
在信息技术日新月异的浪潮中,DPU正逐渐崭露头角。当前,DPU发展的核心驱动力来自于什么?DPU技术是否已经足够成熟到广泛应用?市场上头部玩家参与到这一创新技术的市场角逐之中?在算力时代,DPU应该如何找准价值定位?而中科驭数作为国内DPU先行者,又将如何解题,引领DPU行业进入到一个全新的高度?
6月19日,在中科驭数2024产品发布会上,中科驭数CEO鄢贵海发表了《重新定义DPU》主题演讲,为我们深入探索DPU发展问题打开了一扇窗口,让我们带着这些问题,一起走进鄢老师的演讲实录。

以下为演讲文字实录:
全文6462字|阅读约16分钟
01
我芯所向
驭数人是有信念、有追求、有敬畏、有技术的“四有新人”
六年前,中科驭数团队带着对科技创新无比坚定的信念、对发展自主可控核心技术的不懈追求,对变幻莫测的市场的深深敬畏,和对未来智能计算技术趋势的研判,从实验室勇敢地迈出了科技创业的稳健步伐。我们也成为了有信念、有追求、有敬畏、有技术的“四有新人”。

我们驭数人有一个执念:不仅要把DPU做成一个产品,更要把“驭数”做成一个品牌,做成一个在数字时代、助力数字中国的品牌。驭数应该成为这个时代——趁势而上的企业。
然而我们清晰地知道,趋势并不能确保驭数的成功,时代只会给真正创新的企业以回报,只会给效率至上的企业生存空间。

创新,就是某种意义上的以弱胜强。集中资源、聚其一点,突破核心技术,用敢干务实的态度,克服千难万难,夯实从0到1的过程。我们只聚焦DPU,不为任何风口所动。在研发DPU的过程中,也从来不抱怨环境,因为我们知道技术创新的底色就是——攻坚克难。
效率,就是以快胜慢。时间就是金钱,效率就是生命。缓慢稳健是大象的专属权利。创新性企业,必须用一年走过别人三年的路,才有可能在市场竞争中赢得生存空间。在复杂大型芯片每代产品普遍3~5年的研发周期中,我们用6年的时间,完成了三代芯片的迭代,平均每代芯片迭代仅有不到2年的时间。同时在成本控制上,也远小于行业的平均值。
其秘诀,就是全栈技术自主研发,重硅前验证,快速迭代。用理论来指导实践,而非盲目地诉诸于通过工程试错来优化设计,把理论优势用到极致。

02
DPU是当下算力基础设施的核心创新
被称为数据中心“第三大支柱”
DPU是当下算力基础设施的核心创新之一。如果把CPU比作大脑、那么GPU就好比是肌肉、而DPU就是神经中枢。
CPU承载了应用生态,决定了计算系统是否可以通用,GPU提供了高密度各类精度的算力,决定了系统是否有足够的“力量”,DPU负责数据在各种CPU和GPU之间高效流通,决定了系统是否能协同工作。
DPU就是构建数据网络的“根结点”,挂载了各种计算、存储资源的“叶节点”,无论这些处理器核是真实的物理核,还是虚拟化的核。

DPU很旧,旧到可以完全取代传统网卡的功能。网卡俗称为“网络适配器”,其唯一的功能就是接收网络发来的数据和把数据通过网络发送出去,实现“上网”,好比交通的——绿皮车时代,解决全国主要城市基本通铁路的问题。
然而,DPU也很新,新到被称为这个十年最重要的创新,被寄予了数据中心三大支柱芯片之一的定位,戴上了“PU”的王冠。好比数据网络的——高铁时代,已经不仅仅是连通城市问题, 而是彻底重构了地理位置的逻辑距离了。

03
全球掀起DPU发展浪潮
产业头号玩家争先”抢滩“DPU赛道
过去五年DPU技术高速发展,特别是近三年。
短短几年时间对于一种具备巨大产业化价值的芯片技术而言并不算长,但是对于一种新的大类芯片类型,数家国际芯片业巨头短时间内组织研发力量并投入巨资“抢滩”式发布DPU产品也不是常见的现象。

NVIDIA于2020年发布了代号为BlueField 2的DPU产品,并高调宣称这是数据中心场景下的“第三颗支柱型芯片(原文为the third pillar)”,同年Marvell发布了代号为OCTEON的DPU产品,主打5G基带处理,携手Facebook打造高性能的OpenRAN解决方案。
次年另一个芯片巨头Intel携全新的重磅产品IPU(Infrastructure Processing Unit)加入了对DPU市场的争夺。前思科高管创立的科技公司Pensando在2020年HotChips会议上首次披露了其DPU的设计,主打P4,同时对PCIe设备虚拟化、存储、信任根、加解密进行了方案的支持,从技术来看甚至有领先后续披露DPU产品的行业巨头厂商的势头(该公司于2022年被AMD高价并购)。
在国内的DPU产品方面,中科驭数也在一年半前(2022年)成功流片了一颗标志性的DPU芯片,并且在网络时延指标和吞吐性能都处于业界同期较为领先的水平。阿里云也发布了CIPU产品、天翼云、移动云也分别发布了自研的DPU加速卡产品,还有移动云、天翼、云豹等,在此不一一列举了。据不完全统计,涉及DPU产品的公司有数十家。
可以说,在对DPU关注热度而言,国内并不亚于国外。
04
AI算力的发展加速DPU成熟
DPU是“顺”算力基础设施的“势”而为
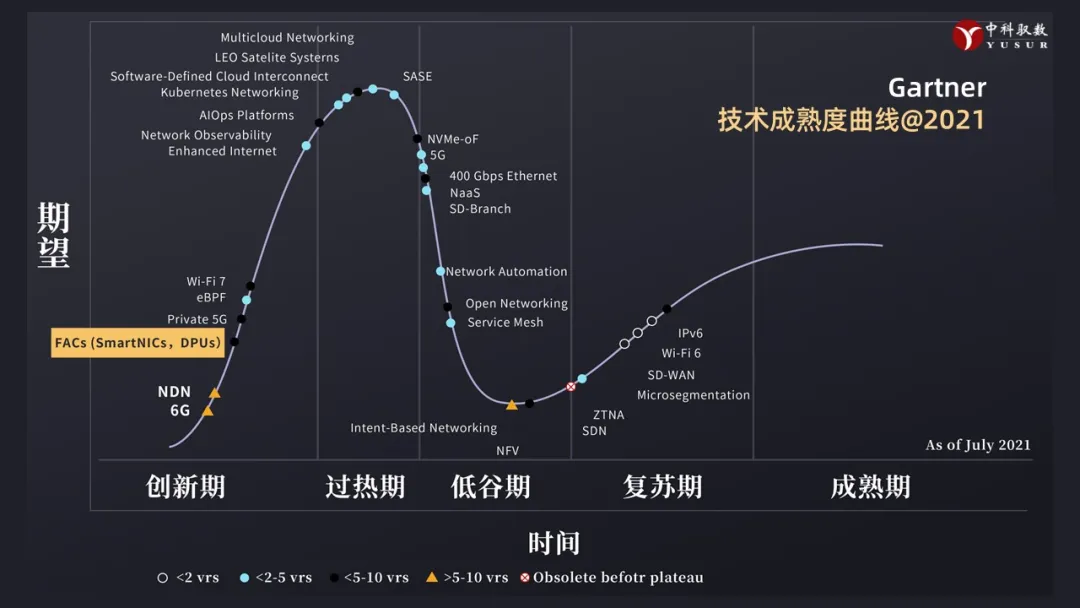
按照Gartner的技术成熟度曲线Hype Cycle的规律,针对一项新技术从创新、发展、过热、回归、沉淀、再进入正常规模化应用的常规发展路径,我们在过去2021年Gartner发布的Hype Cycle里出现了DPU,即“下一代SmartNICs,DPUs,IPUs”。该技术处于Hype Cycle的创新期,预测仅需要5~10年到达成熟期。而现在距离预测最早成熟期还有两年。而AI算力的加速发展,正在加速DPU的成熟。
近年在OpenAI主导的GPT模型取得了突破性进展已经成为共识,甚至有专家认为ChatGPT已经通过了经典的图灵测试,人们已经找到了从AI到AGI的“金钥匙”,而“AIGC”将是新一轮的内容生成、更是财富生成的密码。于是乎一夜之间,大模型遍地开花,仅中国有信息披露的就超过70家,可谓之盛况空前。OpenAI几乎以一己之力把人工智能的发展挂上了高速档。
目前人工智能发展的三要素:数据、算法、算力,在这一轮AI大模型的洗礼下,仍然重要,但是这些要素配给的挑战程度不同了。

在数据层面,人类社会虽然有五千年文明,但真正有大量数据沉淀的时间不超过200年,真正的数据爆发已经是以计算机和互联网的发明为标志的第三次产业革命之后的事了。也正是随着人类社会从电气化向数字化的转变,数据的爆发式增长才真正到来——而这满打满算只不过短短五十年的时间。以当前视角下所谓的“海量”数据,对于大模型训练而言,若非算力约束,是完全有能力消化的。

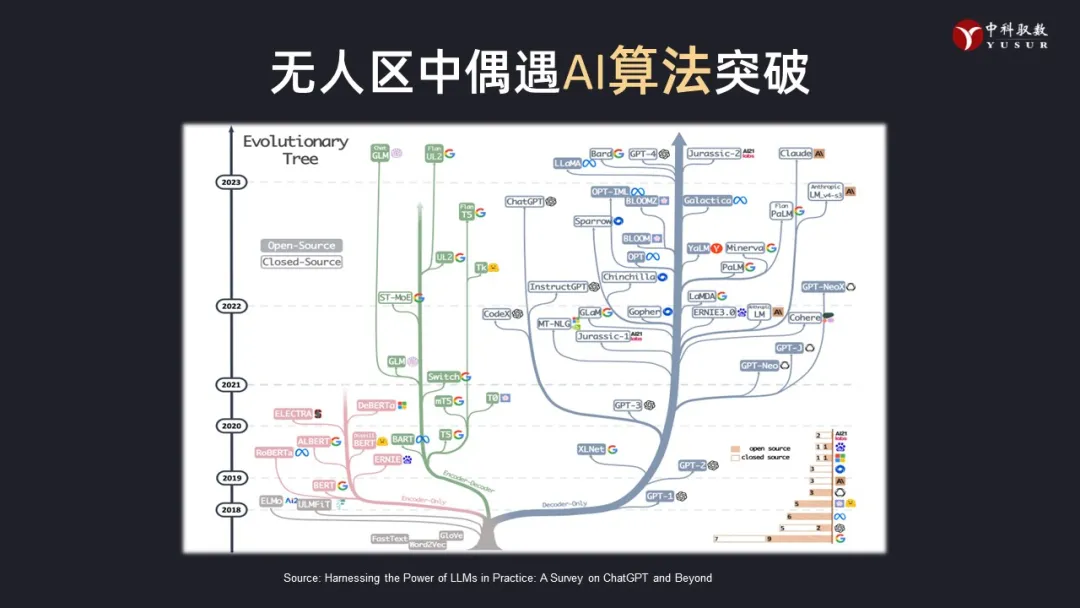
对于算法层面,虽然对创新有非常高的要求,几乎都要走在科学的“无人区”才有可能“偶遇”突破口,但是一旦突破,验证了可行性,就可以迅速的普及开来,当前大语言模型(LLM)的空前热度就是证明。OpenAI的GPT取得技术突破后一旦发布,就会迅速成为各个行业的一种共性技术基础。
而对于算力而言,相较于数据、算法层面的“软约束”,算力面临的是摩尔定律、登纳德缩放定律、能耗指标的物理“硬约束”。例如,就算训练GPT4的语料都具备,重新训练一次类GPT4大模型的算力需求、训练时间、综合成本也会让人望而生畏。甚至有专家断言,从既有算力储备的角度看,短期内在国内具备从0开始研发大模型的厂商不超过两家。

算力就是AI时代的“面包”!如何解决算力问题,成为了人工智能技术发展面临的最严峻的挑战,特别是在当前高端算力芯片进口受控的局面下。
DPU作为专注于解决算力基础设施层各种数据流量负载的芯片,其发展的主要驱动力也必然来自于对算力基础设施的更高要求——正所谓顺势而为。

05
从计算系统的三个视角审视DPU核心价值
为数字经济构造更高效、更大规模的算力底座
算力的问题不仅是单一算力芯片的问题,更是一个计算系统性的问题。有研究表明,即便是配备了较先进GPU的AI训练集群,受限于调度策略,数据共享,计算依赖等因素,仅30%系统计算资源利用率的现象并不罕见。如果再考虑在云计算环境下的多租户等复杂场景,资源被高度虚拟化、池化,一方面消耗了大量的CPU资源,一方面给网络、存储、系统安全等增加了很大的复杂度,结果就是留给客户应用的计算资源不仅减少了,而且性能也被降级。
传统意义上的“数据中心税”已经不仅仅是20~30%的资源开销问题,而是“算力经济”是否行得通的问题!

我们需要采用系统性视角,革新我们的计算系统设计,而DPU是解决这一问题的关键。
为什么?答案就在我们看待计算系统的三个视角中:
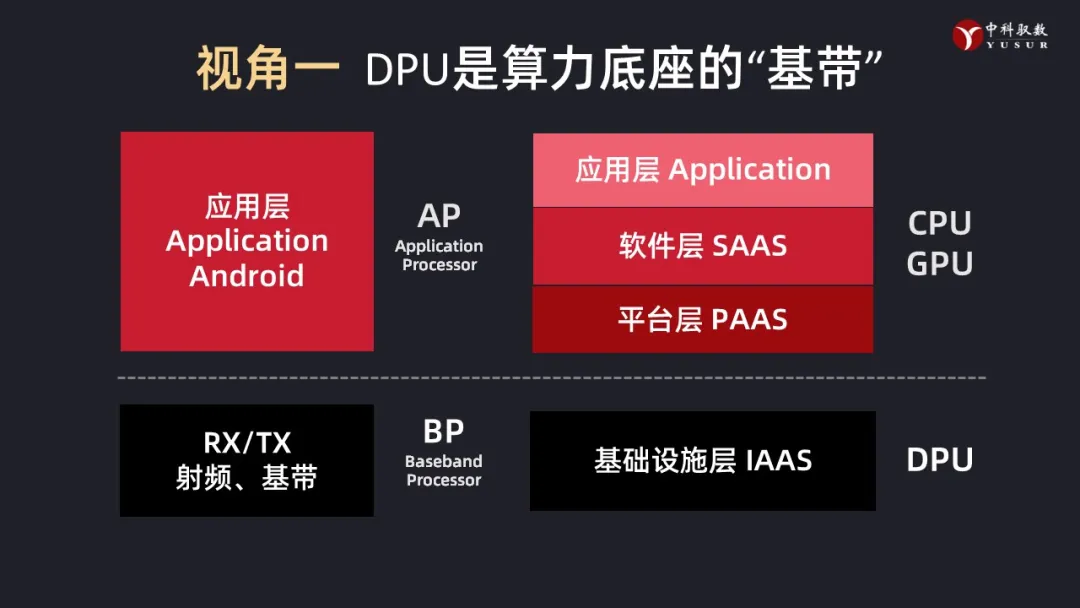
视角一:DPU要解决的首要问题其实还是各种算力资源的高效使用的问题,包括CPU的资源的释放,CPU与GPU以及GPU之间的高效通信、容器间通信、容器与虚拟机、Bare-Metal的统一调度与管理 等等。甚至可以认为DPU就是新一代算力基础设施的“基带”处理器(BP),解决资源的管理、数据通信问题;相应地,CPU和GPU可类比为“应用”处理器(AP),解决的是上层应用的执行问题。这里的“基带”是以网络为核心,类比在ISO七层协议的表示层/会话层以下的协议层,AP主要是应用层及其之上承载的丰富的各种应用。简言之,“BP+AP”就是新一代算力芯片的核心构成,——正所谓CPU-GPU-DPU “三U一体”。

视角二:DPU是“算网”融合的关键。“网”这一端的核心作用是传输数据,核心的功能是路由和交换,但这并不是DPU的重心。“网”端的核心指标带宽和延迟,目前看其实并不是系统性能的瓶颈所在,在服务器的“算”端能不能线速的处理那么高带宽的数据才是性能的瓶颈所在。DPU之所以仍要处理一些路由转发业务的原因其实是由于虚拟化技术的使用,本地资源被虚拟成了各种可独立运行的计算资源节点(例如容器、虚拟机),在行为上与一个物理节点没有区别,这些虚拟节点仍然有网络互联的需求,仍然有相互间访问,这也是网络在“算”端的延伸,所以也就有了OVS,SRIOV,Virt-IO等技术的需求。可以说是用“算”来实现“网”的功能——这不就是“算网融合”最具体的表现形式吗!

视角三:基础设施处理器的基础性体现在网络、存储、安全、计算加速等服务,DPU可以承接自原来的CPU所支持的底层或独立功能,即通常理解的“卸载”CPU的基础层功能,特别是让操作系统很多内核态的服务迁移到DPU上,通过硬件辅助的手段来获得更高的性能,这也决定了DPU不仅逻辑上应该更靠近CPU,物理上也应该更紧密才好。现在备受瞩目的CXL互联协议,也为DPU进一步靠近CPU提供了更方便的途径。进一步可以预测,维持直接相连节点间存储数据一致性的高速互连网络将会是DPU的核心能力之一。
总之,从功能上看,DPU将进一步推动算和网的融合,构造更加高效、更大规模的算力底座。
06
革命的产品一定不是单纯指标的升级
而是深度契合了技术趋势的发展
DPU到底值多少钱?
从DPU的价值判断上看,应该怎样理解DPU之于未来的计算系统的作用和价值,DPU的价值是否可以通过替代多少个CPU/GPU核、降低几微秒网络延迟来体现呢?
答案是肯定的,但这仅仅是“管中窥豹”,只见一斑!
革命的产品一定不是单纯指标的升级,而是深度契合了技术趋势的发展。汽车提升一下速度固然好,但是汽车做得再快,也不可能支撑航空产业的发展。
价值蕴含在趋势中。当前,DPU的发展契合哪些趋势呢?我们认为至少有三个重要的趋势值得关注:
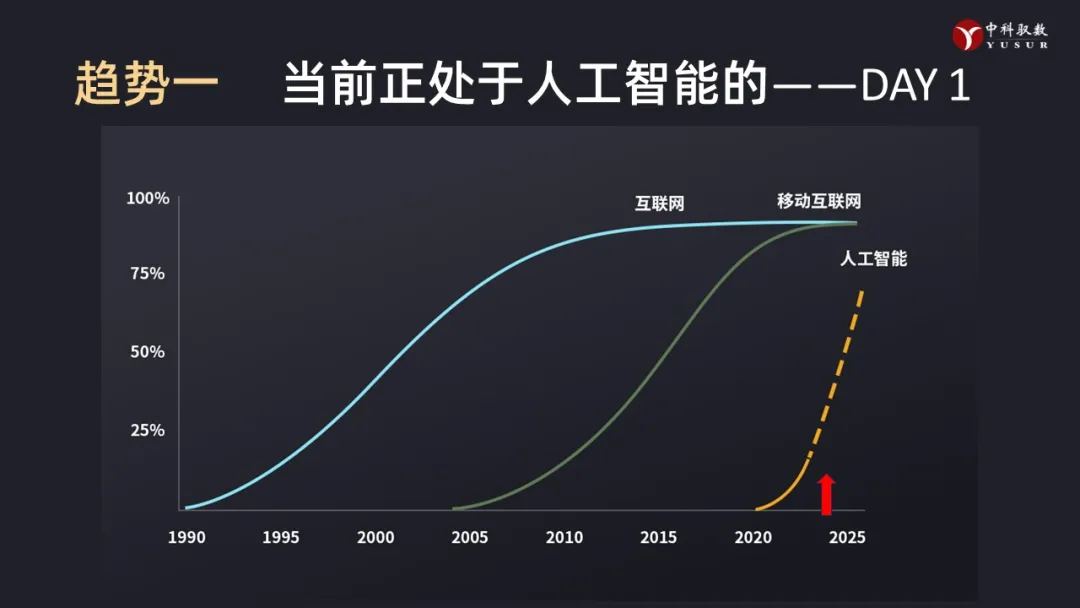
趋势一:当前正处于人工智能时代的爆发前夜。
不可思议!短短30年产生三轮大的科技革命的奇迹即将成为现实。
2000年的互联网,把世界变平了;2010年代的移动互联网,改变了人们生产和生活方式,也为数字化、智能化做出了必要积累;2020年代的人工智能,大模型的剧烈演进,已经让人们看到了AGI的曙光,同时潜在失控风险也让一些人感到深深的不安。我们中国人非常有“先见之明”,在40年前将计算机称之为“电脑”,真的越来越像“脑”。深度学习的发明人、图灵奖得主Hinton明确表达了自己的观点:今天的深度学习可能已经有了意识。OpenAI的首席科学家,Hinton的高徒Ilya Sutskever也明确的表达建立完全自主的机器是完全有可能的,现在的当务之急是如何确保机器的目标和人类的目标一致,而避免电影《终结者》中的场景成为现实。
尽管无论是脑科学还是认知科学,人们现在还是无法解释大脑为什么会产生智能。爱因斯坦说“我们无法用提出问题的思维来解决问题”,是否可以理解为我们用人类智能来研究出的这些科学原理和经验法则,是不可能解决人类智能的问题的。相反,如果我们无法知道它的原理,也搞不清楚它的机制,但是结果却超出预期,反而有可能是“智能”的原因。
有观点认为智能并不蕴含在算法中,而在数据中。深度学习、大模型只是基于简单的计算规则,把数据的复杂性转换成了模型的复杂性,从而将蕴含在数据中的智能嵌入到了模型中。天量的数据,堪比人脑神经元数量的模型规模,注定了算力需求必然暴涨。而迭代出的更好的模型对数据又会有更大的胃口,更大参数规模的模型;更大的算力意味着更高的智能。至此,算力与智能的正循环彻底启动了,难以逆转。
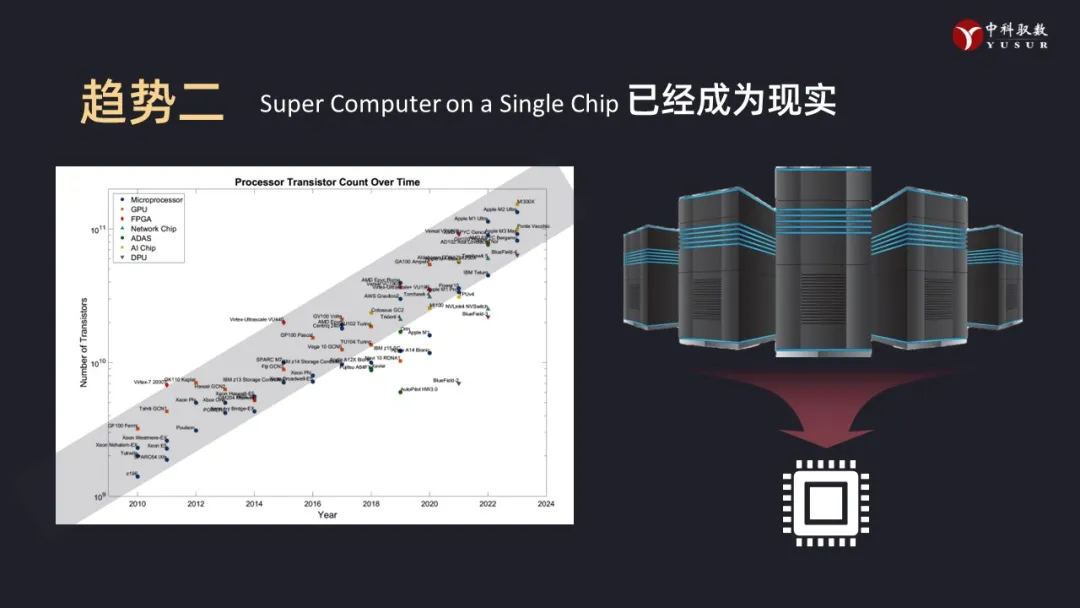
趋势二:尽管摩尔定律已经放缓,但是单芯片规模还在不断上升。“Super Computer on a single Chip”已经成为现实。Chiplet技术使得单个封装芯片的规模可以不断增大,但不降低良率。英伟达的GH200处理器单个芯片提供约4PFLOPS的算力(FP8精度),功率消耗控制在1000瓦。作为对比,在2010年Top500第一名的天河1A超级计算机,算力也不过2.57PFLOPS(全精度)。就目前而言,单芯片的算力还在指数增长,这就意味着单个芯片的IO性能要求必然更高了。否则,就会面临“茶壶里面煮饺子——倒不出来”的尴尬。

趋势三:算力的供给方式多样化与灵活性持续增强,降低客户的算力成本。从IaaS,PaaS、SaaS到FaaS,对资源的供给方式和抽象层次一直在不断的变化,背后的整体趋势是越来越弱化应用支撑的差异性,资源的粒度也越来越细化。从最早的以一台带着虚拟的CPU、内存、网络、存储资源和操作系统的虚拟机服务,到只提供函数级的服务;费用从按天/月租用虚拟机的方式计费,和利用率无关,到按照调用函数的次数来计费,pay as you go,这代表着算力资源的形式、组织方式、供给粒度都产生了巨大的变化,从粗放一直向集约化演进。这对计算系统的部署、服务、运维都提出了巨大的挑战。
从资源管理的角度看,无论哪个层面的操作系统,都在建立在统一的视图的基础上,通过层次化抽象、封装、模拟等技术来实现。例如虚拟机、容器和Bare Metal,都可作为计算节点,共享相同的物理资源池,并且有可能需要相互通信。这些计算节点会随着应用的需求按需动态申请部署,协同工作,完成任务后即刻原地释放了。这个管理的开销是极大的。
大家一定对这三个趋势的价值有自己的判断。而相应的,对DPU的价值判断,我相信大家已经有了答案!
以上三个趋势有内在因果关系。当算力成为了刚需,必然导致第二个趋势——单芯片越来越大,IO的需求越来越高,随之管理这些资源也会越来越复杂。
其实不难理解,城市扩大了,如果基础设施和治理机制跟不上,就会出现“大城市病”,芯片变大了没有配套好基础设施和治理机制,也会出现“大芯片病”。
我们不能采用线性的思维来解决这个问题。城市扩大一倍,所有车道数量并不能简单的也扩大一倍,而是需要地铁、轻轨、立交桥等新型的基础设施和相应的高效流控机制。同样的道理,解决“大芯片病”也一样,也需要技术创新才有可能解决。

07
打通数据中心算力的“堰塞湖”
以架构决胜、软件护城、平台上门重新定义DPU
驭数的目标是为算力基础设施提供一流的DPU产品,解决算力资源的弹性扩展、高效互连、加速计算、统一运维等关键问题,打通数据中心算力的“堰塞湖”。
我们将——
架构决胜——用最先进的芯片架构来重新定义DPU芯片架构;
软件护城——用最高兼容性来重新定义DPU的软件系统;
平台上门——用最低的成本让客户接入DPU规模化部署与业务验证。
为了实现这些目标,DPU已经不仅仅是一颗芯片,而是芯片、软件、平台的一体化工程,驭数将彻底重新定义DPU!

08
以”芯云计划“全面进化算力基础设施
做到手中有芯,心里有云
在2025年,中科驭数会完成K3芯片的发布,仍然采用我们最新的KPU架构,KISA2.0指令集,兼容KISA1.0,集成RISC-V轻量级控制核,处理带宽将是K2Pro的四倍,达到800G,延迟低于1微秒,功耗比K2-Pro的下降40%。
在软件方面,我们将逐步向各大开源社区开源我们的HADOS教育版,同时推出企业版HADOS 4.0,在性能、功能、稳定性方面全面升级。
在云平台方面,我们也将进一步扩容驭云,推出驭云2.0,节点规模从400个节点突破到1000个节点,同时在集群部署、运维、调优、一体化、可视化方面达到更高的高度。
这些内容将构成驭数在算力基础设施领域的“芯云计划”。我们做芯,是为了服务云。手中有芯,心里有云。
中科驭数也会继续为行业做贡献,持续深度参与行业标准的制定,力争参与和牵引标准突破100项。同时,我们也会继续重视知识产权保护,筑牢科创根基。到2025年末,累计提交发明专利1000项、软件著作权1000项。
而这一切,都离不开我们生态伙伴的支持与信任。这也是我们驭数的信条——协作创造价值,创新引领未来。

09
希望人们以后像记住Intel=CPU,Nvidia=GPU一样,
记得 驭数=DPU!
回顾历史,50多年前的1971年,当Intel发布了首颗成功的CPU产品,我们还没有改革开放。
20多年前的1997年,Nvidia发布了让它起死回生的GeForce系列GPU,宣告自己成为了GPU的发明者,而当时对于科技创新而言,我们还处于浓浓的“做不如买,买不如租”的氛围中。
4年前,当DPU成为了风口浪尖的热点时,我们已经提前出发了2年。这一次,我们终于有希望不仅是起得早,还能赶上早集。
我们更希望,人们以后像记住Intel=CPU,Nvidia=GPU一样,记得驭数=DPU。
我们今天发布的所有成果,是中科驭数团队2千多个日夜艰苦奋战的结果,就在现在,我们还有同事在客户的现场开展交付调试,还有同事奔赴在去往各个客户交付场景的高铁、飞机上。
感谢大家的热情参与,期待与您在不久的将来,再次相聚,再会!

作者: Yusur_Tech, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3991230.html
版权声明:本文为博主原创,未经本人允许,禁止转载!



 /1
/1 







文章评论(0条评论)
登录后参与讨论