
在未来20 - 30年中,自动驾驶汽车(AV)将改变我们的驾驶习惯、运输行业并更广泛地影响社会。 我们不仅能够将汽车召唤到我们的家门口并在使用后将其送走,自动驾驶汽车还将挑战个人拥有汽车的想法,并对环境和拥堵产生积极影响。市场调研公司ABI Research预测:到2030年,道路上四分之一的汽车将会是自动驾驶汽车。
行业专家已经为自动驾驶的发展定义了五个级别。 每个级别分别描述了汽车从驾驶员那里接管各项任务和责任的程度,以及汽车和驾驶员之间如何互动。 诸如自适应巡航控制这类功能是先进驾驶员辅助系统(ADAS)的示例,并且可以被认为是第1级的能力。 目前,市场上出现的一些新车正在实现第2级功能;但作为一个行业,我们仅仅是才触及ADAS系统的表面,更不用说完全自主驾驶了。
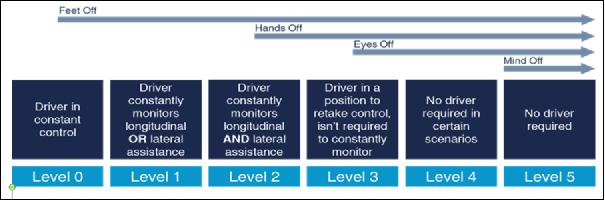
示意图:自动驾驶的五个级别
自动驾驶的级别
当我们去逐级实现自动驾驶的不同级别时,处理能力对于实现完全自动化这一愿景至关重要,此时驾驶员可以“放开方向盘、移开目光和放飞心灵”。 在这个级别上,车内的人只是乘客;同时因为没有司机,所以也不需要方向盘。 然而,在我们实现该目标之前,我们应该首先了解从非自动驾驶到完全自动驾驶之间的各种级别。
ADAS/AV有三个主要元素:传感、计算和执行。
用感知去捕捉车辆周围环境的现状。 这是靠使用一组传感器来完成的:雷达(长距离和中距离),激光雷达(长距离),摄像头(短距离/中距离),以及红外线和超声波。 这些“感官”中的每一种都能捕捉到它所“看到”的周围环境的变体。 它在此视图中定位感兴趣的和重要的对象,例如汽车、行人、道路标识、动物和道路拐弯。



示意图:汽车从激光雷达、雷达和摄像头中看到的视图
计算阶段是决策阶段。 在这个阶段中,来自这些不同视图的信息被拼合在一起,以更好地理解汽车“看到”的内容。 例如,场景中到底发生了什么? 移动物体在哪里? 预计的动作是什么?以及汽车应该采取哪些修正措施? 是否需要制动和/或是否需要转入另一条车道以确保安全?
执行即最后阶段是汽车应用这一决策并采取行动,汽车可能会取代驾驶员。 它可能是制动、加速或转向更安全的路径;这可能是因为驾驶员没有注意到警告,及时采取行动并且即将发生碰撞,或者它可能是完全自主系统的标准操作。
第2级实际上是ADAS路径的起点,其中可能在安全解决方案包中制定多种单独的功能,例如自动紧急制动、车道偏离警告或辅助保持在车道中行驶。
第3级是诸如2018款奥迪A8等目前已量产汽车的最前沿,这意味着驾驶员可以“移开目光”一段时间,但必须能够在出现问题时立即接管。
第4级和第5级两者都可提供基本上是完全的自动驾驶。 它们之间的区别在于:第4级驾驶将限于诸如主要高速公路和智慧城市这样的具有地理缓冲的区域,因为它们会重度依靠路边的基础设施来维持其所在位置的毫米级精度画面。
第5级车辆将可在任何地点实现自动驾驶。在这个级别,汽车甚至可能没有方向盘,并且座椅可以不是都面向前方。
自动驾驶所需的处理能力
在自动驾驶的每个级别上,应对所有数据所需的处理能力随级别的提升而迅速增加。根据经验,可以预计从一个级别到下一个级别的数据处理量将增加10倍。 对于完全自动驾驶的第4级和第5级,我们将看到数十万亿次浮点运算的处理量。
从传感器的角度来看,下表为您提供了其需求量的一个指引。 第4级和第5级将需要多达八个摄像头,尽管人们甚至已经提出了需要更高的摄像头数量。 图像捕获装置的分辨率为2百万像素,帧速为30-60帧/秒,所以要实时处理所有这些信息是一项巨大的处理任务。对于车上的雷达,其数量可能需要多达10台以上,这是因为需要在22GHz和77GHz之间搭配使用短距离、中距离和长距离(100m 以上)的雷达。即使在第2级,仍然需要对从摄像头和雷达捕获的数据进行大量处理。
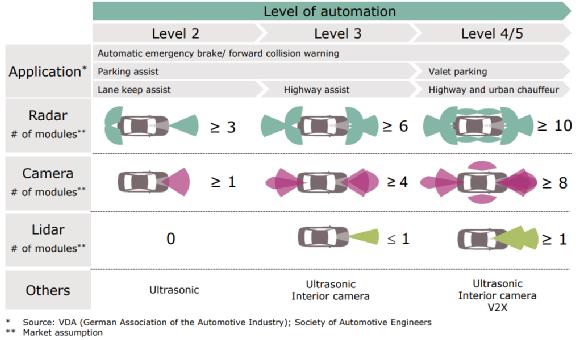
示意图:自动驾驶和应用的不同级别
对于处理能力,我们将关注摄像头需要做什么,这是因为它与前置雷达一起是支撑诸如在特斯拉中使用的自动驾驶仪的主要传感器。
摄像头系统通常是广角单摄或立体双摄,在车上呈前向或以环绕视场(360°)配置。 与雷达和激光雷达不同,摄像头感应设备取决于处理输入的软件的功能;摄像头的分辨率很重要,但没有达到你想象的程度。
为简化处理过程,我们使用了一种被称为卷积神经网络(CNN)的重要算法。CNN是从摄像头源中提取和分辨信息的一种高度专业化和高效的方法。在我们的汽车案例中,它从摄像头获取输入并识别车道标记、障碍物和动物等。CNN不仅能够完成雷达和激光雷达所能做的所有事情,而且能够在更多方面发挥作用,例如阅读交通标识、检测交通灯信号和道路的组成等。事实上,某些一级供应商(Tier 1)和汽车原始设备制造商(OEM)正在研究通过摄像头和雷达组合来降低成本。
CNN将机器学习的元素带入汽车。神经网络的结构都普遍基于我们自己大脑的连线结构。人们首先必须选择想要实现的网络类型,以及其按照层数来决定的深度。 每层实际上是前一层和后一层之间的一组互连节点。为了实现神经网络,大量的智能训练数据将被应用于它;这是一种高度计算密集型的操作,大多数情况下是离线进行的。对于诸如一种道路情况的图像和视频这样的每一次通过,网络通过调整各层内的相关因素来进行学习。当训练数据通过它时,这些相关因素可以从数百万次数据分析中得到提升。 一旦完成训练,就可以将网络和相关因素加载到诸如CPU或GPU计算或特定CNN加速器之类的结构中。
这种类型的算法和网络的优点之一是它可以用更新的或更好的相关因素去升级,因此它总是在不断改进。经过广泛的比较,我们发现在GPU计算模式上运行的CNN比在当前高端嵌入式多核CPU上快20倍且功耗也低得多。同样,伴随着CNN向硬件加速方向发展,我们也已看到性能还可进一步提高20倍,而且在功耗上也可进一步改善。
展望未来
随着我们走向采用无人驾驶汽车的未来,所需的计算能力将随着传感器的数量、帧速和分辨率而扩展。从性能和功率两个角度来看,卷积神经网络正在成为解释图像数据的最有效方式。 这将引领在网络的边缘放置更多处理资源的趋势,例如在汽车案例中,计算资源是在汽车自身内部,而不是将该处理能力卸载到云并且依赖于始终在线的蜂窝连接。 对于那些提供处理能力、算法和训练数据的人来说,自动驾驶潜藏着巨大的机会并将成为现实。


 /2
/2 





文章评论(0条评论)
登录后参与讨论