
软件预读机制由来已久,首先实现预读指令的处理器是Motorola的88110处理器,这颗处理器首先实现了“touch load”指令,这条指令是PowerPC处理器dcbt指令[5]的雏形。88110处理器是Motorola第一颗RISC处理器,具有里程碑意义,这颗处理器从内核到外部总线的设计都具有许多亮点。这颗处理器是Motorola对PowerPC架构做出的巨大贡献,PowerPC架构中著名的60X总线也源于88110处理器。
后来绝大多数处理器都采用这类指令进行软件预读,Intel在i486处理器中提出了Dummy Read指令,这条指令也是后来x86处理器中PREFETCHh指令[6]的雏形。
这些软件预读指令都有一个共同的特点,就是在处理器真正需要数据之前,向存储器发出预读请求,这个预读请求[7]不需要等待数据真正到达存储器之后,就可以执行完毕。从而处理器可以继续执行其他指令,以实现存储器访问与处理器运算同步进行,从而提高了程序的整体执行效率。由此可见,处理器采用软件预读可以有效提高程序的执行效率。我们考虑源代码3‑1所示的实例。
源代码3‑1没有采用软件预读机制的程序
3.4.3 软件预读
软件预读机制由来已久,首先实现预读指令的处理器是Motorola的88110处理器,这颗处理器首先实现了“touch load”指令,这条指令是PowerPC处理器dcbt指令[5]的雏形。88110处理器是Motorola第一颗RISC处理器,具有里程碑意义,这颗处理器从内核到外部总线的设计都具有许多亮点。这颗处理器是Motorola对PowerPC架构做出的巨大贡献,PowerPC架构中著名的60X总线也源于88110处理器。
后来绝大多数处理器都采用这类指令进行软件预读,Intel在i486处理器中提出了Dummy Read指令,这条指令也是后来x86处理器中PREFETCHh指令[6]的雏形。
这些软件预读指令都有一个共同的特点,就是在处理器真正需要数据之前,向存储器发出预读请求,这个预读请求[7]不需要等待数据真正到达存储器之后,就可以执行完毕。从而处理器可以继续执行其他指令,以实现存储器访问与处理器运算同步进行,从而提高了程序的整体执行效率。由此可见,处理器采用软件预读可以有效提高程序的执行效率。我们考虑源代码3‑1所示的实例。
源代码3‑1没有采用软件预读机制的程序
int ip, a[N], b[N];
for (i = 0; i < N; i++)
ip = ip + a*b;
这个例子在对数组进行操作时被经常使用,这段源代码的作用是将int类型的数组a和数组b的每一项进行相乘,然后赋值给ip,其中数组a和b都是Cache行对界的。源代码3‑1中的程序并没有使用预读机制进行优化,因此这段程序在执行时会因为a和b中的数据不在处理器的Cache中,而必须启动存储器读操作。因此在这段程序在执行过程中,必须要等待存储器中的数据后才能继续,从而降低了程序的执行效率。为此我们将程序进行改动,如源代码3‑2所示。
源代码3‑2 采用软件预读机制的程序
int ip, a[N], b[N];
for (i = 0; i < N; i++) {
fetch(&a[i+1]);
fetch(&b[i+1]);
ip = ip + a*b;
}
以上程序对变量ip赋值之前,首先预读数组a和b,当对变量ip赋值时,数组a和b中的数据已经在Cache中,因而不需要进行再次进行存储器操作,从而在一定程度上提高了代码的执行效率。以上代码仍然并不完美,首先ip,a[0]和b[0]并没有被预读,其次在一个处理器,预读是以Cache行为单位进行的,因此对a[0],a[1]进行预读时都是对同一个Cache行进行预读[8],从而这段代码对同一个Cache行进行了多次预读,从而影响了执行效率。为此我们将程序再次进行改动,如源代码3‑3所示。
源代码3‑3软件预读机制的改进程序
int ip, a[N], b[N];
fetch(&ip);
fetch(&a[0]);
fetch(&b[0]);
for (i = 0; i < N-4; i+=4) {
fetch(&a[i+4]);
fetch(&b[i+4]);
ip = ip + a*b;
ip = ip + a[i+1]*b[i+1];
ip = ip + a[i+2]*b[i+2];
ip = ip + a[i+3]*b[i+3];
}
for (; i < N; i++)
ip = ip + a*b;
对于以上这个例子,采用这种预读方法可以有效提高执行效率,对此有兴趣的读者可以对以上几个程序进行简单的对比测试。但是提醒读者注意,有些较为先进的编译器,可以自动的加入这些预读语句,程序员可以不手工加入这些预读指令。实际上源代码3‑3中的程序还可以进一步优化。这段程序的最终优化如源代码3‑4所示。
源代码3‑4软件预读机制的改进程序
int ip, a[N], b[N];
fetch( &ip);
for (i = 0; i < 12; i += 4){
fetch( &a);
fetch( &b);
}
for (i = 0; i < N-12; i += 4){
fetch( &a[i+12]);
fetch( &b[i+12]);
ip = ip + a *b;
ip = ip + a[i+1]*b[i+1];
ip = ip + a[i+2]*b[i+2];
ip = ip + a[i+3]*b[i+3];
}
for ( ; i < N; i++)
ip = ip + a*b;
因为我们还可以对ip、数据a和b进行充分预读之后;再一边预读数据,一边计算ip的值;最后计算ip的最终结果。使用这种方法可以使数据预读和计算充分并行,从而优化了整个任务的执行时间。
由以上程序可以发现,采用软件预读机制可以有效地对矩阵运算进行优化,因为矩阵运算进行数据访问时非常有规律,便于程序员或编译器进行优化,但是并不是所有程序都能如此方便地使用软件预读机制。此外预读指令本身也需要占用一个机器周期,在某些情况下,采用硬件预读机制更为合理。
采用硬件预读的优点是不需要软件进行干预,也不需要浪费一条预读指令来进行预读。但硬件预读的缺点是预读结果有时并不准确,有时预读的数据并不是程序执行所需要的。在许多处理器中这种硬件预读通常与指令预读协调工作。硬件预读机制的历史比软件预读更为久远,在IBM 370/168处理器系统中就已经支持硬件预读机制。
大多数硬件预读仅支持存储器到Cache的预读,并在程序执行过程中,利用数据的局部性原理进行硬件预读。其中最为简单的硬件预读机制是OBL(One Block Lookahead)机制,采用这种机制,当程序对数据块b进行读取出现Cache Miss时,将数据块b从存储器更新到Cache中,同时对数据块b+1也进行预读并将其放入Cache中;如果数据块b+1已经在Cache中,将不进行预读。
这种OBL机制有很多问题,一个程序可能只使用数据块b中的数据,而不使用数据块b+1中的数据,在这种情况下,采用OBL预读机制没有任何意义。而且使用这种预读机制时,每次预读都可能伴随着Cache Miss,这将极大地影响效率。有时预读的数据块b+1会将Cache中可能有用的数据替换出去,从而造成Cache污染。有时仅预读数据块b+1可能并不足够,有可能程序下一个使用的数据块来自数据块b+2。
为了解决OBL机制存在的问题,有许多新的预读方法涌现出来,如“tagged预读机制”。采用这种机制,将设置一个“tag位”,处理器访问数据块b时,如果数据块b没有在Cache中命中,则将数据块b从存储器更新到Cache中,同时对数据块b+1进行预读并将其放入Cache中;如果数据块b已经在Cache中,但是这个数据块b首次被处理器使用,此时也将数据块b+1预读到Cache中;如果数据块b已经在Cache中,但是这个数据块b已经被处理器使用过,此时不将数据块b+1预读到Cache中。
这种“tagged预读机制”还有许多衍生机制,比如可以将数据块b+1,b+2都预读到Cache中,还可以根据程序的执行信息,将数据块b-1,b-2预读到Cache中。
但是这些方法都无法避免因为预读而造成的Cache污染问题,于是Stream buffer机制被引入。采用该机制,处理器可以将预读的数据块放入Stream Buffer中,如果处理器使用的数据没有在Cache中,则首先在Stream Buffer中查找,采用这种方法可以消除预读对Cache的污染,但是增加了系统设计的复杂性。
与软件预读机制相比,硬件预读机制可以根据程序执行的实际情况进行预读操作,是一种动态预读方法;而软件预读机制需要对程序进行静态分析,并由编译器自动或者由程序员手工加入软件预读指令来实现。
在一个处理器系统中,预读的目标设备并不仅限于存储器,程序员还可以根据实际需要对外部设备进行预读。但并不是所有的外部设备都支持预读,只有“well-behavior”存储器支持预读。处理器使用的内部存储器,如基于SDRAM、DDR-SDRAM或者SRAM的主存储器是“well-behavior”存储器,有些外部设备也是“well-behavior”存储器。这些well-behavior存储器具有以下特点。
(1) 对这些存储器设备进行读操作时不会改变存储器的内容。显然主存储器具有这种性质。如果一个主存储器的一个数据为0,那么读取这个数据100次也不会将这个结果变为1。但是在外部设备中,一些使用存储器映像寻址的寄存器具有读清除的功能。比如某些中断状态寄存器[9]。当设备含有未处理的中断请求时,该寄存器的中断状态位为1,对此寄存器进行读操作时,硬件将自动地把该中断位清零,这类采用存储映像寻址的寄存器就不是well-behavior存储器。
(2) 对“well-behavior”存储器的多次读操作,可以合并为一次读操作。如向这个设备的地址n,n+4,n+8和n+12地址处进行四个双字的读操作,可以合并为对n地址的一次突发读操作(大小为4个双字)。
(3) 对“well-behavior”存储器的多次写操作,可以合并为一次写操作。如向这个设备的地址n,n+4,n+8和n+12地址处进行四个双字的写操作,可以合并为对n地址的一次突发写操作。对于主存储器,进行这种操作不会产生副作用,但是对于有些外部设备,不能进行这种操作。
(4) 对“well-behavior”的存储器写操作,可以合并为一次写操作。向这个设备的地址n,n+1,n+2和n+3地址处进行四个单字的写操作,可以合并为对n地址的一次DW写操作。对主存储器进行这种操作不会出现错误,但是对于有些外部设备,不能进行这种操作。
如果外部设备满足以上四个条件,该外部设备被称为“well-behavior”。PCI配置空间的BAR寄存器中有一个“Prefectchable”位,该位为1时表示这个BAR寄存器所对应的存储器空间支持预读。PCI总线的预读机制需要HOST主桥、PCI桥和PCI设备的共同参与。在PCI总线中,预读机制需要分两种情况进行讨论,一个是HOST处理器通过HOST主桥和PCI桥访问最终的PCI设备;另一个是PCI设备使用DMA机制访问存储器。
PCI总线预读机制的拓扑结构如图3‑12所示。
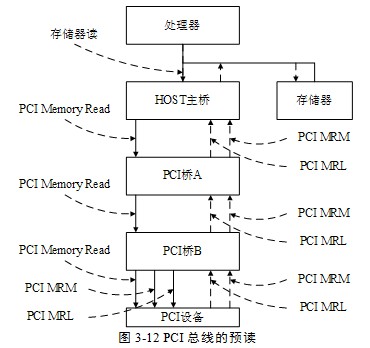
由上图所示,HOST处理器预读PCI设备时,需要经过HOST主桥,并可能通过多级PCI桥,最终到达PCI设备,在这个数据传送路径上,有的PCI桥支持预读,有的不支持预读。而PCI设备对主存储器进行预读时也将经过多级PCI桥。PCI设备除了可以对主存储器进行预读之外,还可以预读其他PCI设备,但是这种情况在实际应用中极少出现,本节仅介绍PCI设备预读主存储器这种情况。
PCI设备的BAR寄存器可以设置预读位,首先支持预读的BAR寄存器空间必须是一个Well-behavior的存储器空间,其次PCI设备必须能够接收来自PCI桥和HOST主桥的MRM(Memory Read Multiple)和MRL(Memory Read Line)总线事务。
如果PCI设备支持预读,那么当处理器对这个PCI设备进行读操作时,可以通过PCI桥启动预读机制(该PCI桥也需要支持预读),使用MRM和MRL总线事务,对PCI设备进行预读,并将预读的数据暂时存放在PCI桥的预读缓冲中。
之后当PCI主设备继续读取PCI设备的BAR空间时,如果访问的数据在PCI桥的预读缓冲中,PCI桥可以不对PCI设备发起存储器读总线事务,而是直接从预读缓冲中获取数据,并将其传递给PCI主设备。当PCI主设备完成读总线事务后,PCI桥必须丢弃预读的数据以保证数据的完整性。此外当PCI桥预读的地址空间超越了PCI设备可预读BAR空间边界时,PCI设备需要“disconnect”该总线事务。
如果PCI桥支持“可预读”的存储器空间,而且其下挂接的PCI设备BAR空间也支持预读时,系统软件需要从PCI桥“可预读”的存储器空间中为该PCI设备分配空间。此时PCI桥可以将从PCI设备预读的数据暂存在PCI桥的预读缓冲中。
PCI总线规定,如果下游PCI桥地址空间支持预读,则其上游PCI桥地址空间可以支持也可以不支持预读机制。如图3‑12所示,如果PCI桥B管理的PCI子树使用了可预读空间时,PCI桥A可以不支持可预读空间,此时PCI桥A只能使用存储器读总线事务读取PCI设备,而PCI桥B可以将这个存储器读总线事务转换为MRL或者MRM总线事务,预读PCI设备的BAR空间(如果PCI设备的BAR空间支持预读),并将预读的数据保存在PCI桥B的数据缓冲中。
但是PCI总线不允许PCI桥A从其“可预读”的地址空间中,为PCI桥B的“不可预读”区域预留空间,因为这种情况将影响数据的完整性。
大多数HOST主桥并不支持对PCI设备的预读,这些HOST主桥并不能向PCI设备发出MRL或者MRM总线事务。由于在许多处理器系统中,PCI设备是直接挂接到HOST主桥上的,如果连HOST主桥也不支持这种预读,即便PCI设备支持了预读机制也没有实际作用。而且如果PCI设备支持预读机制,硬件上需要增加额外的开销,这也是多数PCI设备不支持预读机制的原因。
尽管如此本节仍需要对HOST处理器预读PCI设备进行探讨。假设在图3‑12所示的处理器系统中,HOST主桥和PCI桥A不支持预读,而PCI桥B支持预读,而且处理器的Cache行长度为32B(0x20)。
如果HOST处理器对PCI设备的0x8000-0000~0x8000-0003这段地址空间进行读操作时。HOST主桥将使用存储器读总线事务读取PCI设备的“0x8000-0000~0x8000-0003这段地址空间”,这个存储器读请求首先到达PCI桥A,并由PCI桥A转发给PCI桥B。
PCI桥B发现“0x8000-0000~0x8000-0003这段地址空间”属于自己的可预读存储器区域,即该地址区域在该桥的Prefetchable Memory Base定义的范围内,则将该存储器读请求转换为MRL总线事务,并使用该总线事务从PCI设备[10]中读取0x8000-0000~0x8000-001F这段数据,并将该数据存放到PCI桥B的预读缓冲中。MRL总线事务将从需要访问的PCI设备的起始地址开始,一直读到当前Cache行边界。
之后当HOST处理器读取0x8000-0004~0x8000-001F这段PCI总线地址空间的数据时,将从PCI桥B的预读缓冲中直接获取数据,而不必对PCI设备进行读取。
PCI设备预读存储器地址空间时,需要使用MRL或者MRM总线事务。与MRL总线周期不同,MRM总线事务将从需要访问的存储器起始地址开始,一直读到下一个Cache行边界为止。
对于一个Cache行长度为32B(0x20)的处理器系统,如果一个PCI设备对主存储器的0x1000-0000~0x1000-0007这段存储器地址空间进行读操作时,由于这段空间没有跨越Cache行边界,此时PCI设备将使用MRL总线事务对0x1000-0000~0x1000-001F这段地址区域发起存储器读请求。
如果一个PCI设备对主存储器的0x1000-001C~0x1000-0024这段存储器地址空间进行读操作时,由于这段空间跨越了Cache行边界,此时PCI设备将使用MRM总线事务对0x1000-001C~0x1000-002F这段地址空间发起存储器读请求。
在图3‑12所示的例子中,PCI设备读取0x1000-001C~0x1000-0024这段存储器地址空间时,首先将使用MRM总线事务发起读请求,该请求将通过PCI桥B和A最终到达HOST主桥。HOST主桥[11]将从主存储器中读取0x1000-001C~0x1000-002F这段地址空间的数据。如果PCI桥A也支持下游总线到上游总线的预读,这段数据将传递给PCI桥A;如果PCI桥A和B都支持这种预读,这段数据将到达PCI桥B的预读缓冲。
如果PCI桥A和B都不支持预读,0x1000-0024~0x1000-002F这段数据将缓存在HOST主桥中,HOST主桥仅将0x1000-001C~0x1000-0024这段数据通过PCI桥A和B传递给PCI设备。之后当PCI设备需要读取0x1000-0024~0x1000-002F这段数据时,该设备将根据不同情况,从HOST主桥、PCI桥A或者B中获取数据而不必读取主存储器。值得注意的是,PCI设备在完成一次数据传送后,暂存在HOST主桥中的预读数据将被清除。PCI设备采用这种预读方式,可以极大提高访问主存储器的效率。
PCI总线规范有一个缺陷,就是目标设备并不知道源设备究竟需要读取或者写入多少个数据。例如PCI设备使用DMA读方式从存储器中读取4KB大小的数据时,只能通过PCI突发读方式,一次读取一个或者多个Cache行。
假定PCI总线一次突发读写只能读取32B大小的数据,此时PCI设备读取4KB大小的数据,需要使用128次突发周期才能完成全部数据传送。而HOST主桥只能一个一个的处理这些突发传送,从而存储器控制器并不能准确预知何时PCI设备将停止读取数据。在这种情况下,合理地使用预读机制可以有效地提高PCI总线的数据传送效率。
我们首先假定PCI设备一次只能读取一个Cache行大小的数据,然后释放总线,之后再读取一个Cache行大小的数据。如果使用预读机制,虽然PCI设备在一个总线周期内只能获得一个Cache行大小的数据,但是HOST主桥仍然可以从存储器获得2个Cache行以上的数据,并将这个数据暂存在HOST主桥的缓冲中,之后PCI设备再发起突发周期时,HOST主桥可以不从存储器,而是从缓冲中直接将数据传递给PCI设备,从而降低了PCI设备对存储器访问的次数,提高了整个处理器系统的效率。
以上描述仅是实现PCI总线预读的一个例子,而且仅仅是理论上的探讨。实际上绝大多数半导体厂商都没有公开HOST主桥预读存储器系统的细节,在多数处理器中,HOST主桥以Cache行为单位读取主存储器的内容,而且为了支持PCI设备的预读功能HOST主桥需要设置必要的缓冲部件,这些缓冲的管理策略较为复杂。
目前PCI总线已经逐渐退出历史舞台,进一步深入研究PCI桥和HOST主桥,意义并不重大,不过读者依然可以通过学习PCI体系结构,获得处理器系统中有关外部设备的必要知识,并以此为基础,学习PCIe体系结构。
本章重点介绍了PCI总线的数据交换。其中最重要的内容是与Cache相关的PCI总线事务和预读机制。虽然与Cache相关的PCI总线事务并不多见,但是理解这些内容对于理解PCI和处理器体系结构,非常重要。
[1] 为简便起见,下文将转移指令成功进行转移称为“Taken”;而将不进行转移称为“Not Taken”。
[2] 假定从访问Cache到发现Cache Miss需要一个时钟周期。
[3] PowerPC处理器使用dcbt指令,而x86处理器使用PREFETCHh指令,实现这种软件预读。
[4] 假定从Cache中获得数据需要一个时钟周期。
[5] dcbt指令是PowerPC处理器的一条存储器预读指令,该指令可以将内存中的数据预读到L1或者L2 Cache中。
[6] PREFETCHh指令是x86处理器的一条存储器预读指令。
[7] 预读指令在一个时钟周期内就可以执行完毕。
[8] 假定这个处理器系统的Cache行长度为4个双字,即128位。
[9] 假设中断状态寄存器支持读清除功能。
[10] 此时PCI设备的这段区域一定是可预读的存储器区域。
[11] 假设HOST主桥读取存储器时支持预读,多数HOST主桥都支持这种预读。


 /5
/5 






文章评论(0条评论)
登录后参与讨论