
Quartus II流水线均衡负载设置实例<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
受riple兄的《图解用register balancing方法解决时序收敛问题一例》启发,对Quartus II的组合逻辑流水线优化功能进行初探,拿一个小例子的测试结果和大家分享。
该工程只对主时钟做了如下约束,希望时钟能跑到100MHz:
create_clock -name {clk} -period 10.000 -waveform { 0.000 5.000 } [get_ports {clk}]
最后的timing report显示Fmax只有95.41 MHz,未达到预期要求。
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
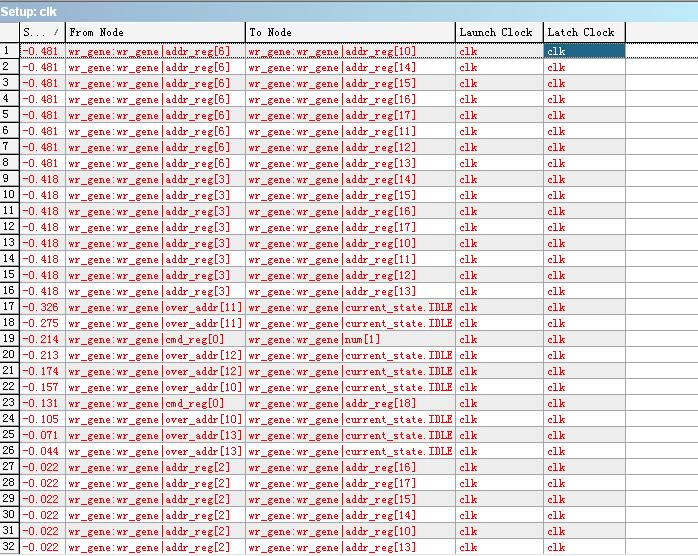
查看关键路径发现不满足Setup Slace主要是寄存器addr_reg和over_addr,那么当我在这些寄存器间再添加一级寄存器做流水线优化,并且需要在Quartus II的Synthesis Netlist Optimizations设置选项中,使能Perform gate-level register retiming;同时在Quartus II的Physical Synthesis Optimizations设置选项中,使能Perform register duplication和Perform register retiming两个选项,让Quartus自动优化寄存器间的组合逻辑。此时综合并布局布线后查看timing report会达到我们预期的目的吗?
时序报告显示Fmax=100.49MHz,对于我们设定的100MHz时钟没有时序违规,但是在达到速度的同时我们也付出了面积的代价(优化前使用了EPM570的358个LC,而优化后使用了373个LC)。
另外要说明的是,在没有勾选Quartus II的相应优化选项而只是简单的增加一级流水线的情况下,时钟依然跑到了100.37MHz(几乎和优化后的最高频率一样),而付出的LC仅有359个,那么所谓的优化到底又是优化了什么呢?带着这个疑问,特权同学反复对比了三种不同情况下的Technology Map Viewer后,发现了问题所在。
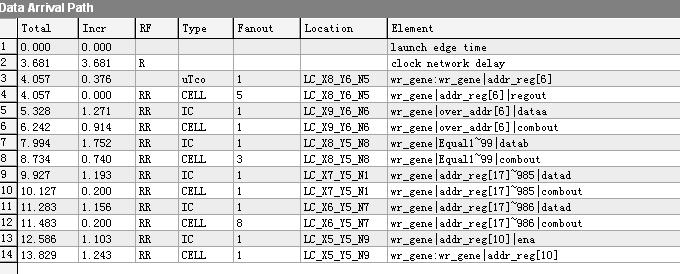
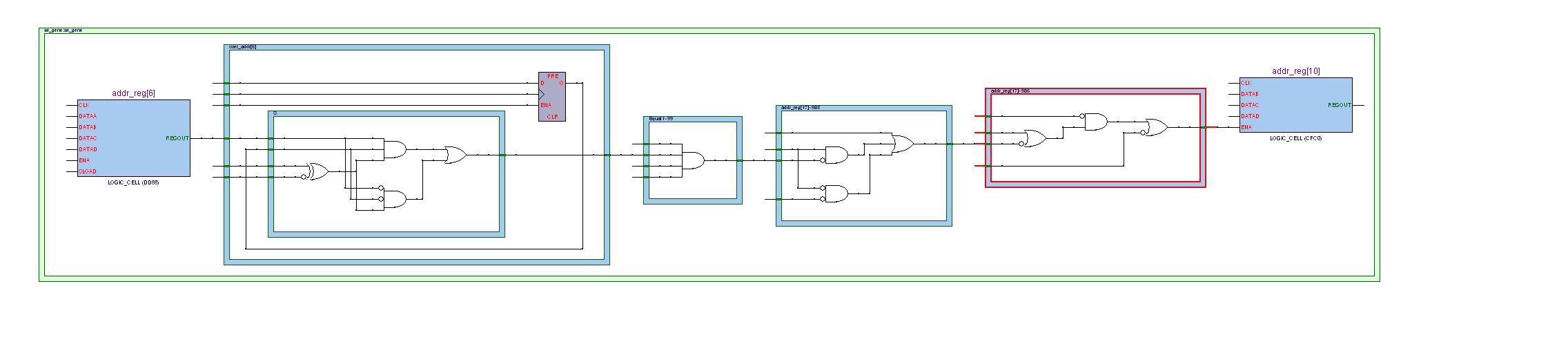
下面是在不添加流水线寄存器时,时序违规中最坏路径从addr_reg[6]到addr_reg[10]的视图。可以看到这两个寄存器间的组合逻辑还是比较复杂的,也难怪会出现时序违规。
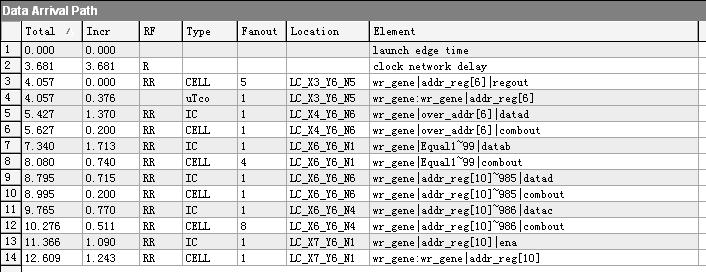
那么再看看添加了一级流水线寄存器的情况(未进行优化选项设置),相同的路径:
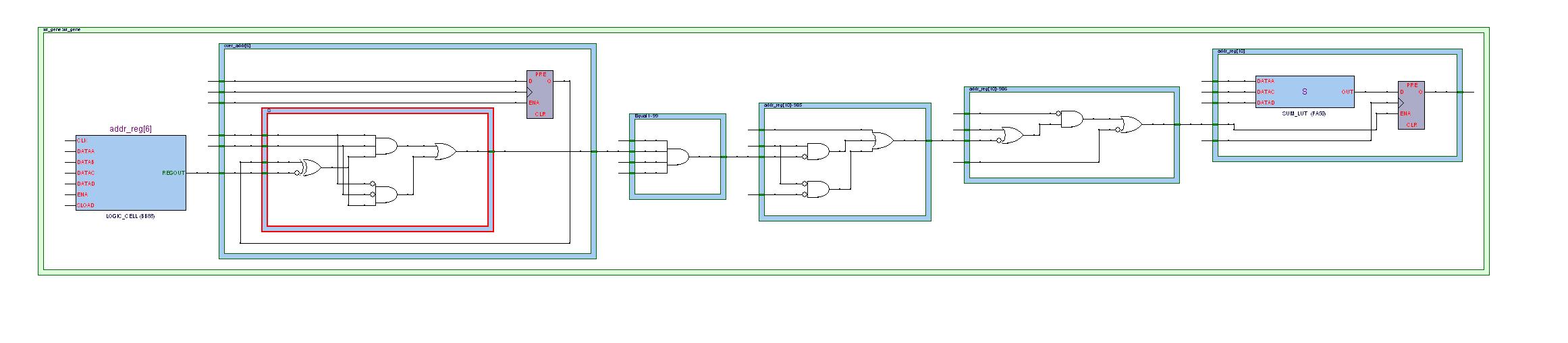
最后看添加一级流水线寄存器而且优化后的视图:

比较这三者,我个人感觉优化后的效果并不明显。先看不进行优化,而只是添加一级流水线的情况,组合逻辑没有任何改善,但是时钟频率的提高应该是因为多了一级的寄存器锁存,从而使得底层的布局布线更加游刃有余了吧。而给予厚望的最后一种优化后的效果其实也不尽如人意(至少从寄存器addr_reg[6]到addr_reg[10]路径上看是这样)。
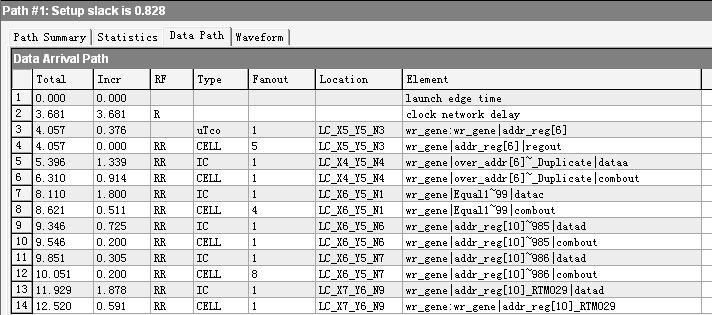
做了半天,才发现其实最后的结论和自己预期的结果背道而驰,这让我好是郁闷,最后只能求救于quartusii_handbook了。找到了关于前面的Perform register duplication和Perform register retiming两个选项的说明,截图如下:
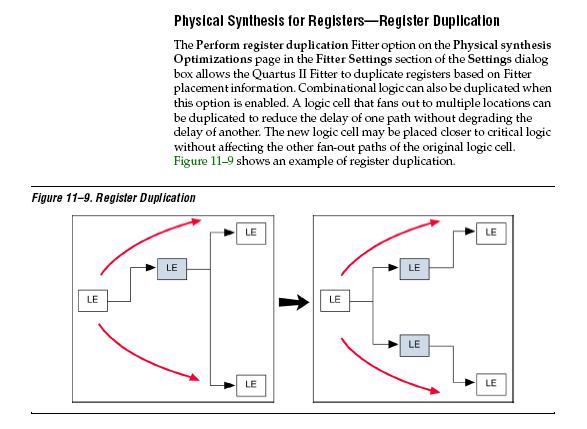

Perform register duplication顾名思义应该就是指执行寄存器逻辑复制功能吧,Figure 11-9很生动的给出了例图。我个人以为如此优化的效果应该是要通过减轻扇出较大的LE,将原来负载比较大的路径分割成多条通道,从而减少路径延时达到提高频率的目的(亦面积换速度)。
Perform register retiming选项单看上面的解释还不行,于是再参考了Gate-Level Register Retiming选项,给出两个例图如下:
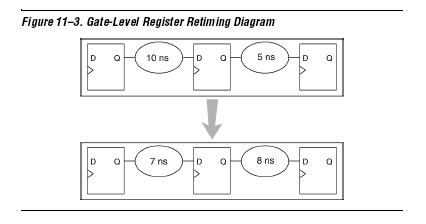
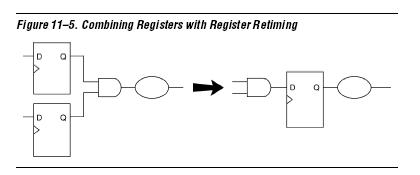
明言人看图应该都明白了该选项的优化效果了,确实是实现把两个寄存器间大的组合逻辑均衡成两个小的组合逻辑,从而提高系统频率。但是该优化选项其实是有例外的:

又绕了那么一圈,再回头仔细分析路径上的组合逻辑。对比后二者的视图发现,最后优化的逻辑视图中明显的发生了一些微妙的变化,首先好像多了一些逻辑路径,其次有些LUT的位置似乎也发生了变化。最后来说,总的数据到达时间缩短了,也就是说速度提高了。
似乎还是没有太说明问题(也许是提出来这条路径不太恰当,说明不了什么),但是不要紧,有了这个工具有了这个方向我们可以慢慢研究,继续探讨。
补充:
很巧的是今天听Altera的官方培训课程时遇上了这一段讲解,回过头来,这不正是我所困惑的问题吗。下面引用原文说法(记得当年老师总是教育我们“好记性不如烂笔头”,那么特权同学就做了同声记录,呵呵):
Synthesis Netlist Optimizations(综合网表优化)可以提高当前设计的性能,它提供了根据适配器结果来调整综合的选项,默认情况下并没有打开该选项。您可以执行What you see is what you get机元重新综合来来改进第三方综合工具的结果,或者使用门级寄存器重新定时来均衡寄存器之间的时序延时。What you see is what you get是将第三方工具产生的网表还原为基本的逻辑门,然后再由Quartus II的综合器更加有效的重新映射到Altera器件的各种通用资源中去。所以,它仅仅为使用第三方工具的设计有效。
这里的gate-level register retiming(门级寄存器重新定时)是指在门级重新调整关键和非关键路径的长短,前提是保证功能不变。
Fitter Settings(适配全局设置)使您能够调整设计适配的质量,当代价是额外的编译时间。默认的自动适配会运行适配器直到符合您的设计要求。标准适配运行适配器直到找到可能的绝对最佳结果,而不论是否符合或者超过您的要求。快速适配将编译时间缩短了近50%,但可能导致设计性能的降低。
最后,在适配全局设置的子菜单中,可以设置物理综合的相关选项。您可以根据布局布线或者时序要求,利用所选择的综合网表优化选项使能物理综合以及重新综合。物理综合平均能提高5%的性能,但是根据设计和所选择的选项最大达到25%到30%。和其他选项类似,您可以选择优化的努力等级。
下面一起来看看物理综合选项是如何完成优化的。
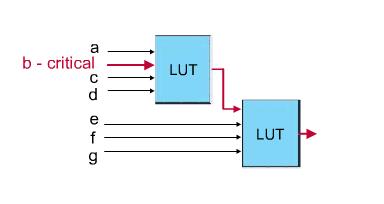
对组合逻辑的物理综合,是通过LUT端口的交换来减少一些关键路径所经过的逻辑单元数量来提高Fmax。如图中的b和e交换,使关键路径b的延时大大减少,从而大大的提高了它的工作频率。
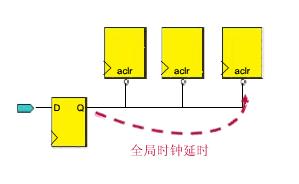
异步信号流水线的物理综合是将快速时钟域的异步控制信号,如图中的aclr信号从全局时钟资源移到局部时钟资源,从而减少各级时钟信号的延时,使异步电路的remove和recover条件得到满足,优化它们的性能。
(在非常快的时钟域,加入流水线寄存器,异步清除或者装入信号)
物理综合中的复制是将大扇出的逻辑单元完全不变的copy到设计中的空余资源中,从而减少它们的扇出,这样也能够提高当前设计的工作频率(和特权上文里分析的一个意思)。
总之,刚才介绍的所有物理综合选项都是针对布局布线的网表进行,不会影响任何综合和源代码。

用户400350 2011-11-24 21:25
用户1567315 2011-11-24 11:45
用户1573081 2011-11-5 01:31
用户1580105 2011-11-1 09:55
用户385471 2011-7-11 14:16
用户1271802 2011-7-11 08:43
用户333178 2011-6-14 09:20
用户400850 2011-6-8 09:45
用户1650082 2011-6-7 16:05
xucun915_925777961 2011-6-7 13:02