
一、实验内容<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
设x(n)为AR(1)信号,x(n)+ax(n-1)=ν(n),其中ν(n)为零均值,方差为
σw2的白噪声。设计一阶预测器,用x(n-1)估计x(n)。
由一阶自回归方程产生的信号x(n)的自相关rxx(m)= σw2(-a)|m|/(1-a2),为使σx2=1,即:rxx(0)= σw2/(1-a2)=1,则σw2=1-a2,取a=-0.99。
二、实验程序
function oneorderPredictor(mu)
N=1000;M=100;a=-0.99;
nu=normrnd(0,sqrt(1-a^2),N,M);
b_filter_coefficient=[1];a_filter_coefficient=[1,-0.99];
x=filter(b_filter_coefficient,a_filter_coefficient,nu);
y=zeros(N,M); w=zeros(N,M);
for j="1:1:M"
for i="1:1:N"
if i>1 temp=x(i-1,j);
else temp=0;
end
y(i,j)=w(i,j)*temp;
e(i,j)=x(i,j)-y(i,j);
w(i+1,j)=w(i,j)+mu*e(i,j)*temp;
end
end
w_mean=mean(w,2); plot(0:N,w(:,j),0:N,w_mean)
title('权重系数')
xlabel('迭代次数')
ylabel('权重值')
figure
mse=e.*e; mse_mean=mean(mse,2);
plot(0:N-1,e(:,j),0:N-1,mse_mean)
title('均方误差')
xlabel('迭代次数')
ylabel('均方误差值')
三、运行图如下
1、下图为mu=0.05时的权重系数图和均方误差图
在matlab的command windows里面输入oneorderPredictor(0.05)得到:
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
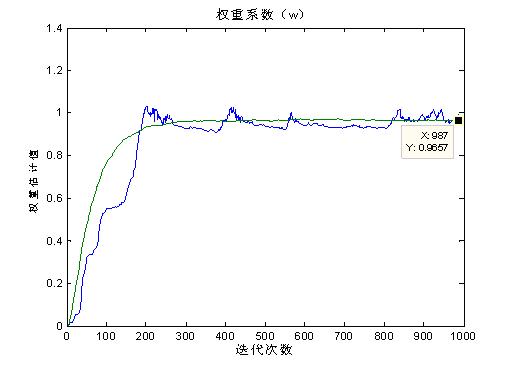
图一 权重系数图
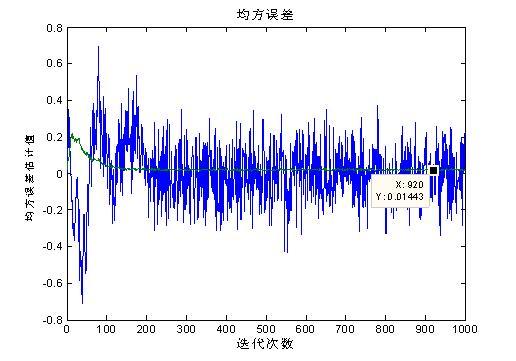
图二 均方误差图
由图一可以看到,最优权重系数的估计值w的均值,随迭代次数的增加最终趋近于0.9657,单次实现时,w的曲线上下波动,而平均后曲线则平滑了许多。。由题意可得:y(n)==wx(n-1),此时信号x(n)的自相关距阵Rxx=rxx(0)=1。因为我们是用x(n-1)去估计x(n),则互相关矢量rdx=rxx(1)=-a。根据维纳-霍夫方程:Rxxw=rdx,可以求出最佳滤波器系数wo=Rxx-1rdx=-a=0.99。这个与我们用matlab防真出来结果非常地接近。
由图二可以看到,均方误差估计值随迭代次数的增加最终趋近于0.01443,此时自适应滤波器的权重系数达到最佳值。同样,单次实现时,曲线上下波动,而平均后曲线则平滑了许多。我们理论计算均方误差J=E[e(n)e*(n)]=σd2-rdxHw
-wHrdx+wHRxxw=1-a2-a2+a2=1-a2=1-0.992=1-0.9801=0.0199。由此可以看到理论分析与matlab分析结果相符。
2、当mu分别取0.1、0.05、0.01时,看均方误差的收敛速度。
程序清单如下:
function oneorderPredictor1(mu)
N=1000;M=100;
a=-0.99;
v=normrnd(0,sqrt(1-a^2),N,M);
b=[1];a=[1,-0.99];
x=filter(b,a,v);
y=zeros(N,M);
w=zeros(N,M);
for j="1:1:M"
for i="1:1:N"
if i>1 temp=x(i-1,j);
else temp=0;
end
y(i,j)=w(i,j)*temp;
e(i,j)=x(i,j)-y(i,j);
w(i+1,j)=w(i,j)+mu*e(i,j)*temp;
end
end
mse=e.*e;
mse_mean=mean(mse,2);
plot(0:N-1,mse_mean)
title('均方误差')
xlabel('迭代次数')
ylabel('均方误差值')
在matlab的command windows里面输入oneorderPredictor1(0.01),然后输<?xml:namespace prefix = w ns = "urn:schemas-microsoft-com:office:word" />入hold on,再输入oneorderPredictor1(0.05)、oneorderPredictor1(0.1),就可以得到图三。

图三 mu取不同的均方误差
可以观察到当mu=0.01时,均方误差达到最小也即自适应滤波器的权重系数达到最佳值,需要的迭代次数大概为500次;当mu=0.05时,均方误差达到最小,需要的迭代次数大概为200次:当mu=0.1时,均方误差达到最小,需要的迭代次数大概为120次。
可以得出,收敛因子mu值越大,自适应过程收敛越快,即自适应滤波器的权重系数达到最佳值越快。



 /5
/5 






文章评论(0条评论)
登录后参与讨论