紧跟在 #pragma asm 之后,在 #pragma endasm 之前结束。 如: #pragma asm … 汇编语言程序段 … #pragma endasm 延时函数可设置入口参数,可将参数定义为 unsigned char 、 int 或 long 型。根据参数与返回值的传递规则,这时参数和函数返回值位于 R7 、 R7R6 、 R7R6R5 中。在应用时应注意以下几点: #pragma asm 、 #pragma endasm 不允许嵌套使用; 在程序的开头应加上预处理指令 #pragma asm ,在该指令之前只能有注释或其他预处理指令; 当使用 asm 语句时,编译系统并不输出目标模块,而只输出汇编源文件; asm 只能用小写字母,如果把 asm 写成大写,编译系统就把它作为普通变量; #pragma asm 、 #pragma endasm 和 asm 只能在函数内使用。 将汇编语言与 C51 结合起来,充分发挥各自的优势,无疑是单片机开发人员的最佳选择。 使用示波器确定延时时间 利用示波器来测定延时程序执行时间。方法如下:编写一个实现延时的函数,在该函数的开始置某个 I/O 口线如 P1.0 为高电平,在函数的最后清 P1.0 为低电平。在主程序中循环调用该延时函数,通过示波器测量 P1.0 引脚上的高电平时间即可确定延时函数的执行时间。方法如下: sbit T_point = P1^0; void Dly1ms(void) { unsigned int i,j; while (1) { T_point = 1; for(i=0;i<2;i++) { for(j=0;j<124;j++){;} } T_point = 0; for(i=0;i<1;i++) { for(j=0;j<124;j++){;} } } } void main (void) { Dly1ms(); } 把 P1.0 接入示波器,运行上面的程序,可以看到 P1.0 输出的波形为周期是 3ms 的方波。其中,高电平为 2ms ,低电平为 1ms ,即 for 循环结构“ for(j=0;j<124;j++) {;} ”的执行时间为 1ms 。通过改变循环次数,可得到不同时间的延时。当然,也可以不用 for 循环而用别的语句实现延时。这里讨论的只是确定延时的方法。 使用反汇编工具计算延时时间 用 Keil C51 中的反汇编工具计算延时时间,在反汇编窗口中可用源程序和汇编程序的混合代码或汇编代码显示目标应用程序。为了说明这种方法,还使用: for (i=0;i C:0x000FE4CLRA//1T C:0x0010FEMOVR6,A//1T C:0x0011EEMOVA,R6//1T C:0x0012C3CLRC//1T C:0x00139FSUBBA,DlyT //1T C:0x00145003JNCC:0019//2T C:0x00160E INCR6//1T C:0x001780F8SJMPC:0011//2T 可以看出, 0x000F ~ 0x0017 一共 8 条语句,分析语句可以发现并不是每条语句都执行 DlyT 次。核心循环只有 0x0011~0x0017 共 6 条语句,总共 8 个机器周期,第 1 次循环先执行“ CLR A ”和“ MOV R6 , A ”两条语句,需要 2 个机器周期,每循环 1 次需要 8 个机器周期,但最后 1 次循环需要 5 个机器周期。 DlyT 次核心循环语句消耗 (2+DlyT × 8+5) 个机器周期,当系统采用 12MHz 时,精度为 7 μ s 。 当采用 while (DlyT--) 循环体时, DlyT 的值存放在 R7 中。相对应的汇编代码如下: C:0x000FAE07MOVR6, R7//1T C:0x00111F DECR7//1T C:0x0012EE MOVA,R6//1T C:0x001370FAJNZC:000F//2T 循环语句执行的时间为 (DlyT+1) × 5 个机器周期,即这种循环结构的延时精度为 5 μ s 。 通过实验发现,如将 while (DlyT--) 改为 while (--DlyT) ,经过反汇编后得到如下代码: C:0x0014DFFE DJNZR7,C:0014//2T 可以看出,这时代码只有 1 句,共占用 2 个机器周期,精度达到 2 μ s ,循环体耗时 DlyT × 2 个机器周期;但这时应该注意, DlyT 初始值不能为 0 。 注意:计算时间时还应加上函数调用和函数返回各 2 个机器周期时间。 举例程序段落 系统频率: 6MHz Delay: MOV R5,#25 ; 5ms 延时 —— MOV 指令占用 1 机器周期时间 Delay1: MOV R6,#200 ; 200ms 延时 Delay2: MOV R7,#166 ; 1ms 延时常数 Delay3: NOP ;空指令,什么都不做,停留 1 机器周期时间 DJNZ R7,Delay3 ; R7 减 1 赋值给 R7 ,如果此时 R7 不等于零,转到 Delay3 执行。—— 2 机器周期时间 DJNZ R6,Delay2 DJNZ R5,Delay1 解析如下: 首先计算机器周期 T=12*1/f=2 μ s 。 注意 DJNZ R7,Delay3 每执行 1 次需要占用 NOP 的时间和 DJNZ 本身的时间共 3 个机器周期。 6 μ s 。那么 1ms 的时间需要 1ms*1000/6 μ s=166.67 ,取 166 。 注意 DJNZ R6,Delay2 是在 166 次循环后执行 1 次的 ( 时间为 MOV 机器周期 + 本身机器周期, 3*2=6 μ s) ,直到 166*200 次后, R6=0 ,才执行 DJNZ R5,Delay1 。 DJNZ R5,Delay1 是在 R5 不为 0 的时候循环回去。时间也为 6 μ s 。 时间总计: 166*200*25*6 μ s+200*25*6 μ s+25*6 μ s=5010150 μ s ,合计 5.01015ms( 编程的人都遇到过类似的潜逃循环,此程序忽略了执行 MOV 的时间,只计算了循环所用时间,即 166*200*25*6/1000000=4.98ms ,近似 5ms) 。 程序改进:去掉 NOP 命令,整数化 1ms 需要的延时常数。 Delay: MOV R5,#25 ; 5ms 延时 —— MOV 指令占用 1 机器周期时间 Delay1: MOV R6,#200 ; 200ms 延时 Delay2: MOV R7,#250 ; 1ms 延时常数 Delay3: ;NOP ;空指令,什么都不做,停留 1 机器周期时间 DJNZ R7,Delay3 ; R7 减 1 赋值给 R7, 如果此时 R7 不等于零,转到 Delay3 执行。—— 2 机器周期时间 DJNZ R6,Delay2 DJNZ R5,Delay1 此时时间总计: 250*200*25*4 μ s+200*25*6 μ s+25*6 μ s=5030150 μ s 。时间占用误差反而比未改进的时候大,可修正,将 R7-30150/(25*200*4)=248( 因为 R7=250 循环 1 次占用 2 个机器周期, 4 μ s ,计算等于 R7-1.5075, 将时间减小到小于 5ms ,剩余时间另补,取 248) 。则: 时间总计: 248*200*25*4 μ s+200*25*6 μ s+25*6 μ s=4990150 μ s , 需要补: 5000000-4990150=9850 μ s , 9850/2=4925 机器周期。 补一个 MOV R4,#200 , 4 个 NOP ,还需 4920 机器周期,将其约分,得到 24*205=4920 。 如何建立函数根据实际代码调整,如下: Delay: MOV R5,#25 ; 5ms 延时 —— MOV 指令占用 1 机器周期时间 Delay1: MOV R6,#200 ; 200ms 延时 Delay2: MOV R7,#250 ; 1ms 延时常数 Delay3: ;NOP ;空指令,什么都不做,停留 1 机器周期时间 DJNZ R7,Delay3 ; R7 减 1 赋值给 R7, 如果此时 R7 不等于零,转到 Delay3 执行。—— 2 机器周期时间 DJNZ R6,Delay2 DJNZ R5,Delay1 NOP NOP NOP NOP MOV R3,#6 Delayadd: MOV R4,#205 MOV R2,#0H DJNZ R3,Delayadd 解析 205*24 调整为 205*6 —— 这是因为 Delay 循环为 4 机器周期代码,因此将 24/4=6 。 请计算: 205*6*4=4920;4920+5=4925 。时间补充正好。 此时时间计算: 248*200*25*4 μ s+200*25*6 μ s+25*6 μ s=4990150 μ s+4925*2 μ s=5000000 μ s 合计 5ms 。 理论上 1 μ s 都不差 ( 仅为科学探讨,具体晶振频率的误差多大作者并不明确 ) 。 关注公众号“优特美尔商城”,获取更多电子元器件知识、电路讲解、型号资料、电子资讯,欢迎留言讨论。

 标签: 波特率
标签: 波特率