

人工智能编码
尽管软件被认为是“吞噬世界”,但由于开发人才的获取和构建软件所需任务数量的增加,它在这样做方面受到了严重限制。需要软件开发人员的工作数量正在以远远超过进入市场填补这些职位的熟练专业人员数量的速度增长。即使对于那些已经担任程序员角色的人来说,他们的大部分时间也不一定花在编写新功能上,而是花在编写测试、修补安全问题、审查代码和修复错误上。这两个因素使得提高劳动力的生产力变得更加重要,而人工智能驱动的自然语言处理 (NLP) 模型的最新改进正在使这成为现实。凭借它们的规模、底层架构、训练数据和制度,最新一代最先进的 NLP 模型——称为生成式预训练转换器 (GPT)——可以在多种语言之间进行翻译,包括从文本到代码。事实证明,将这种强大的能力嵌入到开发人员可以使用的工具中,对于使开发人员更好地完成工作以及为技术水平较低的人解锁软件生产方面具有无可估量的价值。
软件努力吞噬世界
随着过去十年来各种用例和业务应用程序软件的爆炸式增长,需要编码经验来构建该软件的工作数量也出现了相应的增长。Code.org 在 2017 年进行的一项调查显示,仅在美国,估计就有 500,000 个开放的编程职位,但不幸的是,很多职位空缺,特别是因为每年只有 43,000 名计算机科学专业的毕业生进入市场,这一数字近年来有所下降. 最重要的是,通常需要 3 到 5 年的时间才能具备足够的技能来从事这些工作;当程序员准备担任更高级的角色时,可用角色的数量将增加 28%(美国劳工统计局)。像这样,
一旦开发团队在公司内就位,挑战就不会停止。构建软件的要求越来越复杂,尤其是在质量、安全性和交付速度方面。令人惊讶的是,开发人员只会花费大约 30%–40% 的时间来开发新功能或改进现有代码 (Newstack)。这是因为他们的大部分工作还包括编写测试、进行修复和解决安全问题。高级开发人员还将花费一部分时间指导团队中的初级人员并执行代码审查。所有这些元素结合在一起会影响软件项目的交付速度和成本效益。它还提供了将 AI 与人类开发人员配对以帮助解决许多此类缺点的绝佳机会。
AI + 开发人员 = 编程梦之队
人工智能驱动的编码器工具
随着基于深度学习的 NLP 在过去几年取得的长足进步,出现了许多以 AI 为核心的工具,旨在提高开发人员的生产力和代码质量。特别是,这些工具使用的模型可以解析代码以识别错误和缺陷,从而有效地执行代码审查中一些比较乏味的部分。最近发布的一些此类工具,如 CodeGuru 和 DeepCode,能够发现人类难以识别的漏洞,并发现所研究的拉取请求中有 50% 存在问题 (AI-News)。
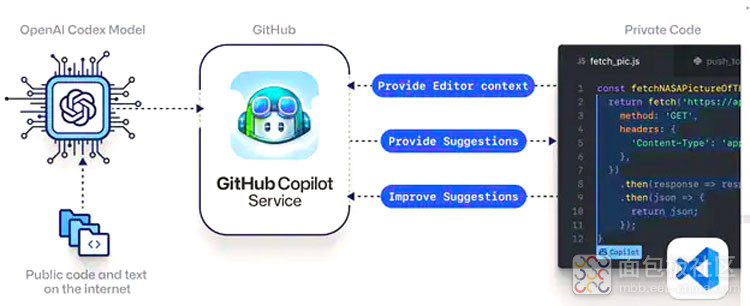
此外,现代 NLP 技术通过帮助自动完成代码部分、监控代码输出错误,甚至自动生成单元测试,提高了开发人员的代码质量并加快了开发速度。OpenAI 的 Codex 算法被整合到 GitHub 的 Copilot 中,可以以惊人的准确性做到这一点,甚至可以根据人类语言输入生成代码(图 1)。它这样做的能力来自于它接受训练的数据,包括自然语言片段和大量代码。GitHub 对其性能的初步研究表明,对于像编写 HTTP 服务器这样的普通任务,与开发人员一起利用 AI 可以将完成时间缩短一半。
编码更容易获得
新一代 NLP 模型强大的 AI 翻译能力意味着,在一定范围内,任何人都可以使用人类语言生成他们需要的代码片段。这些软件也可以使用任何编程语言,从用于执行某些例程(如 Python、JavaScript 和 C++)的语言到用于访问各种数据库(如 SQL 和 NoSQL)中的数据的语言。如果一个人想要编写的程序不是太复杂,像 Codex 这样的工具可能会有所帮助。事实证明,它对于制作小型网站、派生 excel 函数以及将用户想要的内容从人类语言转换为用于访问数据的查询语言非常有用。然而,正如这些技术的研究人员所指出的,这些模型并不总是完全正确的。经常,生成的代码大部分是正确的,但需要有经验的开发人员进行一些干预。从这个意义上说,这些模型可以提高人类编码导师的工作效率,因为它们可以接管人工智能遇到问题的地方,因为它正在被经验不足的人使用。这也可能意味着初级开发人员的生产力大大提高,同时他们对监督和高级投入的需求减少。
从人类语言到计算机语言
那么这些工具中的大多数是如何工作的呢?为这些创新工具提供动力的主要动力是 GPT——通常是此类模型的第三代,称为 GPT-3。该架构最初由 OpenAI 开发,并基于来自互联网的大量文本进行训练,包括散文、数字书籍、推文、开源存储库、评论、在线文章等。尽管目标总是更现实的语言生成,但模型也能够生成代码的副作用导致了 Codex 的后期开发。
有几个因素将 GPT 生成与以前基于深度学习的 NLP 模型区分开来。这些包括用于训练的数据量和训练模型的方式,以及模型具有的参数数量及其最先进的底层架构。由于这些模型及其前身是神经网络,参数的数量会影响它们可以捕获的数据中关系的复杂性,这意味着较大的模型可以比较小的模型学习更多细微差别的模式。这些模型还在多任务环境中以自我监督的方式接受了训练。大多数神经网络都是为执行单一任务而设计的,因此会采用专门标记的数据来学习如何完成该任务——一个很好的例子是 AlphaGo,它擅长围棋但不会下国际象棋。需要标记数据称为监督学习。相比之下,GPT-3 经过训练可以预测序列中的下一个单词,因此数据不需要标记;这是翻译、文本生成和问答等许多任务的支柱。
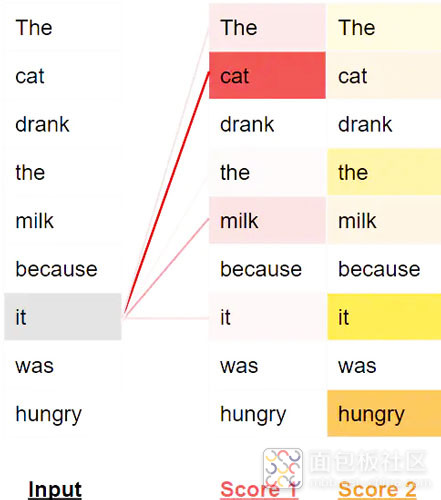
此外,还有 Transformer 模型,其性能优于之前的 NLP 基准测试,例如长短期记忆模型或递归神经网络。他们一次处理整个句子而不是逐字处理,在称为“注意力”的机制中存储和使用单词之间的相似性分数,并对与句子中标记的特定位置相关的信息进行编码(图 2)。所有这些都允许更大的模型可以学习更多,因为并行化和递归不再像过去那样成为问题。它还消除了以前的模型在忘记相隔很远的单词和句子之间的关系时遇到的困难。由于 GPT-3 可通过 OpenAI 提供的应用程序编程接口使用,因此可以将其整合到其他用于编码产品的 AI 中,从而进一步实现编码访问的民主化。
结论
为了继续构建涵盖所有需要它的应用程序所需的大量软件,AI 正在介入以帮助提高开发人员的生产力。由于对程序员的需求明显超过供应,利用其他解决方案来提高公司已有的编码器的输出和代码质量被证明越来越有益。随着最近基于 AI 的 NLP 模型(例如特别强大的 GPT-3)的显着改进,为人类开发人员提供 AI 支持的结对程序员的梦想正在成为现实。通过将此类模型嵌入到日常工具中,程序员可以减少花在重复性任务(如编写测试)上的时间,并通过自动审查和自动生成的代码片段提高代码质量,从而从中获益良多。即使是初级开发人员和技术水平较低的人也可以从现在可用的文本到代码功能中受益。软件可能无法单独吞噬世界,但 AI 肯定可以提供帮助。
来源:Mouser



 /4
/4 









文章评论(0条评论)
登录后参与讨论