
转自ilove314
http://blog.ednchina.com/ilove314/31798/category.aspx
ISE时序约束笔记1——Global Timing Constraints<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
时序约束和你的工程
执行工具不会试图寻找达到最快速的布局&布线路径。——取而代之的是,执行工具会努力达到你所期望的性能要求。
性能要求和时序约束相关——时许约束通过将逻辑元件放置的更近一些以缩短布线资源从而改善设计性能。
没有时序约束的例子
 <?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
该工程没有时序约束和管脚分配
——注意它的管脚和放置
——该设计的系统时钟频率能够跑到50M
时序约束的例子

和上面是相同的一个设计,但是加入了3个全局时序约束。
——它最高能跑到60M的系统时钟频率
——注意它大部分的逻辑的布局更靠近器件边沿其相应管脚的位置
更多关于时序约束
时序约束应该用于界定设计的性能目标
1. 太紧的约束将会延长编译时间
2. 不现实的约束可能导致执行工具罢工
3. 查看综合报告或者映射后静态时序报告以决定你的约束是否现实
执行后,查看布局布线后静态时序报告以决定是否你的性能要求达到了——如果约束要求没有达到,查看时序报告寻找原因。
路径终点
有两种类型的路径终点:
1. I/O pads
2. 同步单元(触发器,锁存器,RAMs)
时序约束的两个步骤:
1. 路径终点生产groups(顾名思义就是进行分组)
2. 指点不同groups之间的时序要求
全局约束使用默认的路径终点groups——即所有的触发器、I/O pads等
ISE时序约束笔记2——Global Timing Constraints
问题思考
单一的全局约束可以覆盖多延时路径
如果箭头是待约束路径,那么什么是路径终点呢?
所有的寄存器是否有一些共同点呢?

问题解答
什么是路径终点呢?
——FLOP1,FLOP2,FLOP3,FLOP4,FLOP5。
所有的寄存器是否有一些共同点呢?
——它们共享一个时钟信号,约束这个网络的时序可以同时覆盖约束这些相关寄存器间的延时路径。
周期约束
周期约束覆盖由参考网络钟控的的同步单元之间的路径延时。
周期约束不覆盖的路径有:input pads到output pads之间的路径(纯组合逻辑路径),input pads到同步单元之间的路径,同步单元到output pads之间的路径。

周期约束特性
周期约束使用最准确的时序信息,使其能够自动的计算:
1. 源寄存器和目的寄存器之间的时钟偏斜(Clock Skew)
2. 负沿钟控的同步单元
3. 不等同占空比的时钟
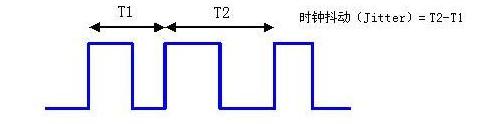
4. 时钟的输入抖动(jitter)
假设:
1. CLK信号占空比为50%
2. 周期约束为10ns
3. 由于FF2将在CLK的下降沿触发,两个触发器之间的路径实际上将被约束为10ns的50%即5ns
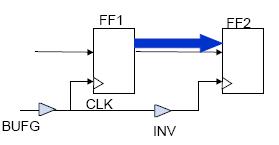
时钟输入抖动(Clock Input Jitter)
时钟输入抖动是源时钟的不确定性(clock uncertainty)之一
时钟的不确定时间必须从以下路径扣除:
——周期约束建立时间路径
——OFFSET IN约束的建立时间路径
时钟的不确定时间必须添加到以下路径中:
——周期约束保持时间路径
——OFFSET IN约束保持时间路径
——OFFSET OUT约束路径
Pad-to-Pad约束
——不包含任何同步单元的纯组合逻辑电路
——纯组合逻辑延时路径开始并结束于I/O pads,所以通常会被我们遗漏而未约束
ISE时序约束笔记3——Global Timing Constraints
问题思考
哪些路径是由CLK1进行周期约束?
哪些路径是由pad-to-pad进行约束?
OFFSET约束
OFFSET约束覆盖以下路径:
——从input pads到同步单元(OFFSET IN)
——从同步单元到output pads(OFFSET OUT)

OFFSET约束特性
OFFSET约束自动计算时钟分布延时
1. 提供最准确的时序信息
2. 大量增加输入信号到达同步单元的时间(时钟和数据路径并行)
3. 大量减少输出信号到达输出管脚的时间(时钟和数据路径先后)
OFFSET约束也可以解释时钟输入抖动——使用抖动确定关联的周期约束
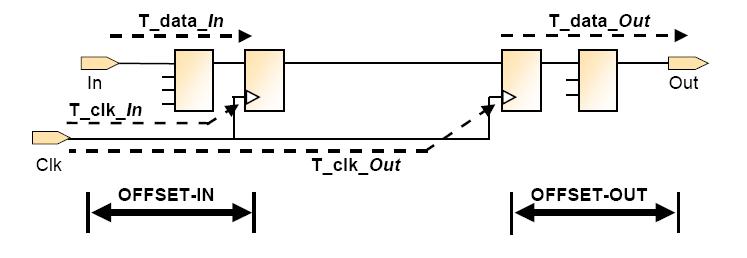
时钟延时
数据路径延时和时钟分布延时都需要在OFFSET计算中使用到
——OFFSET IN = T_data_in – T_clk_in
——OFFSET OUT = T_data_out + T_clk_out
ISE时序约束笔记4——Global Timing Constraints
问题思考
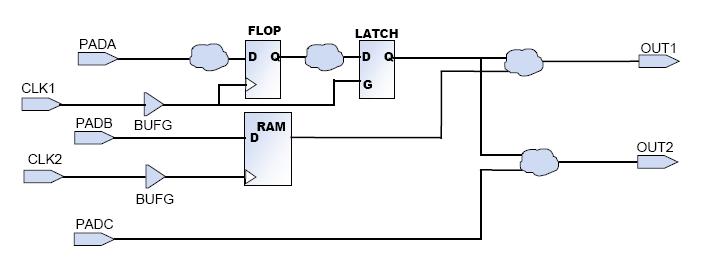
在这个电路中哪些路径是由OFFSET IN 和 OFFSET OUT来约束的?
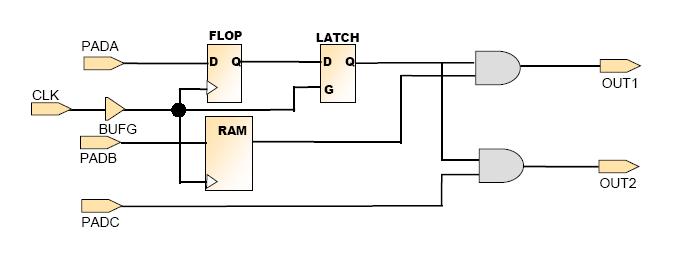
问题解答:
——OFFSET IN:PADA to FLOP and PADB to RAM
——OFFSET OUT:LATCH to OUT1, LATCH to OUT2, and RAM to OUT1
问题思考
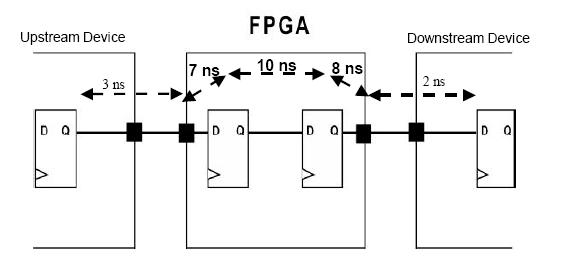
下面给出的系统框图里,你将给出什么样的约束值以使系统能够跑到100MHz?
——假设在下面的器件之间没有时钟偏斜

问题解答:
PERIOD = 10 ns , OFFSET IN (BEFORE) = 7 ns and OFFSET OUT (AFTER) = 8 ns
小结
1. 性能期望和时序约束相关联
2. 周期约束覆盖同步单元之间的延时路径
3. OFFSET约束覆盖从输入管脚到同步单元和从同步单元到输出管脚之间的延时路径
ISE时序约束笔记5——Timing Groups and OFFSET Constraints
特定路径时序约束
使用全局时序约束(PERIOD,OFFSET,PAD-TO-PDA)将约束整个设计
仅仅使用全局约束通常会导致过约束
——约束过紧
——编译时间延长并且可能阻止实现时序目标
——通过综合工具或者映射后时序报告重新审视性能评估
特定路径约束能够覆盖全局时序约束在特定路径上的约束
——这就允许设计者放宽特定路径的时序要求
更多关于特定路径约束
你的设计器件的内部面积将会从特定路径约束收益
1. 多周期路径Multi-cycle paths
2. 跨时钟域路径
3. 双向总线
4. I/O时序
特定路径约束应该由你的性能目标来界定,不能够不加限制的随意放置
全局约束回顾
使用全局PERIOD,OFFSET IN和OFFSET OUT约束将约束所有以下的路径
这使得控制设计的总体性能更加容易

特定路径约束实例
一条特定路径约束对于路径本身的优化微乎其微
这有助于你更好的控制设计性能,并带给执行工具更大的灵活性以达到你的性能和使用要求
生成特定路径约束需要两个步骤:
1. 多个有共同时序要求的特定路径终点生成一个groups
2. 关联两个groups,指定它们的特定路径的时序要求
生成终点路径的Groups
特定路径时序约束在终点路径较好的分组后会更加高效——否则,约束一个大的工程将极其耗时耗力。
约束编辑有助于你更容易的进行路径终点(pads, flip-flops, latches, and RAMs)进行Groups分组。
使用约束编辑器,终点路径的分组有以下选项:
– Group by nets
– Group by instance name
– Group by hierarchy
– Group by output net name
– Timing THRU Points option
– Group by clock edge
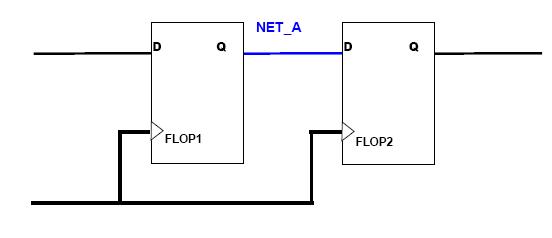
Nets 分组与output net name分组对比
由net分组的 “NET_A”将生成一个只包含FLOP2的group
——Group包含选择网络所驱动的寄存器
由output net name分组的“NET_A”将生成一个只包含FLOP1的group
——Group包含选择网络的源寄存器
ISE时序约束笔记6——Timing Groups and OFFSET Constraints
回顾全局OFFSET约束
在时钟行中使用Pad-to-Setup和Clock-to-Pad列为所有出于该时钟域的I/O路径指定OFFSETs。
为大多数I/O路径进行约束的最简单方法——然而,这将会导致一个过约束的设计。
指定管脚的OFFSET约束
使用Pad-to-Setup和Clock-to-Pad列为每个I/O路径指定OFFSETs。
这种约束方法适用于只有少数管脚需要不同的时序约束。
更常用的方法是:
1. 为Pads生成Groups
2. 对生成的指定Groups进行OFFSET IN/OUT约束
双沿时钟的OFFSET约束
OFFSET约束指明了FPGA管脚的输入数据和初始时钟之间的关系。
初始时钟沿在周期约束定义中出现关键词“高”和“低”。
——高:初始时钟上升沿(默认),即上升沿锁存数据
——低:初始时钟下降沿
如果所有的I/O都由时钟的一个沿控制,那么你可以使用这个关键字高或低进行周期约束。
如果两个沿都用到,你就必须进行两个OFFSET的约束。
——每个OFFSET对应一个时钟沿
——DDR寄存器也是这样使用的一个例子
双沿时钟的OFFSET IN约束
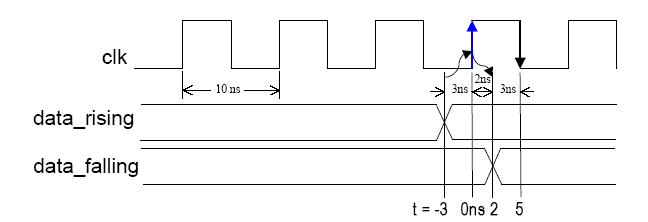
输入数据在上升沿或者下降沿之前3ns有效——周期约束为10ns,初始上升沿,占空比为50%。
为每个时钟沿生成一个时钟Groups
——输入时钟的上升沿,OFFSET = IN 3ns BEFORE CLK;
——输入时钟的下降沿,OFFSET = IN -2ns BEFORE CLK;(在初始时钟的上升沿后2ns = 时钟下降沿前3ns)
双沿时钟的OFFSET OUT约束
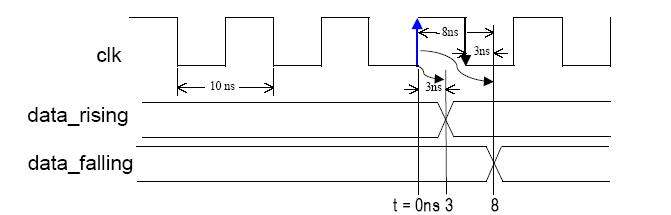
输出数据必须在时钟的上升沿或者下降沿后3ns内有效——周期约束为10ns,初始上升沿,占空比为50%。
为每个时钟沿生成一个时钟Groups
——输入时钟的上升沿,OFFSET = OUT 3ns AFTER CLK;
——输入时钟的下降沿,OFFSET = OUT 8ns AFTER CLK;(在初始时钟的上升沿后8ns = 时钟下降沿后3ns)
问题思考
特定路径时序约束如何改善了设计性能?
你如何约束这个设计使其内部时钟频率达到100 MHz?
输入(数据)将在时钟CLK的上升沿到达前3ns内有效。输出数据必须在时钟CLK的下降沿后4ns内有效。写出合适的OFFSET约束?

问题解答
特定路径时序约束如何改善了设计性能?
——它使得执行工具更加灵活的达到你的时序要求。
你如何约束这个设计使其内部时钟频率达到100 MHz?
——给时钟信号CLK施加一个10ns的全局周期约束。
写出合适的OFFSET约束?
——OFFSET = IN 3 ns BEFORE CLK; OFFSET = OUT 9 ns AFTER CLK;
ISE时序约束笔记7——Path-Specific Timing Constraints
时钟上升沿和下降沿之间的时序约束
周期约束可以自动计算两个沿的的约束——包括调整非50%占空比的时钟。
例:一个CLK时钟周期约束为10ns,能够应用5ns的约束到两个寄存器之间。
不需要特定路径应用到这个例子中。

相关时钟域的约束
为一个时钟进行周期约束——以这个周期约束确定相关的时钟。
执行工具将根据它们的关系来决定如何处理跨时钟域。
DCM有多个输出:
——确定DCM输入时钟的周期约束
——执行工具将会从这个周期约束推导出其输出的约束
——所有的约束将会和原始的周期约束相关
不相关时钟域的约束
在这个例子中,周期约束不覆盖到处于两个时钟域之间的任何延时路径。——这是默认的处理方式。
你必须添加一个约束覆盖到相关时钟域之间的路径中。——例如,频率相同,但是CLK_B有一些相位偏移。
在两个不相关的时钟域你就必须添加一些同步电路。
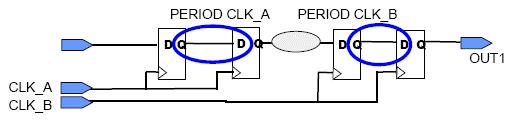
约束两个时钟域之间的路径。
——使用Groups by NETs选项为CLK_A和CLK_B定义groups,如果你为每个时钟添加完周期约束,这个步骤将自动完成。
——在这个寄存器的groups之间指定快速/慢速例外约束。
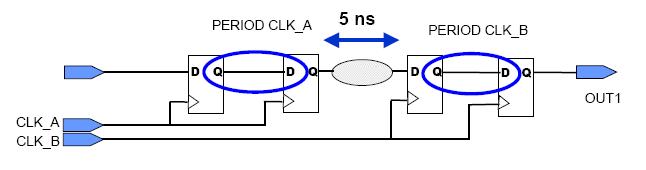
多周期路径约束
多周期约束应用在连续几个时钟周期内寄存器不需要更新的情况。
——总是至少需要一个时钟周期才更新。
——通常的,这样的寄存器由时钟使能信号控制。
一个分段计数器就是这样的一个例子。
——COUT14每隔4个时钟周期才更新一次。
——这些寄存器间的路径就算是多周期路径。

False 路径
False路径选项将用于防止约束覆盖到特定路径
时序约束优先级
从高到低为:
1. False路径——将会覆盖任何其它的约束路径
2. FROM THRU TO
3. FROM TO
4. 管脚指定OFFSETs
5. Groups OFFSETs(由寄存器或者PADS生产的groups)
6. 全局PERIOD和OFFSETs——最低优先级约束
这里特权同学提醒大家注意的是,通常类似下面这样的计数器绝对不可以归为多周期约束:
reg[15:0] counter;
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n) counter <= 16’d0;
else counter <= counter+1’b1;
end
虽然我们想想似乎counter[1]也是2个clk变化一次,counter[2]也是4个clk变化一次……但是,我们想想看,如果从counter=1到counter=2没有在一个clk完成,那么肯定就会影响到counter=2到counter=3的变化,对吧?所以,这样的计数器不能算做多周期约束例外。
提纲里描述的多周期例外的计数器应该是这样一个模型:
reg[15:0] counter;
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n) counter[1:0] <= 2’d0;
else counter[1:0] <= counter[1:0]+1’b1;
end
always @ (posedge clk or negedge rst_n)
begin
if(!rst_n) counter[15:2] <= 14’d0;
else if(counter[1:0] == 2’b11) counter[15:2] <= counter[15:2]+1’b1;
end
上面两个always块里的数据互不干扰,并且都正常工作,只有下一个always块检测到前一个always块里的counter[1:0]==2’b11时才进位加1。
写到这里,特权发现单从功能上来说,这两个例子是没有差别的,说白了,任何一个计数器都可以建模成后面的形式。或者说,我的问题其实没有说明白,反而被自己的例子给驳倒了。
呵呵,换个角度思考这个问题,到底什么时候是多周期例外,什么时候不是?这个其实还是要看情况的,如果你的系统实时性较高,可能会在某一特定的时钟周期用到16位计数器的计数值(如a = (counter == 16’hffff)?1b’1:1’b0; ),那么这个计数器的高位就不能算作多周期例外。而如果比如在我的一个工程里,有这样的计数器用法:cuonter[2:0]没16个clk的后8个clk需要自增加(从0到15),而高位counter[18:3]当然只有在16个clk变化一次,因为这里counter是用于作为一个地址产生器,也就是说,我的地址是每16个clk的后8个clk用到,那么这里的counter[18:3]就是一个8clk的多周期例外实例。
说白了,还是要具体问题具体分析。
ISE时序约束笔记8——Achieving Timing Closure
题记:achieving timing closure即达到时序收敛,这是一个很具有挑战性的任务。因为实际的工程项目往往不会像我们用一个资源超大(相对于你的设计来说)的FPGA来做几个数码管串口实验那么简单。设计者往往需要达到成本、速度、资源等各个方面的平衡,即使是一个小设计,有时候也是很费神的。特权同学前几周在饱经ISE4里才有的老器件的折磨后,感慨良多。
关于时序报告
ISE中的时序报告分为两种:
– Post-Map Static Timing Report
– Post-Place & Route Static Timing Report
所谓Post-Map是布局后(没有布线)的静态时序报告,主要用于估计设计的性能,然后提前对设计做一些必要的修改。因为设计的实现(布局布线)是很消耗时间的。Post-Place & Route就是布局布线后的一个比较接近实际板级的一个静态时序报告了,这算是设计者进行时序分析的最终依据。
关于性能估计
综合报告
1. 准确的逻辑延时;
2. 基于扇出的布线延时估计
3. 报告的性能是实际的20%误差内
Post-Map静态时序报告
1. 准确的逻辑延时
2. 基于最快的可能的布线资源的布线延时估计
3. 使用了60/40规则来计算更趋近于实际的性能估计
60/40法则:
1. 这是一个时序约束合理性的经验法则;
2. 打开Post-Map静态时序报告,查看时序报告中关于逻辑延时的百分比
——低于60%,时序很有机会到达时序约束要求
——60%到80%,如果使用了高级选项,时序也很有机会达到时序要求
——80%以上,基本上很难(回到综合部分,或者重新优化你的代码)
Post-Place & Route时序分析
找出时序违规的因素有很多:
1. 设计的综合不当或者代码风格太烂;
2. 糟糕的综合结果(路径中的逻辑太繁杂)
3. 不准确或者不完整的时序约束
4. 糟糕的逻辑映射和布局
每个问题都用不同的解决方案:
1. 重写代码
2. 添加时序约束(注意应该是一些时序例外)
3. 使用不同的软件选项重新综合或者实现
准确的定位时序报告能够解决大多数问题。
一些可能的问题和解决
布线延时太长——似乎有些路径扇出很低,但是延时却很大,那么很可能这个地方的布线比较拥堵。解决办法:如果是不相关的逻辑布局到一块,可以到Floorplanner中查看。(这个问题特权同学还没有完全领会也是比较头疼的,希望看到更多更好的资料或者自己在工程中有更多体会时再和大家分享)
高扇出问题——解决办法是复制高扇出的网络。如果是组合逻辑,那么就比较难了。
逻辑级数太高——这个问题综合工具无法做太多优化。首先查看是否该路径为多周期路径,如果是,添加多周期例外;使用retiming选项更加均匀的分配触发器之间的逻辑;确定一个比较好的代码技巧被运用到了你的设计代码中;使用流水线设计。
I/O时序问题——使用DCM移除时钟分布延时; 将输入输出相关的寄存器放入IOB寄存器中。
另外在实际应用中,其实很是有很多可以应用的技巧的,比如实现属性选项里其实是可以设置布局布线的努力程度,还有布局布线的次数等待,对于大多数设计而言这些工具都是有用的。




 /4
/4 








文章评论(0条评论)
登录后参与讨论