
1. 方案背景
1.1. 业务背景
随着容器技术的迅猛发展与广泛应用,一种新的云计算服务模式应运而生-函数即服务(FaaS, Function as a Service)。FaaS作为一种无服务器(Serverless)计算方式,极大地简化了开发人员的工作,使他们能够专注于应用的构建与运行,而不再需要承担服务器管理的负担。
然而,FaaS模式也并非没有缺陷,其中最为人诟病的便是“冷启动”问题。所谓冷启动,是指当请求被调度到某个函数实例时,如果该实例在上次执行完代码后已经被回收,系统需要先创建一个新的实例并初始化环境,才能继续执行代码。
相比之下,热启动则是指函数实例未被回收的情况下,直接复用现有实例以响应请求,这显然效率更高。因此,冷启动过程常常导致较高的延迟,进而影响应用的性能。
1.2. 问题与挑战
根据《Slacker: Fast Distribution with Lazy Docker Containers》一文的分析,镜像拉取过程占据了容器启动时间的76%,然而实际启动时只有6.4%的数据会被读取。这一现象揭示了传统容器镜像格式和拉取方式在使用overlay文件系统(OverlayFS)时存在的问题:
这两个问题的根源在于容器镜像是由一组tgz文件组成,而这些文件作为镜像层(image layer)存在以下两个显著缺点:
因此,使用OverlayFS的容器在启动前必须完成所有tgz文件的拉取和解压,这无疑增加了启动时间。
针对这些问题,社区已经提出了一些改进措施,具有代表性的两个解决方案是Stargz和DADI。
Stargz 是一种容器镜像加速技术,它采用了 Google的CRFS(Container Registry Filesystem)来重新组织容器镜像,以便实现更快的容器启动和更高效的文件检索。CRFS是一个只读的用户态文件系统,它使用了新的文件格式,使得镜像层内的文件可以被随机访问(seekable)。
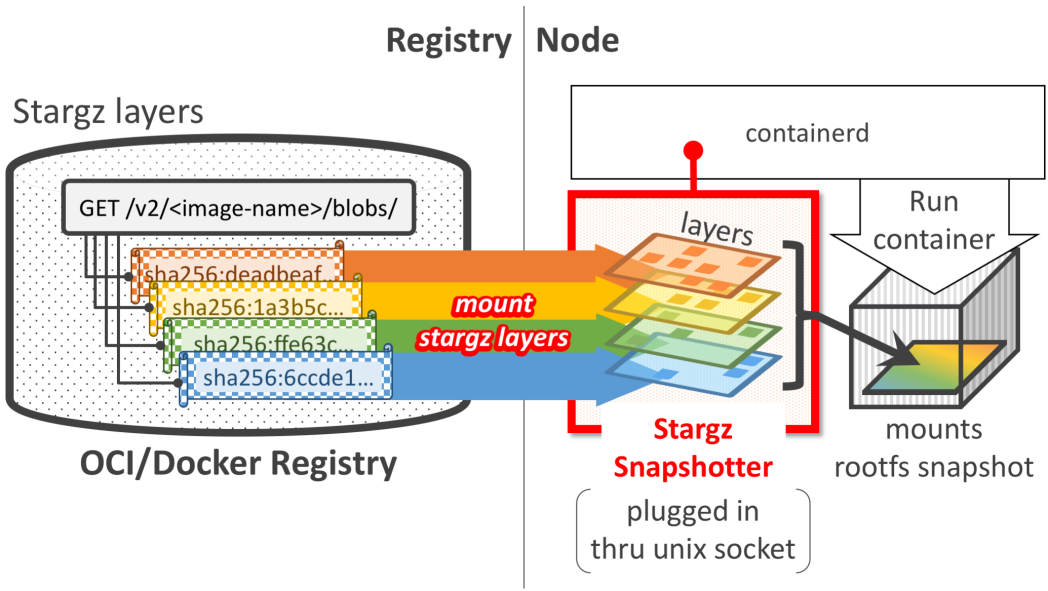
stargz架构图
使用Stargz启动容器时,无需拉取所有层到本地,而是远程挂载每一层到本地目录组成rootfs,从而实现容器的快速启动。容器启动之后的数据访问则是利用FUSE(用户态文件系统)按需获取。
DADI(Data Accelerator for Disaggregated Infrastructure)是阿里云针对容器加速的解决方案,DADI 的核心组件是 Overlaybd,这是一种基于块设备的镜像格式,提供了在block-based layer之上的一个合并视图,然后通过TCMU在Host上产生一个SCSI设备作为rootfs。TCMU(Target Core Module In Userspace),是scsi target的用户态实现,用于生成一个容器 rootfs 的 SCSI 设备。
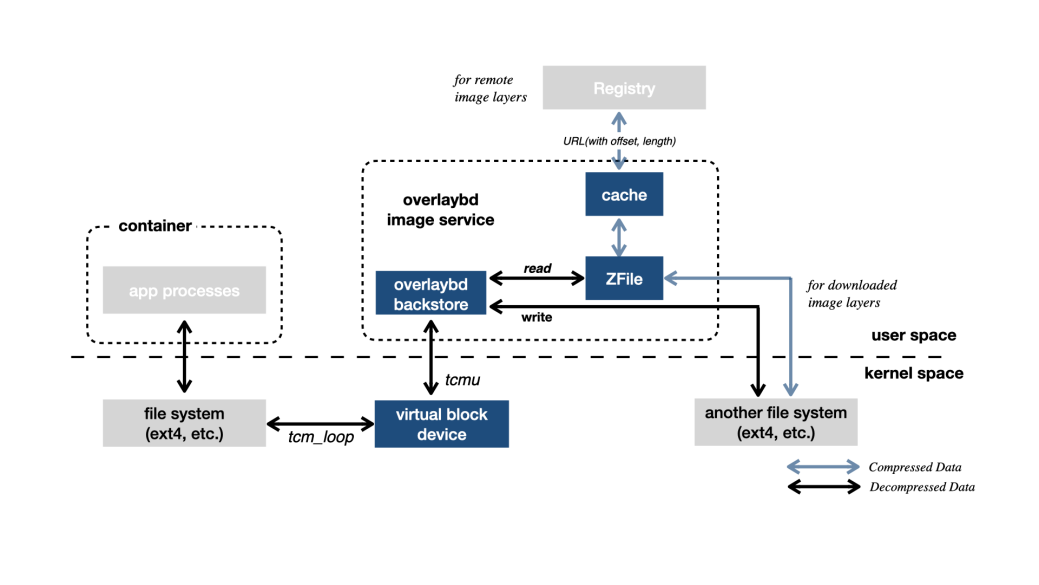
DADI架构图
使用DADI启动一个容器时,其也不用拉取所有层到本地,只是基于所有层块设备创建一个scsi device表示rootfs,实现容器的快速启动。容器启动之后的数据访问则是由tcmu按需获取,并且加入了本地缓存和ZFile加速数据的读取。
综上所述,以上方案在实际应用中仍然存在以下问题:
为了解决上述问题,我们构建了基于DPU的容器冷启动解决方案,以k8s为底座,以存储为核心,利用DPU的卸载和加速能力,使容器的冷启动更快,占用更少的host资源。整体架构如下所示:
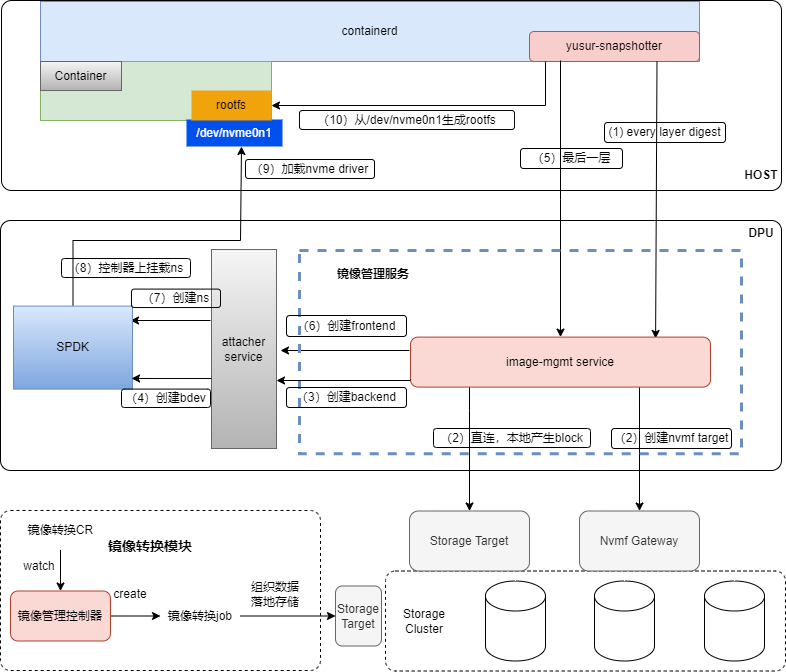
1-4):containerd会调用yusur-snapshotter准备rootfs每一层的内容快照,image-mgmt根据label参数连接存储,创建spdk bdev。
5-9):到最后一层时,需要创建NVMe subsystem/ctrl/ns,关联spdk bdev,此时在host侧给相应PCI绑定NVMe驱动,即可看到对应的NVMe disk。
10):yusur-snapshotter查到disk之后,按照不同的镜像格式生成容器启动的rootfs。
采用本方案启动容器时,首先DPU会通过NVMe/RDMA的方式连接远端存储,实现高效的数据传输,然后通过NVMe PCIE的方式直通给host,最后host基于这个直通的disk生成rootfs并启动容器。由于云盘原生支持按需读取的特性,本方案在容器启动过程中无需拉取镜像,从而显著加快容器的启动过程。
当使用本方案启动容器时,首先需要进行镜像转换,镜像转换的主要作用是将原始镜像按照 Lvol(逻辑卷)的方式落地到存储中,并将镜像元数据推送至镜像仓库,供容器启动时使用。
同时本方案在镜像转换时支持两种镜像格式yusur-overlayfs和yusur-overlaybd。yusur-overlayfs和原生的镜像格式一样,按照overlay的方式生成rootfs,主要用于兼容overlay的场景;yusur-overlaybd以块设备的方式作为rootfs,原生支持可写层和理论上性能较overlayfs好。
镜像转换主要责任是基于SPDK snapshot机制把原生镜像按需转换成以上两种格式的镜像,镜像数据存到存储,元数据存到镜像仓库。镜像转换有两种工作模式:普通模式和DPU模式。在DPU模式下,能利用DPU的加速能力,可以显著加快镜像转换的速度。
普通模式的架构如下图所示,其组件主要包含image-ctrl,attacher service,opi-spdk-bridge和原生spdk。
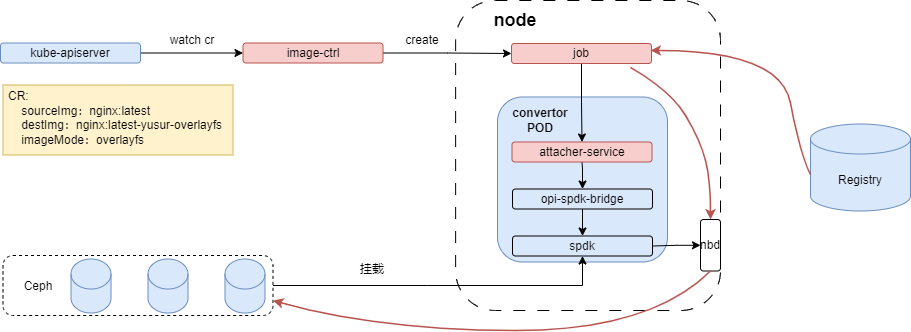
红色线条表示数据走向,job拉取原镜像层数据,按不同镜像格式写到nbd设备中。各个组件的作用如下:
DPU模式的架构如下图所示,其组件主要包含image-ctrl,image-mgmt,attacher ,opi-bridge和DPU spdk。
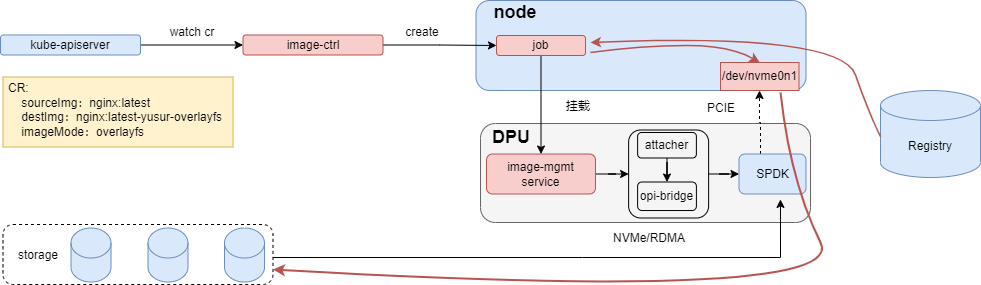
红色线条表示数据走向,job拉取原镜像层数据,按不同镜像格式写到NVMe disk中,各个组件的作用如下:
使用两种镜像创建容器时,处理流程基本一致,差异在镜像数据的组织方式和rootfs的组成方式,yusur-overlayfs镜像格式如下所示。
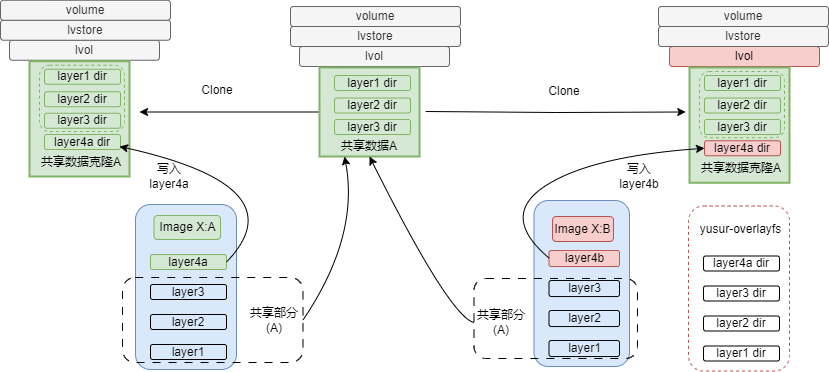
如上图所示,镜像X:A完成镜像转换之后,生成数据A,镜像X:B在转换时直接使用这部分数据,镜像X:B其他数据基于克隆的lvol写入。共享数据可以包含一个或多个lvol,它们之间也是通过clone链接在一起。
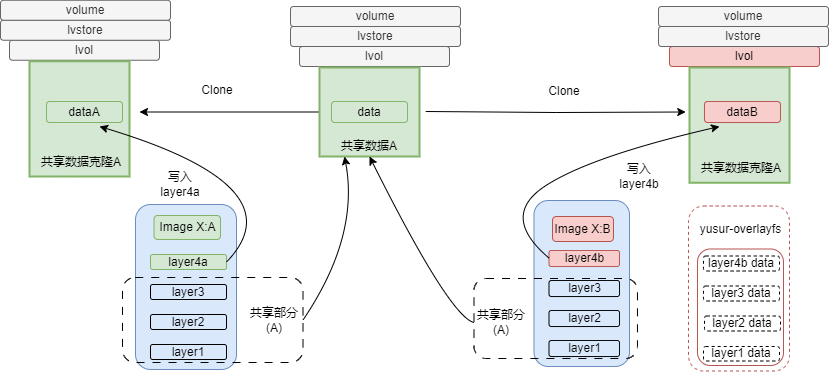
yusur-overlaybd的镜像格式如下图所示,与yusur-overlayfs镜像每层数据写到lvol不同目录的方式不同,yusur-overlaybd的镜像数据会直接写入lvol。
两种镜像格式的rootfs组成如下图所示。
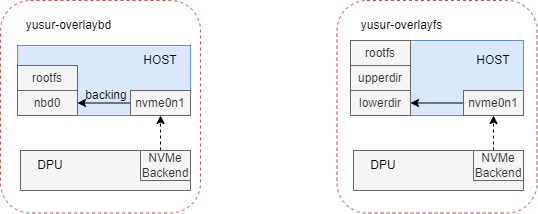
yusur-overlaybd以nbd设备作为rootfs,不用额外的可写层;而yusur-overlayfs是以块设备中的多个目录作为lowerdir,然后加一个可写层作为upperdir构成rootfs。
容器启动流程请参考”整体架构”章节。当用转换镜像启动容器时,containerd会根据镜像元数据生成一些labels,这些labels会作为参数传递给yusur-snapshotter,yusur-snapshotter会根据这些labels,创建不同的存储target。
目前支持两种形式的存储target,本地AIO和远程NVMe-OF,NVMe-OF同时又支持两种连接方式NVMe/TCP和NVMe/RDMA。在容器启动过程中主要涉及以下组件yusur-snapshotter,image-mgmt service和attacher service,作用如下:
创建镜像转换CR之后,控制器就会创建job进行镜像转换。以下是yusur-overlayfs和yusur-overlaybd转换成功的截图:

转换成功之后,会更新CR status,blocks会包含目的镜像对应存储的卷,多个卷之间是以clone的方式递进,以yusur-overlayfs为例,如下所示:
apiVersion: iaas.yusur.io/v1 kind: ImageConvertor metadata: name: nginx-latest-overlayfs namespace: image-mgmt spec: destImage: harbor.yusur.tech/cidg/img_test/nginx:latest-yusur-overlayfs imageMode: overlayfs sourceImage: harbor.yusur.tech/cidg/img_test/nginx:latest virtualSizeByGB: 100 status: blocks: - global-ba870cf5-6c3c-4cf6-95f3-d3963086b4e9 - local-e39cacaa-5c3e-4676-a014-d513a1ca0c09 - soldier-f64acdbb-4255-4999-81f8-652e1741120f imageMode: overlayfs ready: true |
转换成功之后,目的镜像会推送至镜像仓库,其作用是在容器启动时,提供存储相关的元数据,如下所示:
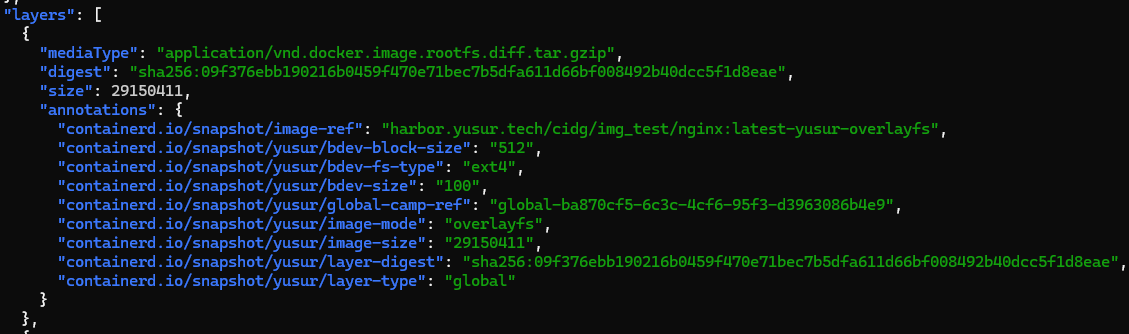
Annotation中包含该层所在的块设备,镜像格式,文件系统等信息,这些信息会作为labels传递给yusur-snapshotter。
pod启动之后,可以查看rootfs组成,如下所示:
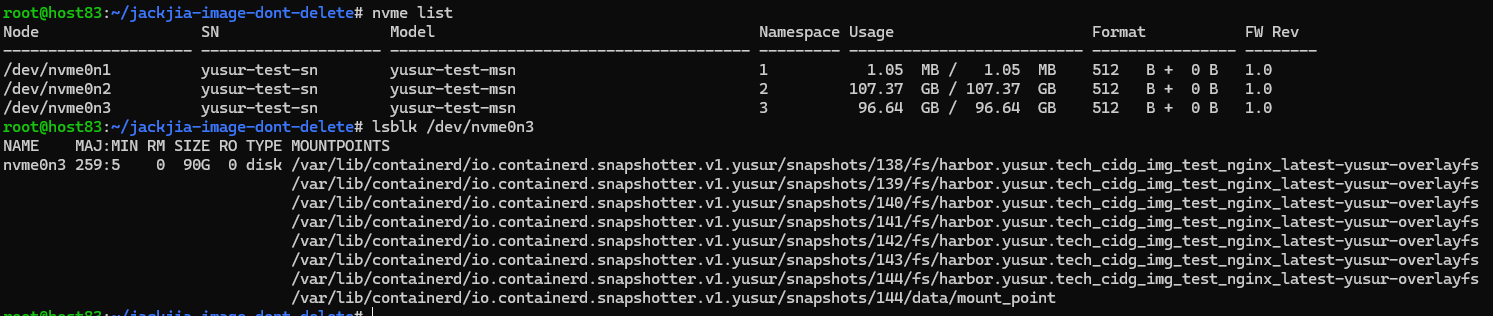
Yusur-overlayfs:

overlayfs格式的镜像,块设备中包含镜像的每一层数据,挂载后把相关层目录,bind到对应的snapshot,构成overlay的lowerdir。

Yusur-overlaybd:
overlaybd格式的镜像, 块设备中包含镜像的rootfs;没有把块设备直接作为容器启动的rootfs,考虑到还需要一个可写层,所以基于块设备创建一个qcow2的本地文件,然后本地文件通过nbd暴露出来,作为容器启动的rootfs和可写层。
性能测试包括5种方案,本方案提供了其中的两种yusur-overlayfs/NVMe/RDMA和yusur-overlaybd/NVMe/RDMA。yusur-overlayfs/NVMe/RDMA表示镜像格式是yusur-overlayfs,存储target是NVMe-OF,连接方式是RDMA;yusur-overlaybd/NVMe/RDMA同yusur-overlayfs,只是镜像格式不同。
我们将测试整个容器启动过程中的时间消耗,具体分为三个阶段:镜像拉取、容器创建和服务ready。
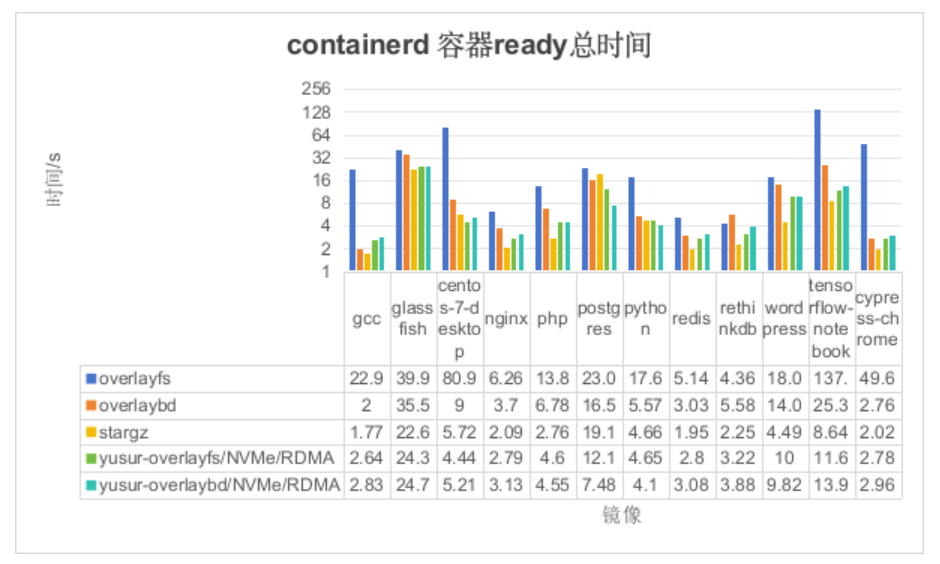
如上图所示,纵坐标表示容器ready时间(单位:秒),横坐标表示镜像名称。由于此场景只是去掉了k8s的影响,结论同2.2.1, 如下:
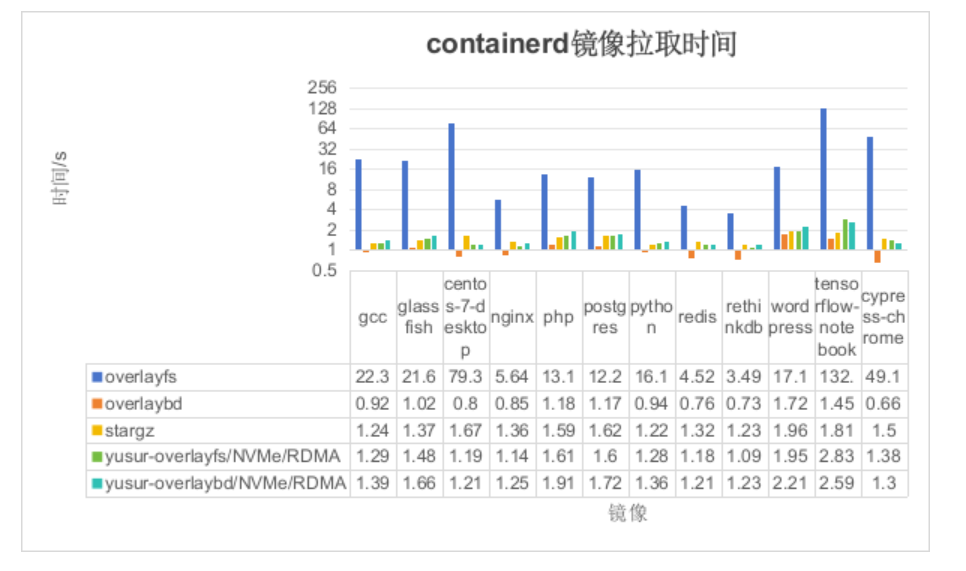
如上图所示,可以得出如下结论:
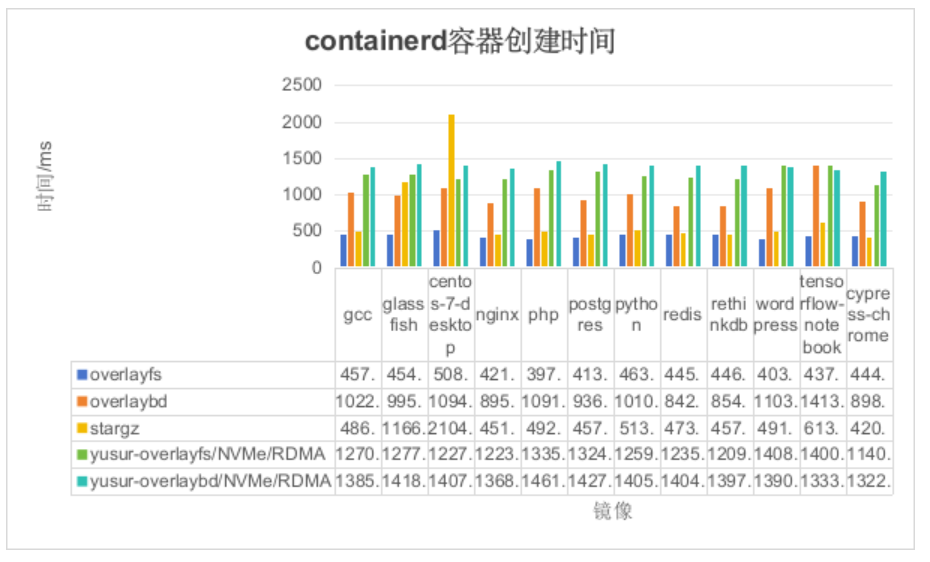
如上图所示,可以得出如下结论:
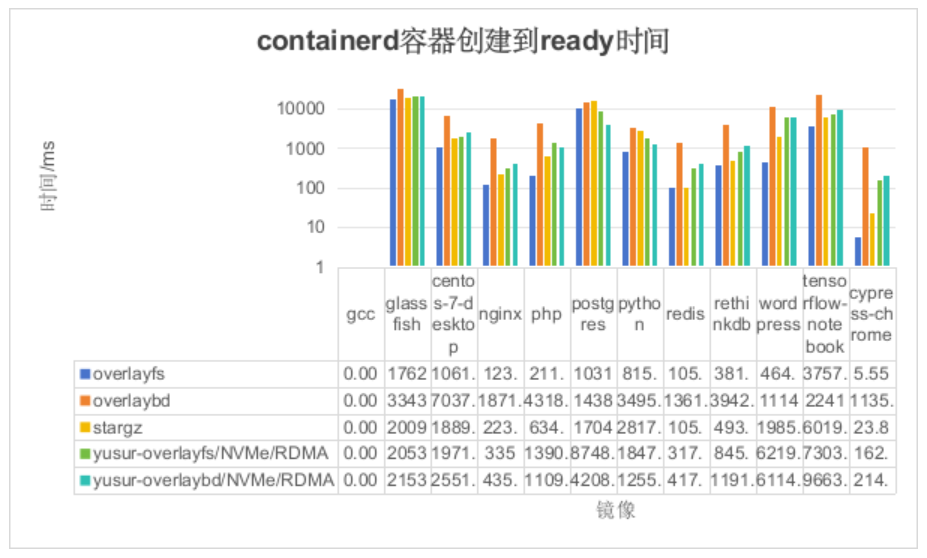
如上图所示,可以得出如下结论:
由于两种镜像格式相差不大,故采用 yusur-overlayfs 作为对比,测试结果如下所示:
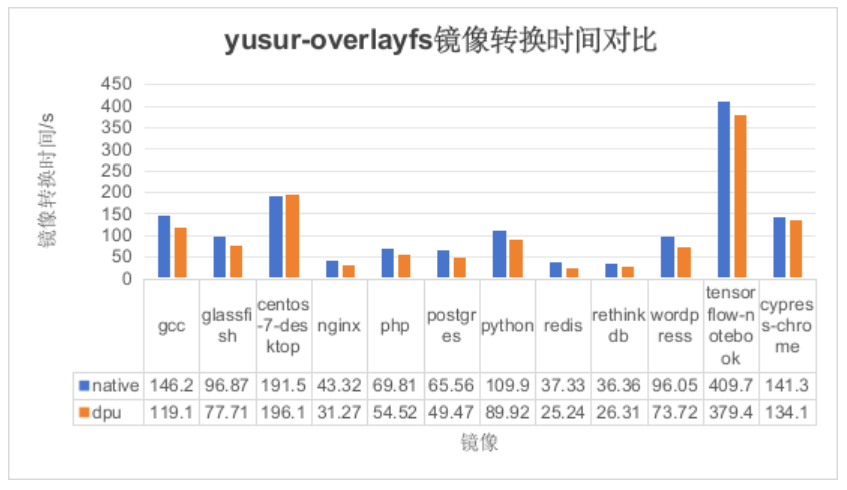
如上图所示,纵坐标表示不同模式下镜像转换时间(单位:秒),横坐标表示镜像名称。可以得出如下结论:
stargz两次测试结果:如图所示,CPU最高使用率20.17%,平均使用率4.22%。

overlayfs两次测试结果:如图所示,CPU最高使用率14.77%,平均使用率2.78%。

overlaybd两次测试结果:如图所示,CPU最高使用率11.4%,平均使用率3.27%。

yusur-overlayfs两次测试结果:如图所示,CPU最高使用率7.66%,平均使用率1.95%。
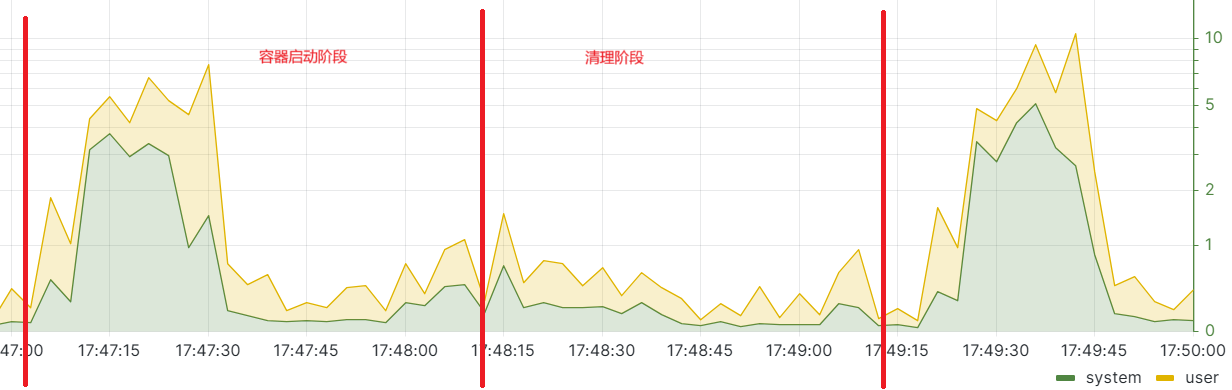
yusur-overlaybd两次测试结果:如图所示,cpu最高使用率10.02%,平均使用率2.17%。

整体使用率较yusur-overlayfs高,从system使用率观察可以得出是nbd这一层导致的。
汇总结果如下:

从以上所有图片,得出如下结论:
stargz两次测试结果:如图所示,最高内存使用7.67G,平均内存使用6.86G。

overlayfs两次测试结果:如图所示,最高内存使用5.71G,平均内存使用5.16G。

overlaybd两次测试结果:如图所示,最高内存使用5.21G,平均内存使用4.94G。

yusur-overlayfs两次测试结果:如图所示,最高内存使用5.28G,平均内存使用4.87G。

yusur-overlaybd两次测试结果:如图所示,最高内存使用5.62G,平均内存使用5.01G。

汇总结果如下:

从以上所有图片,得出如下结论:
4. 总结
4.1. 测试结果总结
4.2. 方案价值
基于DPU的容器冷启动加速解决方案具有如下价值:
1、提升服务响应速度和用户体验:在FaaS中,由于函数实例是动态创建的,首次调用函数时可能会遇到冷启动延迟,即容器从停止状态到运行状态所需的时间。快速冷启动技术能够显著缩短这一时间,使得用户请求能够更快地得到响应,从而提升用户体验。
2、提高业务吞吐量:快速冷启动使得FaaS平台能够在短时间内启动更多的函数实例,以应对突发的流量高峰,从而提高业务的整体吞吐量。
3、提高系统可用性:在微服务架构和分布式系统中,服务的快速冷启动可以确保在服务实例故障时,能够迅速恢复服务,减少服务中断时间,提高系统的整体可用性。
4、提升资源利用效率:控制面和数据面下沉至 DPU,有效减少了主机资源的消耗,这意味着在实际应用场景中,将大大节省了宝贵的CPU和内存资源,让这些资源能够被应用服务更高效地利用。
综上所述,基于DPU的容器冷启动加速解决方案对于提升服务响应速度和用户体验、提高业务吞吐量、提高系统可用性、提升资源利用效率等方面都具有重要的价值和意义,随着云原生和无服务器计算的不断发展,该方案将具有广阔的应用前景。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。
作者: Yusur_Tech, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3991230.html
版权声明:本文为博主原创,未经本人允许,禁止转载!





 /3
/3 





文章评论(0条评论)
登录后参与讨论