
 在L1 数据缓存层次实现存储一致性模型,如MESI,MOESI, 对于MIPS32 1004K 一致处理系统来说,使用了开放核协议OCP, 点到点连接, 建立基于监听的一致性.
在L1 数据缓存层次实现存储一致性模型,如MESI,MOESI, 对于MIPS32 1004K 一致处理系统来说,使用了开放核协议OCP, 点到点连接, 建立基于监听的一致性.
1004k mesi pdf
在嵌入式多核集群中利用OCP处理高速缓冲器一致流量 |
| Leveraging OCP for Cache Coherent Traffic within an Embedded Multi-core Cluster |
| 作者:Matthias Knoth MIPS科技公司 时间:2008-08-14 来源: 电子产品世界 浏览评论 |
摘要:随着处理性能的提升超出了单核系统的频率和功率范围,导致了多核集群的出现。MIPS科技的MIPS32 1004K一致处理系统(CPS)采用开放内核协议(OCP)点对点连接,可在整个集群中建立基于侦听的一致性。本文详细介绍这种通信模型的原理。
Matthias Knoth:设计工程师,负责低功耗、微架构和1004K处理器方案。
源于一种基于消息的存储一致模型
传统上,多处理器系统中的存储器一致性都是通过总线侦听实现的,每个内核都与一个通用多层总线连接,能够侦听同级处理器的存储器存取流量,以调节每个高速缓冲器行的一致状态。这样,每个内核都在本地保持了L1高速缓冲器行的一致状态,并通过通用总线将状态的改变通知同级处理器。
SoC不断增加的面积和复杂性导致了多层总线基本哲学的改变,以利于采用集中流量路由的本地点对点连接。由于负载的减少和段长的缩短,这将有助于显著加速和推动现在的本地化总线段的改善。同时,也可以缓解总线争用问题,同时增加了本地化数据交换吞吐量。为了满足这一系统架构趋势,出现了OCP(开放内核协议)标准,进一步巩固了这一设计哲学。另外,IP供应商业务模式的出现催化了IP互连和设计方法的标准化,有利于在一个开放标准基础上实现设计的复用。
然而,与通过OCP互连段操控一样,本地化总线执行将整个多核集群上的处理器分拆开。一致方案不能直接基于总线侦听和依赖总线仲裁来确保存取排序,需要不同的通信方法来确保数据存取的一致性。在争用L1行数据请求排序的过程中,其他挑战也浮现出来。应对这些挑战的一种方法是给每个处理单元增加一致消息通信,如图1所示。这些消息提供了侦听型缓冲器一致的方法。
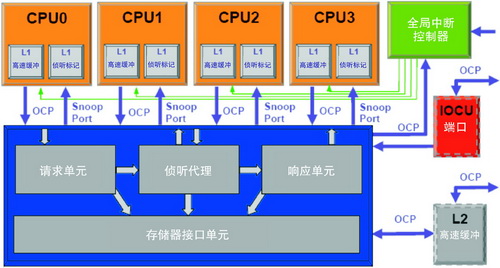
图 1 一致处理系统
一致消息包含了OCP协议中的一个新命令。处理器系统中的成员向一个集中一致管理器发送一致消息。该管理器提供存取排序(顺序化)和消息路由,为同级成员提供侦听型存取。这些同级成员将以其单独的L1行状态进行响应,并发出一个消息响应。根据这些响应,一致管理器发起对内核间一致数据的数据移动,将存取集中在更高级别的存储器层,如L2和L3高速缓冲器。I/O一致单元还可提供一种方式逐渐采用/逐渐淘汰数据进/出一致地址空间的数据,它是一致消息交换的一部分。
除了OCP协议中的新消息类命令外,还需要具体的处理器响应一致状态请求,因此它们不只是总线处理的发动者(主控)。一致处理系统满足这一要求的方法可能是通过提供一个OCP从端口来接收和响应一致管理器发送的消息。处理器的一致请求将利用OCP主端口。在处理集群内,内核间和一致管理器之间的一致消息交换被称为“干预”。处理器的OCP从端口接收干预,因此称为“干预端口”。
如图1所示,1004K系统的每个独立处理器都是基于我们多线程处理器架构的,可以在单标量、9级流水线范围内提供两个独立线程并处理上下文。复制的1级数据高速缓冲器标记阵列可同时用于存取CPU操作和干预查寻。一致处理系统可支持MESI型高速缓冲器行一致性。
处理系统一致管理器通过其请求单元—OCP从端口,在每个CPU和I/O一致单元的推动下,接收进入的消息并对其进行串化。串化的消息按照其地址空间和上下文,或使用“存储器接口单元”发送到更高级别的高速缓冲器层,或使用“侦听代理”发送至同级处理器和I/O一致单元。侦听代理发起OCP主处理(干预)来查寻每个处理器的一致L1高速缓冲器行状态。干预返回到消息发起者,称为自我干预,有助于发起者提供存取排序。对 CPU 发起的一致消息响应和数据响应是在“响应单元”内确立的,并发送到每个 CPU。
一致OCP命令
第一类是保持MESI型高速缓冲器行状态的一致消息。它们是CPU负载/存储操作的结果,能够发起CPU和/或存储器子系统之间的数据移动。CPS(一致处理系统)的所有同级CPU将接收由一个发起者发送的一致消息,并根据它们的高速缓冲器行一致状态做出响应。一致管理器将根据需要发起数据移动。
一致高速缓冲器操作指令用于一致地址空间内高速缓冲器行的维护。I/O流量将新的一致行带入该域,或将一致上下文从高速缓冲器行中移除。另外,还要进行存储器层的同步化操作。
第三类是非一致命令,在一致地址空间外的存储区中执行OCP主端口处理。它们代表了OCP读写命令。
一致消息
一致处理系统可能执行四个一致消息,这四个消息是由CPU负载/存储活动产生的L1高速缓冲器行状态变化导致的。发起的CPU将这个消息以OCP主端口命令发送。系统的同级CPU接收基于该行状态变化的干预,并以其本地高速缓冲器行状态进行响应。
第一种消息类型是CohReadOwn,表示在尝试修改高速缓冲器行时发生的高速缓冲器的不命中。同级内核遇到处于“修改”状态的该行时,会强制回写到存储器子系统中,并执行本地失效。作为优化,本地遇到的行数据将被转发到请求方 CPU,以降低存取延迟。请求方CPU将使该行作为“专有”行,并执行行修改指令。然后,高速缓冲器行状态将变成“修改过的”。在等待行重新填满的时候,请求方CPU将继续另一个线程的执行。
一致读取共享(CohReadShared)消息表明在读行操作过程中发生的高速缓冲器不命中。不需要行修改。遇到“已修改”状态的该行的同级内核将强制回写到存储器子系统。命中的同级行将转换到“共享”状态。命中数据将被转发到请求方内核,并以“共享”状态安装。然后执行读行操作。在等待行重新填满的时候,请求方CPU将继续另外一个线程的执行。
一致升级(CohUpgrade)消息表明遇到命中“共享”行的一个高速缓冲器行修改指令。同级内核将收到通知取消命中行。在修改指令执行完以后,“共享”行会随之升级为“修改”行。
最终,一致回写(CohWriteBack)消息表示驱逐了一个一致高速缓冲器行。一致管理器将通过干预端口发起数据移动,并将数据转发到存储器子系统。被驱逐的高速缓冲器行随后便由一个新的—可能是一致的—地址取代。在这种情况下,CohReadOwn或CohReadShared导致了这个驱逐。
一致高速缓冲器操作指令
为了响应高速缓冲器操作,需要发起一致消息,并发送到同级内核。
·CohCopyBack—将一致高速缓冲器行回写到存储子系统。
·CohInvalidate—清除一致高速缓冲器行,而不是将其内容回写到存储子系统。
·CohWriteInvalidate—I/O一致单元在一个新的高速缓冲器行注入一致域。
·CohReadInvalidate — I/O一致单元通知系统,高速缓冲器行将离开一致域。
·CohCompletionSync—无数据的命令可以保持排序。
非一致命令
传统的OCP命令,如“读取”和“写入”命令是由整个一致处理系统支持的,以处理非一致存储器存取的数据存取。当高速缓存的、非一致地址内的命中失败,或者非高速缓存存取引发存储子系统内的读取操作时,就会发出读命令。如果响应数据是作为非一致高速缓存安装的话,那么非高速缓存数据就会直接被消耗掉。提取和负载/存储活动可导致读取处理。当高速缓存的、非一致逐出数据或非高速缓存地址范围存储被写入存储子系统时,即发出写入命令。内核的 OCP 主端口执行命令和数据阶段的处理。
实例—一致读取共享消息
CPU0 在一致高速缓存行上遇到负载不命中,并发起 cohReadShared 消息(无修改意图)。一致管理器将干预消息发送到所有内核,在此内核 1 将响应“修改”的命中。一致管理器现在发起了一个修改行回写,将行数据从内核 1 中的干预端口移动到存储子系统。命中的内核 1 高速缓存行转移到“共享”状态(见图2)。行数据移动也会转发到内核 0,在此它可在“共享”状态下安装。
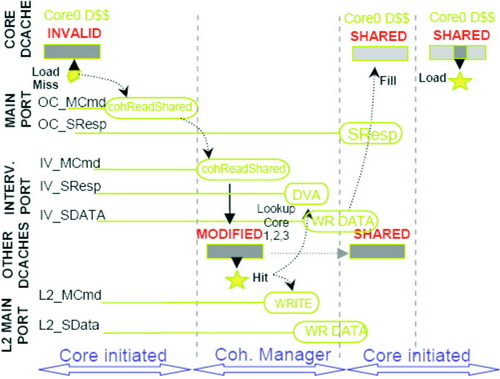
图2 一致读取共享消息
结语
OCP互连有助于支持基于消息的一致方案。集中的一致管理器可以串化从单独内核发出的一致消息,并询问同级内核的一致状态。内核之间的数据转发可减少存取延迟和对更高级别的存储器层的流量。单个内核支持OCP主端口发起数据存取和OCP从端口接收来自一致管理器的询问。
参考文献:
1. OCP规范2.2,2006 OCP-IP协会,版权所有
2. OCP一致扩展,第二部分:信号和解码(未发表、初稿)
3. MIPS32 1004K一致处理系统用户手册,MIPS科技公司
 | 标签: 嵌入式 SoC 1004K OCP 一致处理 高速缓冲器一致 多核 |
随着超深亚微米工艺的发展, IC设计能力与工艺能力极大提高,采用SoC(System on Chip)将微处理器、IP核、存储器及各种接口集成在单一芯片上,已成为目前IC设计及嵌入式系统发展的趋势和主流。为减少设计风险、缩短设计周期、更集中于应用实现,设计者越来越多的采用IP核复用。在此推动下,IP核互连技术及片上总线(On-Chip Bus)得到迅速发展,反过来它们又对IP核的设计、校验、重用及IP核有关标准的制定也产生了深远的影响。
IP核互连策略
就IP核互连的形式而言,主要有共享总线、点对点的连接及多总线几种方式,带宽、时延、数据吞吐率及功耗通常是几个需主要考虑的因素。
共享总线方式是通过不同地址的解码来完成不同主、从部件的互连及总线复用,这对多外设 IC系统设计而言,对地址总线的扇出提出了较高的要求,同时过于复杂的解码逻辑会增加额外的时延。如果数据主要集中在一个主处理器与一个从外设交换数据,则其他的外设在此期间需处于IDEL 或高阻状态,而对于多处理器设计的系统,其他的数据传输不能同时进行,增加了时延及等待。
通过增加总线的宽度、提高总线的时钟以及采用多总线方案可以解决带宽、时延问题。但增加总线的宽度,只有外围设备在一个时钟周期中能全部占有这些总线时才有效,否则总线的利用率就不高,而提高总线的时钟也会受到一定的限制,同时会产生功耗方面的问题。
一个有效的办法就是采用多总线方案。多总线的方案有多种实现形式,按不同速率对总线分段可以减少总线的竞争并且提高总线利用率;可采用独立的读写总线以进行同时的读写;可提供多个并行的总线,对主、从部件间进行点对点的连接,以实现一对主、从部件的高速互连;另外还有一些有效的方式,如采用分层总线构架,采用交换矩阵或互连网络,来实现多个主、从部件的同时互连,等等。多种总线仲裁算法可以被采用。采用循环占用总线,实现最为简单;另外采用从部件仲裁( Slave-side arbitration)的方案,在从部件需要数据传送时占有总线,有利于提高总线的利用率。对于流水线传送较多的情况,如何保证读写的流水线执行以减少时延也是总线仲裁考虑的一个重要方面。
下面就目前一些互连规范及它们采用的方案作介绍。
主要的 IP核互连规范
目前有较大影响的 IP核互连规范有IBM的CoreConnect总线、ARM的AMBA(Advanced Microcontroller Bus Architecture)、Silicore Corp的Wishbone、开放核心协议国际联合(OCP-IP)的OCP (Open Core Protocol)与虚拟插座接口连盟VSIA (Virtual Socket Interface Alliance)的VCI(Virtual Component Interface)、Altera的Avalon总线, 以及PlamchIP的CoreFrame 、MIPS的ECTM Interface, Altera的AtlanticTM Interface、IDT的IPBusTM (IDT Peripheral Bus)、Sonics的SiliconBackplaneTM μNetwork等,新的互连方案如基于PCI的方案也在积极发展中,下面就前面几种予以介绍。
IBM的CoreConnect总线
CoreConnect总线的逻辑结构如图1所示。CoreConnect采用了总线分段的方式,提供了三种基本类型总线,即处理器内部总线PLB(Processor Local Bus)、片上外围总线OPB(On-Chip Peripheral Bus)和设备控制总线DCR(Device Control Register)。PLB提供了一个高带宽、低延迟、高性能的处理器内部总线;OPB则用于连接具有不同的总线宽度及时序要求的外设和内存;DCR用来在CPU通用寄存器与设备控制寄存器之间传输数据,以减少PLB的负荷,增加其带宽。

ARM的AMBA总线
AMBA总线的逻辑结构如图2所示。同CoreConnect相似,AMBA也采用分段多总线体系,定义了三种不同类型的总线:AHB、ASP和APB。AHB用于高性能、高数据吞吐部件,如CPU、DMA、DSP之间的互连,ASP用来作处理器与外设之间的互连,APB则为系统的低速外部设备提供低功耗的简易互连。系统总线和外设总线之间的桥接器提供AHB/ASP部件与APB部件间的访问代理与缓冲。

Silicore的Wishbone总线
Wishbone逻辑结构如图3所示。Wishbone采用的是主/从的构架,主、从部件通过内连网络进行互连。

ishbone更着重定义IP核的接口信号和总线周期标准以实现IP核的重用,而对主从部件互连的内连网络,它只是定义了点到点(point-to-point)、数据流(data flow)、共享总线(shared bus)、交叉开关(crossbar switch)四种不同形式,需由用户来灵活选择、生成、扩展,用户还可用两条Wishbone总线进行复杂系统的集成。 目前www.opencores.org上很多共享IP都采用了该总线协议
OCP-IP的OCP
OCP 的IP核互连结构图如图4所示。OCP是基于定义一套完整通用IP核插座接口标准的互连方案,通过定义IP核与对应接口模块间点到点的接口信号协议,如数据信号、边带信号和测试信号等,来实现IP核的可重用、即插即用、认证及测试,及不同IP核接口的集成,点到点的接口方式简单且可完成数据的高速传输。对连接各接口模块的片上内连总线形式,OCP未作定义,由用户来扩展。

VSIA同OCP相仿,也通过定义IP核的接口及点对点的方式来实现不同IP核的互连。OCP对接口定义更为完整,并且兼容VSIA,可以认为VSIA是OCP的一个子集。两个VCI通过总线互连的逻辑结构示意如图5所示。

Altera的Avalon总线
Avalon总线是Altera 可编程片上系统SoPC(system-on-a-programmable chip)IP核互连解决方案,SoPC Builder 来完成整个系统模块(包括Avalon)的生成和集成。集成的系统示意图如图6所示。

其中 Avalon总线模块完成了整个可编程系统片上部件及外设之间互连,包括了控制、数据、地址信号及总线的仲裁。Avalon总线模块的一个逻辑示例如图7所示。

Avalon采用了开关结构及从部件仲裁方式提供对主部件的同时互连,外部件与Avalon时钟同步操作,使用非三态总线,主、从部件间多种带宽互连,支持数据流传输。Avalon同时对总线信号的定时、主从部件传输的信号作了定义,以便于不同IP核的集成。 Altera大部分结构复杂的IP都采用该标准。


 /2
/2 





文章评论(0条评论)
登录后参与讨论