
一般低成本的FPGA(如Cyclone系列,Spartan系列)由4输入的LUT表完成组合逻辑的功能,即相当于一个16bit存储空间,4bit地址输入,1bit输出的RAM,我们通过配置者16bit的空间完成任意一个“四输入一个输出的逻辑表达式”;如我们需要完成Out = ABCD(四输入与门),配置数据为“0x8000”,即当查找地址“4b’1111”,RAM的输出为1,否则为零。
假如我需要实现一个加法器,并输出它的进位值Carry,分别用逻辑电路和配置数据表示?
如果我们只有三个输入值,LUT的输入又该如何完成?
在数字电路中,信号的传递会出现延迟,延迟有逻辑门本身造成的,由于逻辑门中的三极管在传输信号时存在延迟;延迟也会因外部电路的分布电容而产生,所以逻辑门的输出信号要滞后输入信号。
与非门平均传输延迟时间是指一个数字信号从输入端输入,经过门电路再从其输出端输出所延迟的时间,它反映了电路传输信号的速度。
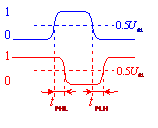
为了测试方便,都以电压波形摆幅的二分之一处为起始点去测量平均延迟时间。从输入上升边50%到输出下降边50%为止的时间叫做导通延迟时间tPHL;从输入下降边50%到输出上升边50%为止的时间叫做截止延迟时间tPLH。导通延迟时间和截止延迟时间的平均值称为平均延迟时间(如上图)
标准TTL门的平均传输延迟时间的典型值约10ns。
本身任何数字电子技术都是基于TTL技术发展起来的,当然,当今数字技术以CMOS技术为主,所以本身LUT从地址输入到存储值的输出也存在延迟,这也是影响FPGA工作频率的重要因素,随着技术的不断进步,该延迟对FPGA工作频率并不起着关键的作用。
现在我们举个更复杂的例子,两个32-bit数据的比较器:
从逻辑表达式上来看,我们需要作如下步骤:
temp[31..0] = ain[31..0] xor
bin[31..0];
equal = not (temp[31] or temp[30] … or temp[1]
or temp[0]);
以下是用VHDL实现,并用FPGA实现的方式:
library ieee;
use
ieee.std_logic_1164.all;
use
ieee.std_logic_unsigned.all;
use
ieee.std_logic_arith.all;
entity comparator_32b is
port(
ain:
in std_logic_vector(31 downto
0);
bin:
in std_logic_vector(31 downto
0);
equal:
out std_logic;
great:
out std_logic
);
end comparator_32b;
architecture synlogic of comparator_32b
is
begin
equal <= '1' when ain = bin else
'0';
--
great <= '1' when ain > bin else '0';
end synlogic;
在综合报告中可以知道,它需要21个逻辑资源即LUT;如下图:

描述一下“great <= '1' when ain > bin
else '0';”的综合流程?
经过上述描述,我们可以知道FPGA的综合流程,即根据你描述的逻辑功能,将逻辑分成若干个步骤,让它们适用于在LUT中完成,然后为每个LUT生成配置数据,通过连接每个LUT,最终完成逻辑功能。也许你也看得出来,从{ temp[31..0] = ain[31..0] xor bin[31..0] equal = not
(temp[31] or temp[30] … or temp[1] or temp[0])}到LUT,虽然它们完成都是相同的功能,但是从它们所耗费的逻辑门有很大的差距,如果直接用逻辑表达式,我们需要31个XOR门,30个OR门,而每个LUT的每个bit等效于4个门,即4门/bit;所以FPGA需要21*16*4个门,从逻辑成本上FPGA无法像ASIC一样大批量的生产,但是FPGA的可配置性,使得它允许你在设计可以有错误,而不像ASIC,流片出来后就无法修改,而每次流片所需要的费用已经达到100万美元(65nm),是中小企业无法承受的费用,如果错误的设计流入市场,所产生的维护费用更是难以估量,例如,Nvidia在第二季度一次性支出1.96亿美元,用来解决用于笔记本电脑的某些型号的上一代MCP(媒体通信处理器)和GPU(图形处理器)产品之“核心与封装材料不足”的问题;从而造就FPGA在很多专业领域的流行。


 /5
/5 



用户377235 2012-9-18 09:12
用户1596712 2011-11-27 15:14
用户209125 2009-1-13 15:35