
风风雨雨二十载,多少bug在心间。
代码编译不通过,急得抓耳直挠腮。
回想当年恩师讲,基础知道全忘干。
忙里偷闲回首看,权当引玉的抛转。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
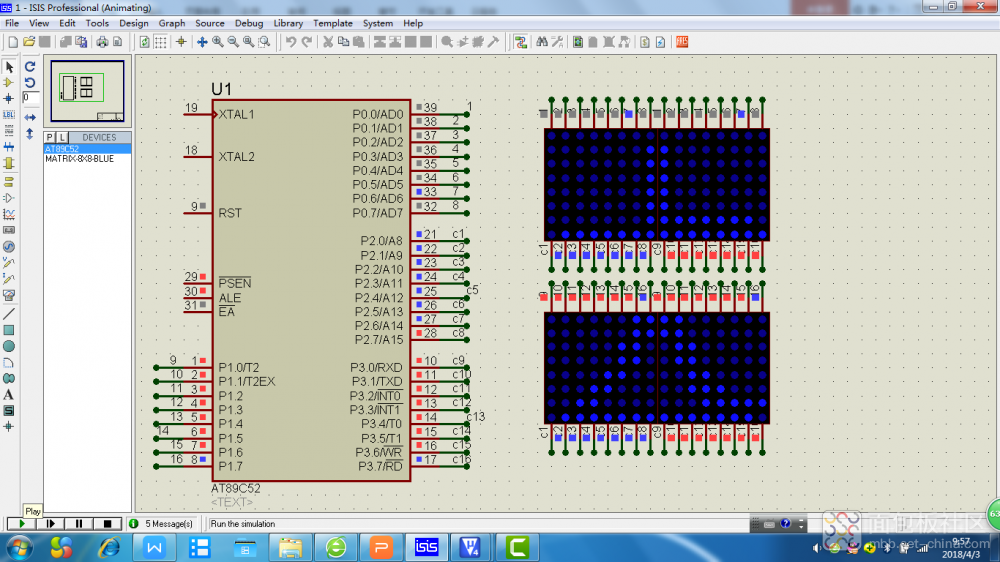
1、 电路图
HZK16字库是符合GB2312国家标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有 3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用就可以了。
我们知道一个GB2312汉字是由两个字节编码的,范围为0xA1A1~0xFEFE。A1-A9为符号区,B0-F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)
下面以汉字「我」为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。所以要找到「我」在hzk16库中的位置就必须得到它的区码和位码。
区码:汉字的第一个字节-0xA0,因为汉字编码是从0xA0区开始的,所以文件最前面就是从0xA0区开始,要算出相对区码
位码:汉字的第二个字节-0xA0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:offset = (94*(区码-1)+(位码-1))*32 。
注解:
区码减1是因为数组是以0为开始而区号位号是以1为开始的
(94*(区号-1)+位号-1) 是一个汉字字模占用的字节数
最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)
图示:
“我”的点阵输出如下图所示:

所以,“我”在HZK16*16点阵字库的存放序列为(一行一行地保存,共16行,每行2个字节,共32个字节):

2、 程序设计


 /5
/5 






文章评论(0条评论)
登录后参与讨论