
三:本文的设计
为了解决以上讨论中遇到的挑战,我们提供了一种全新的能在低电压下工作的6T单元。存储器的电路图和版图,如图8所示。在不使用传统的差分结构的情况下,我们采用了单端单元。增加的一条字线WL_缺点被第二根字线的消失所抵消。本设计的明显优点是字线可以采用轨到轨的方式,能够避免读检测放大器的需要。另外,读操作的噪声与单个的bit线无关,使单端的设计在读翻转时比起传统差分结构更加强健。为了恢复写裕度,在写操作时将电源电压接至反馈反相器。单端单元结合门反馈写辅助的使用能够耦合读和写操作,在低电压下面临很多变量时能很好的平衡读和写裕度。
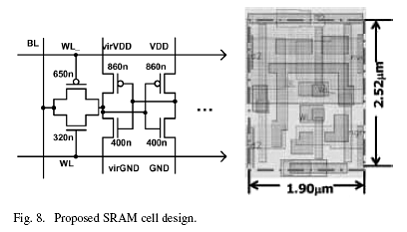
增加门尺寸去克服RDF也是本设计中的一个亮点。如图8所示的晶体管尺寸,并采用Monte Carlo SPICE进行仿真。为了满足强健性需求,所有管子的长度都是0.12um。最小结构宽式0.32um,为了限制RDF引起的Vth的不匹配(二-C中已有介绍)。PFET结构的尺寸设计和NFET尺寸设计彼此相关,解决亚阈值区域的![]() 变量的变化。不像传统的6T单元将PFET作为电阻负载,单端设计依靠PFET来拉高bit线。我们发现采用相等尺寸的反馈和前向反相器能够有效的平衡读和写的能力。Bit单元的面积是4.788um^2,如图8所示,比起传统6T单元,面积增加近2倍(2.366 um^2,在130nm工艺下)。值得一提的是,如果对电源电压floor要求没那么严格,存储器设计规则可行的话,面积是可以减小的。
变量的变化。不像传统的6T单元将PFET作为电阻负载,单端设计依靠PFET来拉高bit线。我们发现采用相等尺寸的反馈和前向反相器能够有效的平衡读和写的能力。Bit单元的面积是4.788um^2,如图8所示,比起传统6T单元,面积增加近2倍(2.366 um^2,在130nm工艺下)。值得一提的是,如果对电源电压floor要求没那么严格,存储器设计规则可行的话,面积是可以减小的。
图9给出了基于本设计6T单元的SRAM结构,共有16个bit单元连接到同一根bit线上,单个的bit线读电流通常比由于未访问单元而产生的总共的漏电流要大。另外,由于性能原因,在单端设计中,bit线应该尽可能短(电容小),这是因为检测部分是个简单的反相器,它需要在Vdd附近存在bit线波动。相比于传统的读检测放大器单元,短bit线的面积缺陷被最小化,因为每增加一根bit线需要在读出路径上增加2个CMOS。
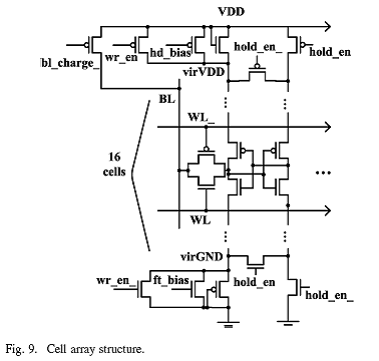
读出路径如图10,包含一个16-1列选择器和脉冲锁存单元。采用最小尺寸的反相器作为检测部分,目的是减小bit线的电容和最小化读翻转的可能性。在读路径中的第二个反相器尺寸足够大,目的是要达到一定的强健性。在已经完成的设计中,第二级多路选择器被限制成16输入,因为2kb对于目标检测应用是可行的。信号latch_en在每个周期快要结束时被激活,能够锁存输出数据。
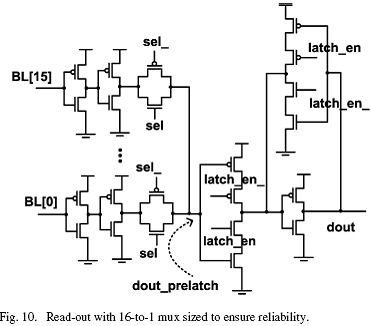
为了恢复单端设计牺牲的写稳定性,采用了适当强度的footer和header。写模式的单元阵列被抽象出来,如图11。依靠削弱反馈反相器来破坏在交叉耦合反相器中的反馈反相器。当写状态发生时,wr_en信号被选中,在顶端的强PFET晶体管和在底端的NFET晶体管被关断,仅使用弱footers和headers。结果是临时的电源电压下降,能够使存储单元被重新写入。本设计中在headers/footers上采用NFET/PFET作为弱结构,因为我们发现即使是最小尺寸的NFET/PFET headers/footers都没有特别明显的电阻特性。为了最小化面积,每条bit线上仅采用一个headers/footers作为供应调节电路,而每根bit线采用16个单元共用同样的virtual VDD和virtual gnd,如图11。尽管电源电压有所下降,但是未被访问单元的状态仍能够保持。
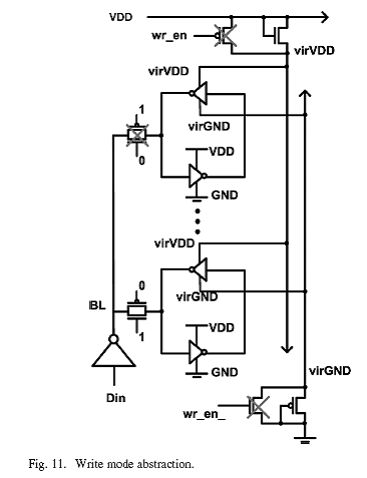
图12给出了时序产生图,是可编程的,能够允许时序强健性和性能的提高。为了解决亚阈值区域变量增加这一难题,我们实现了NAND和NOR类型的信号产生,能够实现脉冲可调。对于敏感的信号如wl和latch_en,它们的信号是可调的精细脉冲,而且经过延时校正。但实际上,测量结果显示,其中一个被set好之后,所有的dies都能准确工作。
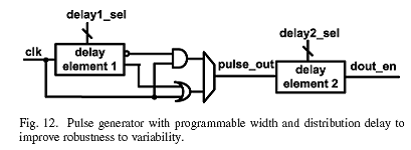
图13给出了采用SPICE读和写结果的仿真波形,存储单元2(Q[2])到15(Q[15])被初始化为1,Q[0]和Q[1]被初始化为0。在第一个时钟周期中,对Q[0]进行写操作,字线脉冲来自于时钟的上升沿,Q[0]数据在wordline选中后被重写。正如预料到的,virGND在这个周期里受到一定的扰动,然而virVDD不受影响,因为bit线驱动仅在写0时与footer晶体管发生竞争。同样的电压下降现象可以在Q[1]和QB[1]波形中体现。在接下来的周期里,从Q[1]读数据,这种情况对于数据独立性而言代表着一种最差的状态,因为其它的单元都保持着相反的状态,都会向Q[1]泄漏电流。不久,相对于Q[1]的字线被打开,bl被拉低,在每个周期结束时进行锁存。对这种最差状态下读写进行Monte Carlo仿真,可用来使设计时间最优化和进行产量估计。
由于bit线是直接连接至读出反相器的,当bit线出现浮动时,静态电流仍可以保持为高。因而,bl_charge,hold_en在待机模式下可被选中。依靠使能hold_en,virGND和virVDD被前置驱动反相器可以共用,可以产生强堆栈效应和依靠电流starving减小漏电流。
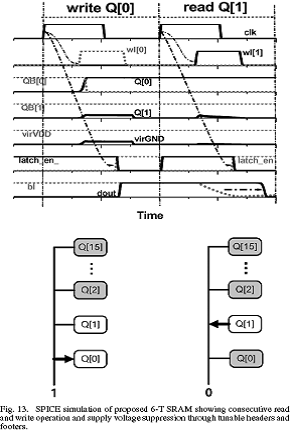
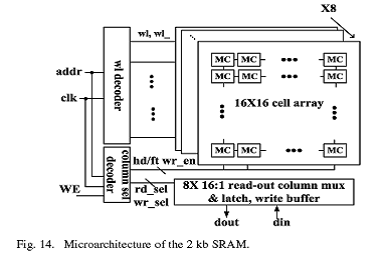
图14给出了顶端SRAM的微结构。2kb SRAM由256 words,每字8bits组成。8bit的地址线被分为4bit字线译码和4bit列译码。
四:测量结果
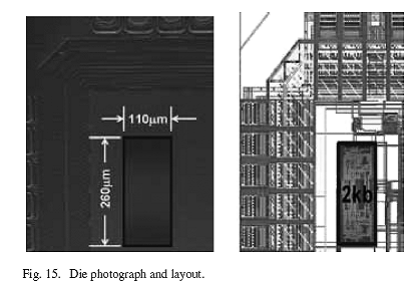
2kb SRAM测试芯片采用0.13um CMOS工艺(阈值电压0.4v)制造出来,以便证实我们结构的正确性。图15给出了die照和版图。在没有die-specific 调节时,SRAM能在208mv下正常工作,然而对芯片调节能够允许电路在139mv电压下工作。据我们所知,这是第一个能在阈值电压下进行正常工作的6T单元。共对24个dies进行了测量,它们都能正常工作。
A.性能和能量分析
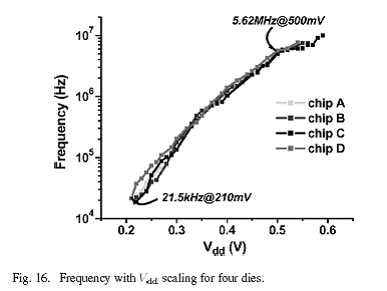
图16给出了4个典型dies的频率测量结果,显示出在亚阈值区域,频率相对于Vdd呈指数形式的关系。阵列能够在0.5v时实现5.6Mhz的频率,在210mv时速度为21.5khz,这和【8】中所报道的亚阈值处理器速度相仿,可应用于微控制领域。
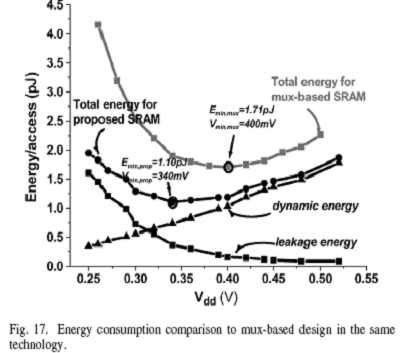
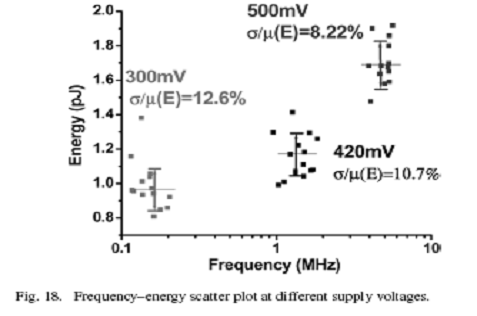
对于采用同样的工艺制造,本文所提出的SRAM访问单元的能耗和基于多路选择【4】的存储器能耗相当。测量功耗时采用同样的随机输入,每个周期内有一半时间进行数据访问。图17给出了所有SRAM的测试结果,本文提出的SRAM消耗功耗减小31%,性能提高20%。能量最优时,对于本设计的SRAM的Vmin设定在340mv,基于多路选择器的SRAM电压设定在400mv。图17同样给出了对于本设计在动态功耗和漏电流损耗之间的breakdown。由于在这一电压区域,电路延迟按指数形式增长,漏电流功耗占主导地位,在低于Vmin的电源电压下,每个访问单元的能耗会增加。在各自的Vmin电压下,本设计SRAM能耗比起传统基于多路选择的存储器能耗少了36%。另外,不像传统基于多路选择的存储器,本设计SRAM的Vmin更匹配典型的读检测放大器核【8】,这样能允许存储器和核能在单个电源电压下正常工作。如图18,14个测试dies的能量和频率分配在三种不同电压下的曲线图被绘制出。正如预料的,随着电压增长,变量减少了。
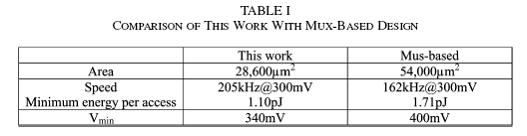
本设计SRAM面积为28600um^2,约为基于多路选择存储器(54000um^2)的一半。表I给出了电路属性的对比。一个采用传统6T 单元的2kb SRAM(商业库设计)的面积比本设计SRAM节省近30%。
B.错误率分析
图19给出了对于典型dies的维持错误率的测量结果。我们总结了半字节错误率,全字节错误率和bit级的错误率来增强应对系统级维持错误的影响。值得一提的是,如果出现bit级的错误,那么半字节和全字节被认为是错误的。因而,半字节和全字节的错误率要比bit级错误率高。
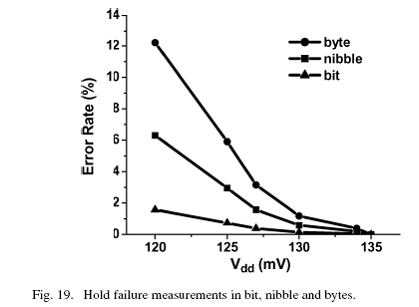
对于一个典型的dies,第一次出现保持错误率的时候是在134mv。对于全部的阵列而言在此电压下,待机损耗约为26nw。在120mv时bit错误率保持在2%以下。由于最小保持电压时晶体管尺寸的强函数,这点证实了采用增加单元尺寸方法的有效性。
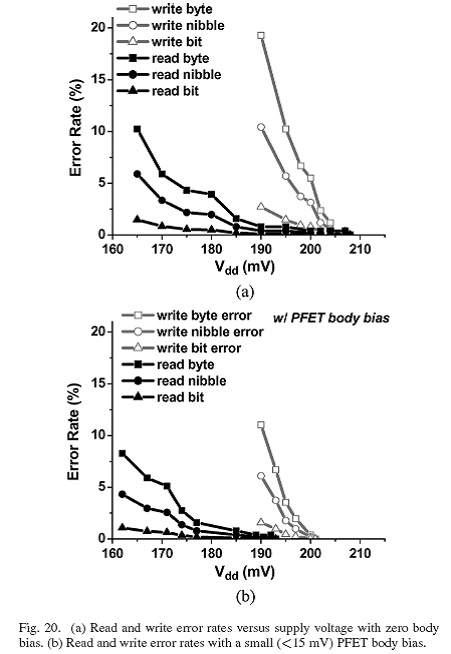
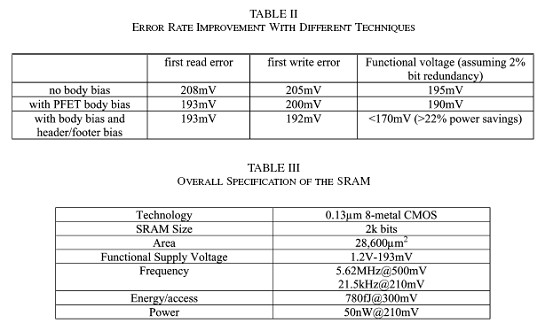
图20(a)给出了通过电源电压测得的读写错误率。第一次的读写错误率分别发生在208mv和205mv。测量结果显示,读写错误率能够得到很好的平衡,这也正是SRAM进行尺寸设计的目的。如果我们接受2%的bit冗余率,那么有效的操作电压可以达到195mv。在195mv时,电压调节受控于写错误率的增加。尽管读和写错误电压能够很好的匹配,但是写错误率曲线明显比读错误率曲线要陡的多。我们将在下部分探讨这个问题的解决方法。
依靠在PFETs上采用小的前置体基准电压(<15mv),错误率可以被大大的改善,如图20(b)。对PFET结构采用体基准电压可以补偿由于chip-wide导致的PFET和NFET的不匹配性,能够提高噪声裕。由于电流对于Vth呈现指数形式的敏感性,采用体基准电压(亚阈值区域)能特别有效改善性能,这点在一些研究中得到证实。第一次读写错误率分别发生在193mv和200mv,从图中可以看到,写错误比读错误要明显。在2%的bit冗余下,最新的有效操作电压为190mv。
C.扩展操作电压
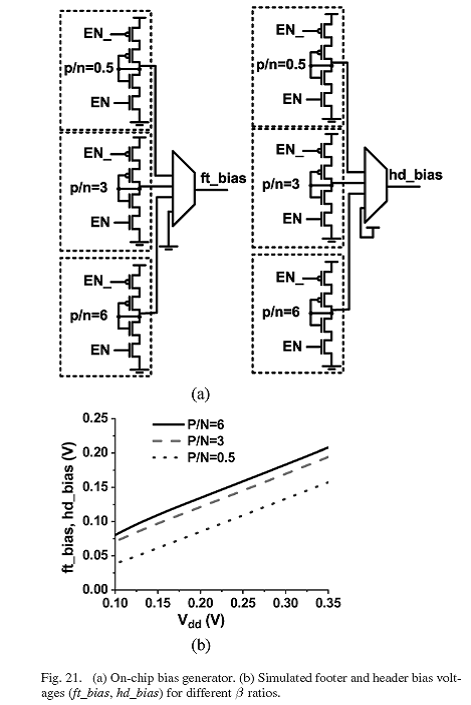
在200mv以下,由于弱headers/footers,SRAM的操作受限于写稳定性。弱NFET header结构在写操作期间会造成过高的电压波动,致使同一bit线上未被访问单元的数据遭到破坏。我们可以采用部分开启PFET/NFET与弱NFET/PFET并行作为header/footer来解决这个问题。控制电压(hd_bias/ft_bias)允许每个die都能单独进行调节。采用芯片体电压产生器,ft_bias和hd_bias能够在0v和VDD之间进行调整(6个等级)。On-chip体电压产生器的电路图如图21(a)。由于它只在非常低的电压下才使用,所以比起整个阵列的漏电流而言,体电压产生器的静态电流很小。图21(b)给出了基于SPICE仿真的,对于不同电压下的体电压的可能的结果。
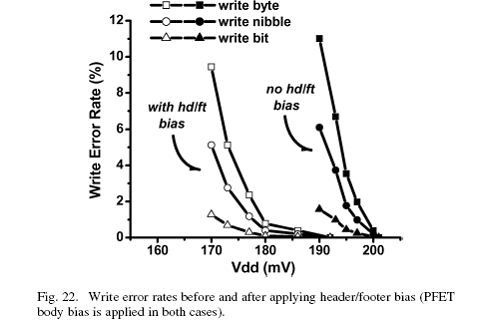
可调header/footer电路的有效性在图22给出了。采用header/footer后第一次出现写错误时的电压为192mv,相比与没有采用体电压的200mv,减小了8mv。显然,采用可调header/footer并没有带来第一次出现错误时电压的很大下降,但它改善了这一点以下的错误率,使冗余变得更有利。在2%的冗余下,有效的最小操作电压从190mv扩展到170mv,这样功耗节省了近22%。值得指出的是,我们将注意力放在能量效率上,一些确定性的应用需要低功耗。一个例子就是,芯片能够从芯片上的太阳能单元获得能量来供给自己。表II总结了每项技术的错误率分析,本部分主要的测量结果在表III中给出。
五:总结
本文的工作是提出了首个深亚阈值6T SRAM的设计。一个2kb SRAM测试芯片采用0.13um CMOS工艺库制造。测量结果显示,比起传统基于多路选择的存储器,本设计有了很大提高。本设计SRAM面积近似为mux_based 存储器的一半,每个访问单元的功耗比mux_based 存储器小近36%。从1.2v到193mv之间都能很好的工作,证明了周密的存储器设计可以使亚阈值操作成为一种可行的选择。


 /5
/5 






文章评论(0条评论)
登录后参与讨论