Arm 公司的首席软件工程师 Sandeep Mistry 为我们展示了一种全新的巧妙方法: 在 Raspberry Pi Pico 2 上如何将音频噪音抑制应用于麦克风输入。机器学习(ML)技术彻底改变了许多软件应用程序的开发方式。应用程序开发人员现在可以为所需系统整理包含大量输入和输出示例的数据集,然后使用这些数据集来训练 ML 模型。在训练过程中,ML 模型从输入和输出中学习模式。训练好的模型会被部署到设备上,这些设备会对来自真实世界的输入进行推理,并使用 ML 模型的预测输出来执行一个或多个操作。
这篇博客将深入探讨如何将基于现有 ML 的音频噪音抑制算法部署到新 Pico 2 板上使用的 RP2350 微控制器。RP2350 的双核 Arm Cortex-M33 CPU 使应用程序开发人员能够部署更多计算密集型应用程序,这些应用的性能超过了原始 Raspberry Pi Pico 板中使用的 RP2040 微控制器。
Hackster.io上使用Raspberry Pi Pico指南创建USB麦克风的屏幕截图
该算法背景介绍
2018年,Jean-Marc Valin 发表了一篇关于实时全带语音增强的混合DSP/深度学习方法的论文。本文介绍了如何使用基于递归神经网络(RNN)的ML模型来抑制音频源中的噪声。如果您有兴趣了解有关该算法的更多信息,请阅读Jean-Marc的RNNoise:学习噪声抑制页面。该页面涵盖了算法的详细信息,并包括交互式示例。该项目的源代码可在RNNoise Git存储库中找到。RNNoise的屏幕截图:学习噪声抑制页面在高层次上,该算法通过将信号分成 22 个频段,从 10 毫秒的 48 kHz 音频源中提取出 42 个特征。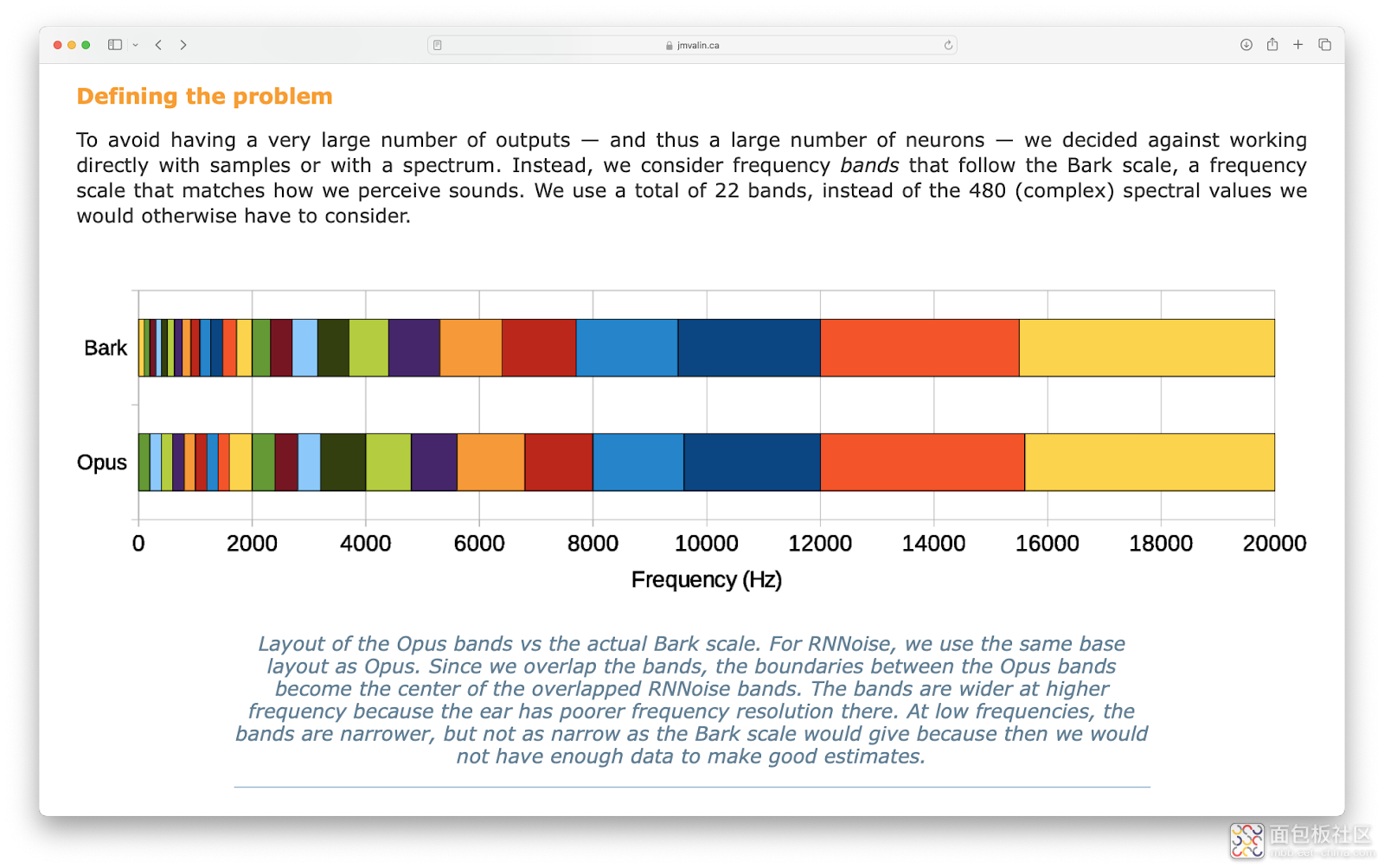
屏幕截图:RNNoise的“定义问题”部分:学习噪音抑制页面然后,42 个特征被用作神经网络的输入,神经网络会计算出 22 个频段的增益。计算出的增益可应用于原始音频信号,生成去噪版本。神经网络还会输出 "语音活动检测 "输出,该输出显示输入信号中存在语音的预测置信度,其值介于 0 和 1 之间。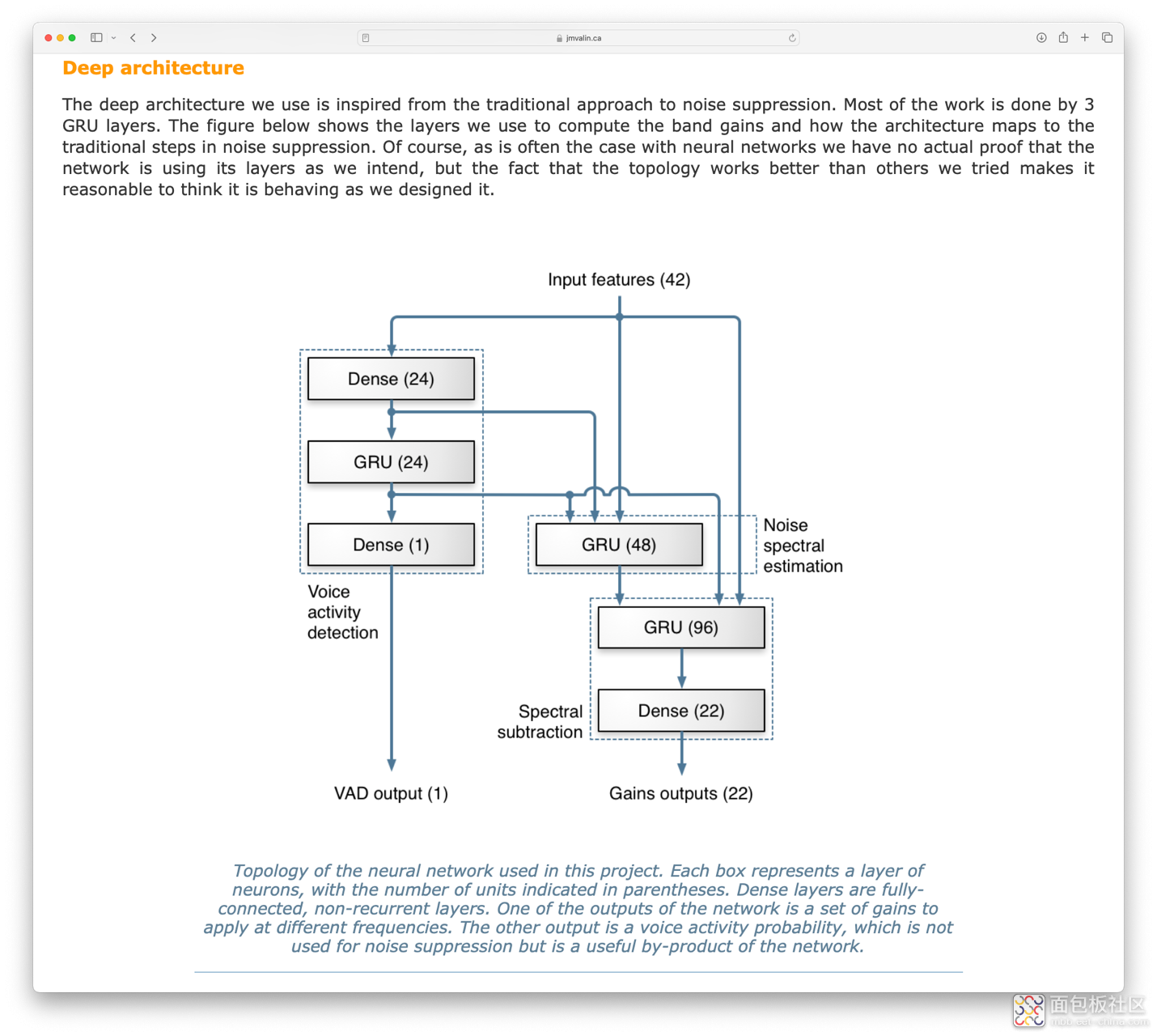
屏幕截图:RNNoise的“深度架构”部分:学习噪声抑制页面
移植和基准测试算法
RNNoise 项目的原始 C 代码可以集成到使用 Raspberry Pi Pico SDK 的 CMake 项目中。移植的所有源代码都可以在 GitHub 上的 rnnoise-examples-for-pico-2 代码库中找到。我们使用 RNNoise 项目 v0.1.1 中的 celt_lpc.c、denoise.c、kiss_fft.c、pitch.c、rnn.c 和 rnn_data.c 文件创建了一个新的 CMake 目标库。
对 denoise.c 稍作修改,以便在 biquad 函数中使用单精度浮点计算,并使用 log10f(...) 和 sqrtf(...) 代替 log10(...) 和 sqrt(...) 函数。
然后,可以将该库集成到一个基准测试应用程序中,调用 rrnoise_create(...)函数初始化模型,然后再测量 rnnoise_process_frame(...) 函数处理 480 个样本所需的时间。
要将此基准测试应用程序部署到 Raspberry Pi Pico 1 或 Pico 2 板上,首先要遵循 "Raspberry Pi Pico 入门 "C/C++ SDK 指南的第 2 节和第 9 节,然后运行以下命令来构建 .uf2 应用程序并部署到板上:git clone --recurse-submodules \ https://github.com/ArmDeveloperEcosystem/rnnoise-examples-for-pico-2.gitcd rnnoise-examples-for-pico-2mkdir buildcmake ... -DPICO_BOARD=pico2make rnnoise-benchmark
编译完成后,可以通过按住电路板上的白色 BOOTSEL 按钮将 examples/benchmark/rnnoise-benchmark.uf2 文件部署到电路板上,同时将 USB 电缆插入计算机并将 .uf2 文件复制到 Pico 的 USB 磁盘上。
以下是 Pico 1 和 Pico 2 板上的基准测试结果:
| Pico (RP2040) Cortex-M0+ @ 125 MHz | Pico 2 (RP2350) Cortex-M33 @ 150 MHz |
| rnnnoise_process_frame(...) | 372,644微秒 | 22,093微秒 |
原始的 Pico 1大约需要372.6毫秒,而新的 Pico 2 需要22.1毫秒:这是电路板之间的16.87倍速度。针对 16 kHz 音频修改算法
电路板要以 48 kHz 的采样率处理 480 个音频样本,就必须在 0.01 秒(480 / 48,000)或 10 毫秒内完成 rnnoise_process_frame(...)函数。Pico 2 的基准结果需要 22.1 毫秒,对于 48 kHz 音频来说还不够快,但对于处理采样率为 16 kHz 的音频来说已经足够快了,要求在 30 毫秒内完成音频处理。denoise.c 中的 eband5ms 变量可以轻松修改,以调整处理 16 kHz 数据的算法。该变量控制 22 个频段的起始范围。调整的方法是将原始值乘以 3(因为 16 kHz 音频采集样本的时间是 48 kHz 音频的 3 倍),并将最大起始位置设为 120。 以下是原始值:static const opus_int16 eband5ms[] = {/*0 200 400 600 800 1k 1.2 1.4 1.6 2k 2.4 2.8 3.2 4k 4.8 5.6 6.8 8k 9.6 12k 15.6 20k*/
0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 12, 14, 16, 20, 24, 28, 34, 40, 48, 60, 78, 100}
以及用于16 kHz音频的修改值:static const opus_int16 eband5ms[] = {/*0 200 400 600 800 1k 1.2 1.4 1.6 2k 2.4 2.8 3.2 4k 4.8 5.6 6.8 8k 9.6 12k 15.6 20k*/0, 3, 6, 9, 12, 15, 18, 21, 24, 60, 36, 42, 48, 60, 72, 84, 102, 120, 120, 120, 120, 120}
串行示例可编译并部署到电路板上,以测试修改后的算法。该示例通过 USB 连续循环接收 480 个 16 位音频样本,使用去噪算法对其进行处理,然后通过 USB 传输经过去噪处理的样本。在个人电脑上,可以使用 serial_denoise.py Python 脚本从文件中发送 16 位、16 千赫的原始音频,并将去噪音频保存到文件中。
这些原始值可导入 Audacity 等应用程序,用于可视化和回放。下面是一个例子:第一轨是原始音频(噪音),下面的第二轨是在 Pico 2 上去噪后的版本。
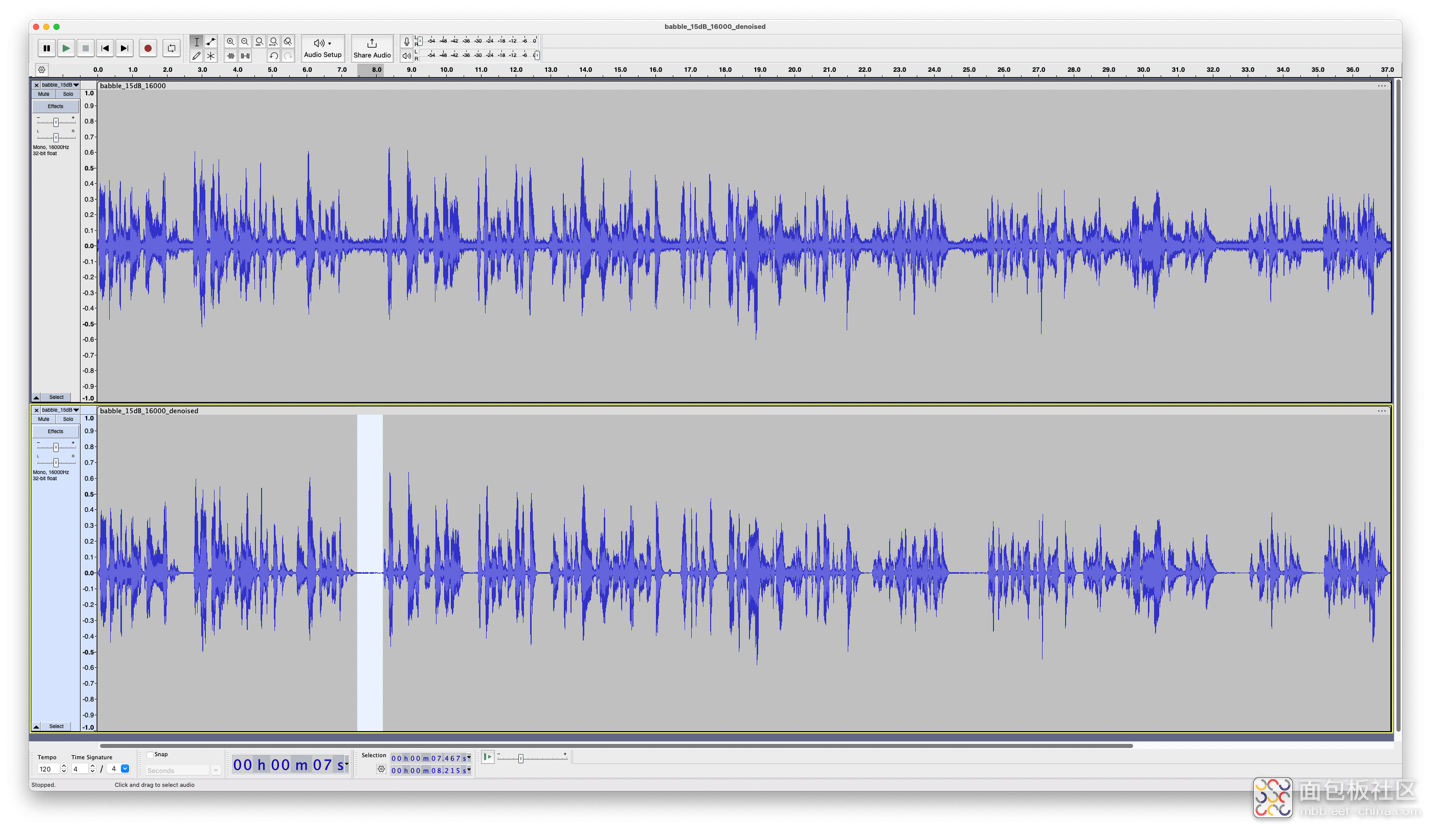
在Audacity应用程序的两个音轨的屏幕截图。
顶部:原始音频。底部:音频的去音版本。
我选择了一个噪声明显降低的区域。到目前为止一切顺利;该算法已通过验证,可在电路板上通过 USB 从个人电脑串流 16 kHz 音源!
将算法集成到USB麦克风应用程序中最初为 Pico 1 开发的 USB 麦克风应用程序现在可以通过板载去噪功能得到增强。硬件
此应用程序需要以下硬件:- Raspberry Pi Pico 2 主板
- Adafruit PDM MEMS 麦克风接口
- 半尺寸试验板
- 跳线
- 滑动开关(可选)
- 触觉按钮(可选)
可选的滑动开关将用作切换开关,以便在运行时禁用或启用噪声抑制处理,而可选的轻触开关则为重置电路板提供了方便。 连接硬件如下:
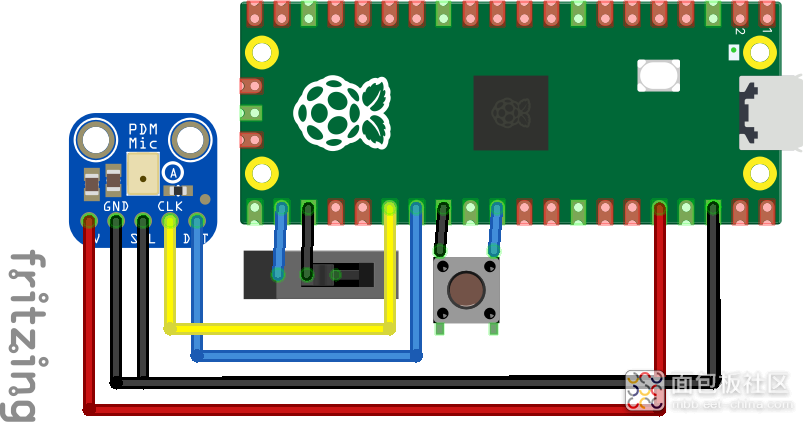
项目接线图
| Raspberry Pi Pico 2 | PDM MEMS 麦克风接口 | 滑动开关(可选) | 触觉按钮(可选) |
| 3V3(输出) | 3V |
|
|
| GND | GNDSEL | 中间针 | 底部针 |
| RUN |
|
| 顶部针 |
| GPIO21 | DAT |
|
|
| GPIO22 | CLK |
|
|
| GPIO17 |
| 底部针 |
|
接线完成后,你的试验板将看起来像这样:
软件应用程序将使用 microphone-library-for-pico 从采样率为 16 kHz 的 PDM 麦克风采集 480 个 16 位采样。该库将 RP2350 的可编程 I/O (PIO) 和直接内存访问 (DMA) 功能与 OpenPDM2PCM 库相结合,将原始 PDM 数据转换为脉冲编码调制 (PCM) 格式。16 位 PCM 数据被转换为 32 位浮点,并使用 RNNoise 算法进行去噪。然后,将去噪帧转换为 16 位整数,并使用 TinyUSB 库通过 USB 发送。USB 传输每 1 毫秒发送 16 个去噪采样。
带去噪功能的 USB 麦克风框图RP2350 上两个 Cortex-M33 内核都用于此应用。内核 1 从 PDM 麦克风捕获原始数据,对其进行过滤和去噪处理。内核 0 利用 TinyUSB 库和 RP2350 的 USB 接口通过 USB 传输去噪数据。
RNNoise 模型的语音活动检测输出将通过脉宽调制 (PWM) 显示在 Pico 2 的内置 LED 上。当 VAD 输出接近 1.0 时,LED 将变亮;当接近 0.0 时,LED 将熄灭。应用程序的源代码可在 rnnoise-examples-for-pico-2 GitHub 代码库的 examples/usb_pdm_microphone 文件夹中找到。该应用程序的编译方式与基准测试程序类似,使用以下 make 命令:
make rnnoise_usb_pdm_microphone编译完成后,按住 BOOTSEL 按钮并重置电路板后,即可将 examples/usb_pdm_microphone/rnnoise_usb_pdm_microphone.uf2 文件复制到 Pico 2 的 USB 磁盘中。
测试
应用程序加载到电路板后,可以使用 Audacity 测试音频录制,方法是首先单击音频设置按钮 -> 重新扫描音频设备,然后单击音频设置按钮 -> 录音设备 -> MicNode,再单击录音按钮。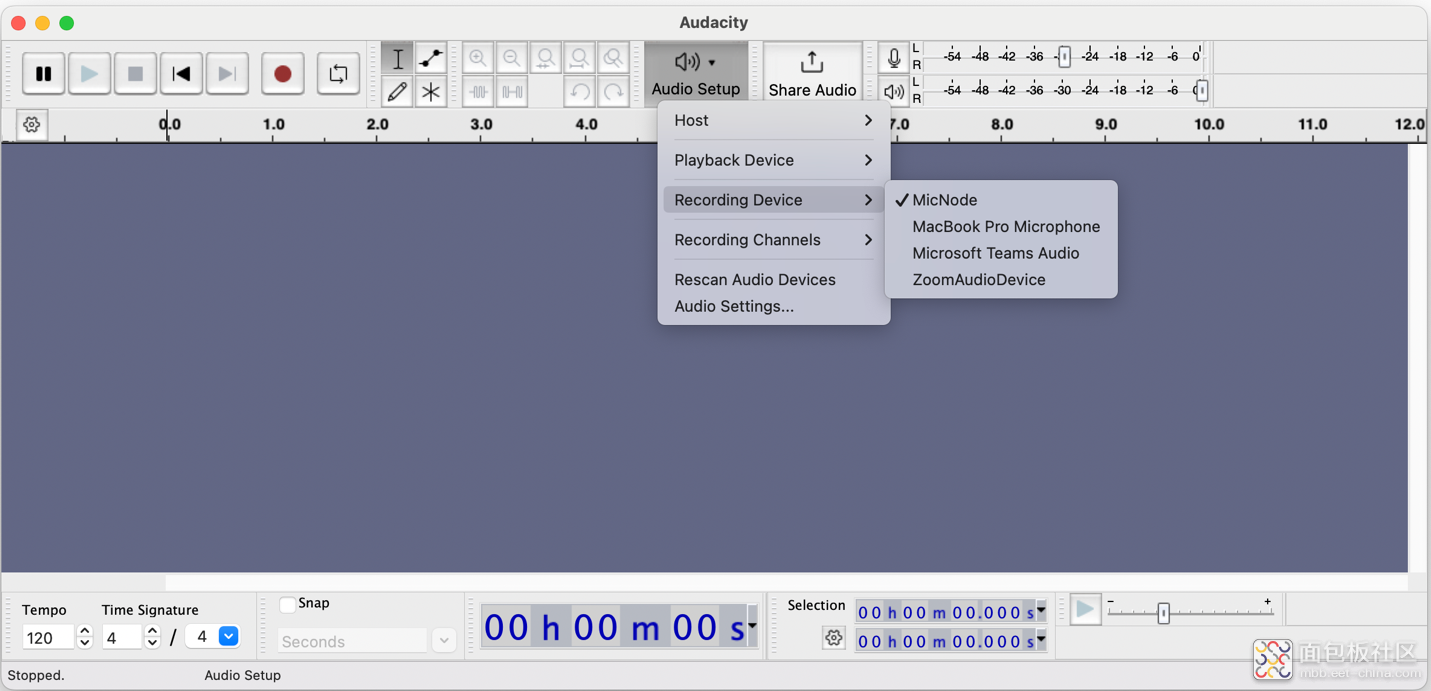
在Audacity中选择MicNode作为记录设备
如果连接了可选的滑动开关,则可以通过将开关滑向 Pico 2 的 USB 接口,来禁用噪声抑制功能,然后通过将开关滑离 USB 接口来重新启用噪声抑制功能。
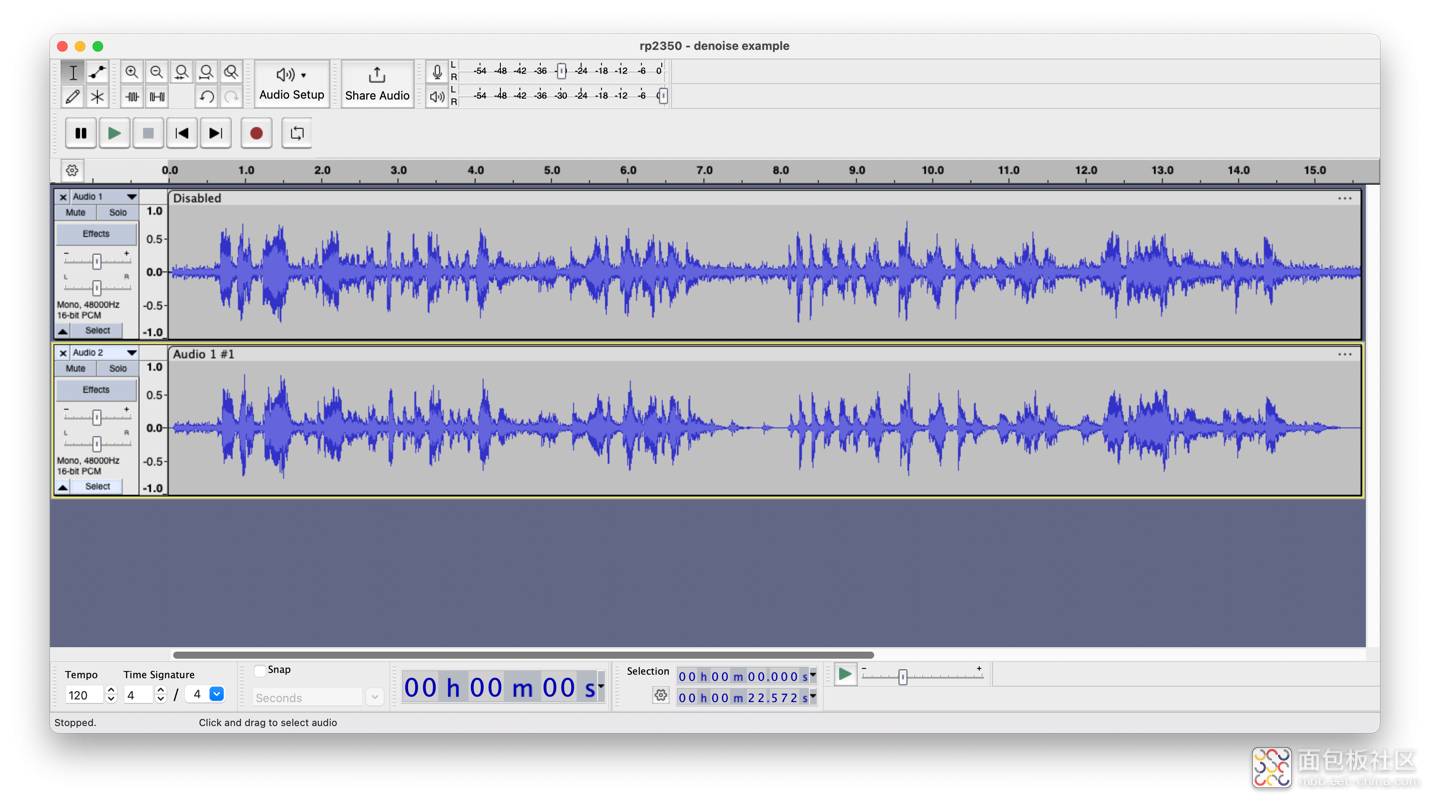
录音轨道截图
上轨:禁用去噪功能;下轨:启用去噪功能
下一步工作本博客演示了如何利用 Raspberry Pi Pico 2 的 Arm Cortex-M33 CPU 的额外计算能力,使用 ML 模型对从 PDM 麦克风捕获的 16 kHz 的 16 位实时音频数据进行去噪处理。去噪算法利用了 Cortex-M33 的浮点运算单元 (FPU),运行速度比原始 Pico 板上的 Cortex-M0+ 快 16.87 倍。该应用利用一个 CPU 捕捉、过滤和去噪数据,另一个 CPU 通过 USB 将音频数据传输到 PC。
下一步,您可以修改应用程序,在通过 USB 向个人电脑发送降噪数据之前添加自动增益控制 (AGC)。另外,去噪数据也可以直接在电路板上使用,作为另一种数字信号处理 (DSP) 算法或 ML 模型的输入,在核心 0 上运行,而不是 USB 栈。





 /5
/5 





文章评论(0条评论)
登录后参与讨论