
实验源程序如下:
module pipelineadder(clk,cin,a,b,sum,cout);
output[7:0] sum;
output cout;
input clk,cin;
input[7:0] a,b;
reg[7:0] sum;
reg c1,c2,c3,c4,cout;
reg[5:0] a1,b1;
reg[3:0] a2,b2;
reg[1:0] a3,b3;
reg[1:0] s1,s2,s3,s4;
//reg[5:0] a1,b1,s3;
//reg[3:0] a2,b2,s2;
//reg[1:0] a3,b3,s1;
always @(posedge clk)
begin
{c1,s1}<=a[1:0]+b[1:0]+cin;
a1[5:0]<=a[7:2];
b1[5:0]<=b[7:2];
end
always @(posedge clk)
begin
{c2,s2}<=a1[1:0]+b1[1:0]+c1;
// {c2,s2}<={a1[1:0]+b1[1:0]+c1,s1};
a2[3:0]<=a1[5:2];
b2[3:0]<=b1[5:2];
end
always @(posedge clk)
begin
{c3,s3}<=a2[1:0]+b2[1:0]+c2;
// {c3,s3}<={a2[1:0]+b2[1:0]+c2,s2};
a3[1:0]<=a2[3:2];
b3[1:0]<=b2[3:2];
end
always @(posedge clk)
begin
// {c4,s4}<={a3[1:0]+b3[1:0]+c3,s3,s2,s1};
{c4,s4}<=a3[1:0]+b3[1:0]+c3;
cout="c4";
sum={s4,s3,s2,s1};
// {cout,sum}<={a3[1:0]+b3[1:0]+c3,s3};
end
endmodule
开始的时候写的是{c2,s2}<={a1[1:0]+b1[1:0]+c1,s1};类似这样的语句(我注释掉的部分),结果综合后警告说最后的进位输出被锁定在VCC或者GND,仿真结果也果真如此,cout始终为0,但是sum结果输出还是正确的
后来,我在仿真中发现只有register变量只有c1被综合,c2,c3都找不到。原来我程序中只有c1的赋值语句是{c1,s1}<=a[1:0]+b[1:0]+cin;这样的格式
似乎{c2,s2}<={a1[1:0]+b1[1:0]+c1,s1};这样的语句赋值会出现问题,后来我全部改正如c1赋值那样的形式,结果综合通过,仿真也没有问题
SO,why?
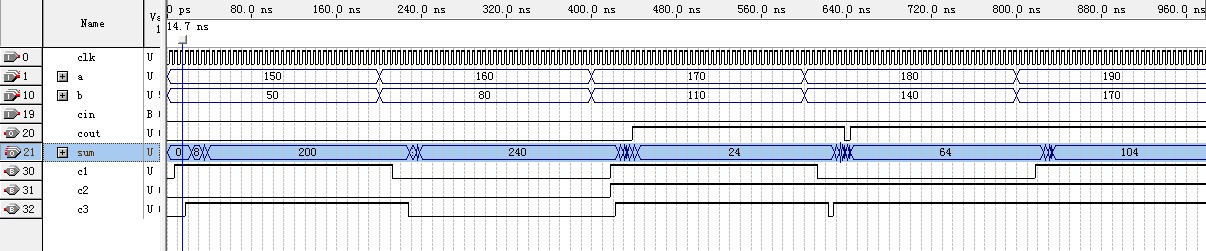
仿真结果如下图:时钟频率应当要足够高,至少时钟的一个周期要大于两级加法器的延时才能保证每一个时钟周期内的运算正确,否则会出现问题。


 /5
/5 






文章评论(0条评论)
登录后参与讨论