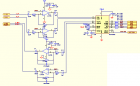
1路视频光端机硬件原理详细设计 记录编号: X XXXXX 一、 项目编号: X XXXX 二、 项目名称: 1路视频光端机(国办方案) 三、 版本: X XXXXXX 四、 用模块图表示设计原理 整对 PCB采用2片 EPM3128A 数据复用芯片 1 片国办的 DS92LV1212A / DS92LV1 021 A 芯片 , 1片AD9708 和AD9280 A/D转换芯片 1片MAX488 MAX3232 PCM3008T 芯片 ,组成一对1路视频 1路双向音频 1路双向数据(RS485/422 RS232 ) 的收发数字视频光端机。 整个主板主要分七大部分:电源电路部分、视频模拟电路放大滤波部分、模拟 /数字转换部分、cpld数字信号复用和时钟处理部分、G-LINK 高速串行编解码部分、光模块电路部分、音频数据部分。 五、 各部分原理说明 I 、电源电路 由电源插座引入 220V交流电源,经一块YAS-5.0 AC/DC开关电源模块 产生 +5V/2.4A直流电源供应布在PCB板上的OP691 OP690 LM353 MAX488 芯片设备。 独立的 AD芯片, EPM3128A 数据复用芯片 , DS92LV1 021 A serializer芯片 的电源电路采用AS1117芯片稳压电路构成,产生系统的+3.3V的电源。 1、 AS1117() ① 、供应 AD9280/9708芯片74LC14芯片, EPM3128A 数据复用芯片 ,其电源网络标号是 “+ 3.3 V”。 ② 、供应音频处理芯片 PCM3008T的数字PIN5,其电源网络标号是 “+3.3AU”。 ③ 、供应 RS3232芯片VCC接口,其电源网络标号是 “”。 ④、供应 DS92LV1 021 A serializer芯片,其电源网络标号是 “+3.3LVA” “+3.3LVD” 2 RS3232 芯片PIN3提供 -5V 电压给OPA690 ,其电源网络标号是 “ – 5A ”和 提供给OPA691 ,其电源网络标号为 “ – 5B ”。 3 +5V/2.4A直流电源 供应光收发模块的TTL 电路电源网络标号为“+5V ” . ① 、供应 电压放大器 OPA690 ,其电源网络标号“+5A ” . ② 、供应电流放大器 OPA691 , 其电源网络标号“+5B ” 。 ③ 、供应 MAX488芯片 ,其电源网络标号 “ +5DA ” . ④、供应LM358 芯片,其电源网络标号 “ +5AU ” . 在电源的总输出处加入 L24(22UH/2A)的滤波电感以提高电源的信噪比。 II、 CPLD 芯片 电路部分 该电路采用 EPM3128A数字复用 芯片 。 主要特性如下: · 芯片实现数据并行复用 · QFP1 00 封装, 3.3V 供电。 Ⅲ、 Video 视频部分 本设备视频发射和接收部分主要采用了国办的 OPA690 电压反馈放大芯片,OPA691电流反馈放大 芯片、 LM1881 视频同步分离芯片、LC三阶低通滤波电路、AD9280/9708 模数转换芯片搭建而成。 TX 发射端的视频信号输入先经过 OPA691 电流反馈放大电路部分在传输到三阶8mhz低通滤波电路 传到 AD9280 的ADC 处理传给CPLD的复用 ,再把视频信号传给LVDS 芯片变成高速串行信号输出到 TTL电平的光模块电路转成光信号传到远端接收部分。 RX ⑴ 、 LM1881 视频同步分离器芯片电路 LM1881 行场同步分离模块 ( 视频同步信号提取电路 ) 芯片性能: 1、定时提取视频的同步信息,包括复合同步视频信号和垂直信号、脉冲时沿,在这里应用是分离出复合同步信号给 D7,信号在经过三极管Q1得放大电路 把信号传给CPLD处理、和 通过同步信号分离模块将外输入的视频信号中的行场同步信号分离出来,该分离信号引入 AD9280 。 2、LM1881 的第8脚VCC 5V电压输入,C13 0.1uf C106 0.01uf电容起去耦 提供低阻抗通路 作用。 C14 0.1uf 起耦合作用 C105 470pf电容起滤波作用。 Lm1881 硬件框图 ⑵ 、 OPA691 电流反馈放大芯片 OPA690 电压反馈放大芯片电路 OPA691 将宽带的电流反馈型运算放大器提高到一个崭新的水平。一般情况下工作在 5.1mA 的极低 供电电流,当在更高的供电电流下工作时 ,OPA691可满足高的压摆率 (2100V/us) 及输出功率 (190mA),是多路广播视频接口应用的选择。 OPA690 具有稳定的单位增益、带禁用端的电压反馈型运算放大器,它可提供先前只在宽带电流反馈放大器中才具有的压摆率及满功率带宽。OPA690 采用 +5V 单电源,在超过 150mA的 驱动电流和150MHz 带宽的条件下,提供 1V至4V 的输出动态范围,奠定了其在 RGB 线驱动以及单电源 ADC 输入驱动器中的性能。双路的 OPA2690 可支持高压摆率的差分输入输出,单个三路 的OPA3690 更能实现有源高阶滤波。 特性 · 宽电源范围: 5V 到 12V 的单电源、+/-2.5 到 +/-6V的双电源 · 高输出电流: +/-190mA(+/-250mA限流) · 高压摆率: 2100V/us (OPA691) · 输出电压范围: +/- 5 V TX: OPA691 电流反馈放大电路部分 RX:OPA691 电流反馈放大电路部分- RX:OPA690 电压反馈放大器电路部分 ⑶ 视频 A/D 模拟数字转换部分电路。 AD9280 ADC : ① CMOS 8 bit 编码 32MSPS 采样 ; 可实现数据的多通道传输低电压高速采样 ② 高性能低电压 ,在3V 电压工作模式下功耗为:95mw (3v ),在休眠工作模式下功耗仅为5mw; ③ 可调的芯片参考电压 ; ④ 多种模式选择 见图如下 : TX:AD9280 模转数电路部分 参考电压工作模式设置 :在1V模式下是内部参考电压把REFSENSE 和VREF 连接;在2V模式是把REFSENSE 接地;外部驱动模式是在1V 2V模式增加电阻;外部参考模式是使能给REFTS REFBS VREF pin 信号输入采用 Differential 模式AIN 驱动一个信号输入,REFTS OR REFBS 连接驱动另一个输入,此模式PIN 要打到AVDD/2 才能达到最佳模式. INPUT 输入和参考电压部分的关系是 (REFTS-VREF/2) ≤ AIN ≤ (REFTS+VREF/2) ,是由VREF 输出参考来决定AIN 的范围在顶层参考和底层参考的范围之间比值为1V :2V . 电路在芯片的 REFTF 和 REFBF 搭建了去藕网络-短路两个PIN 并联上10uf和0.1分电容及串上两个0.1uf对接地电容,芯片参考电压VREF PIN 要旁路给AVSS (analog ground) 1.0uf 电容和并上0.1uf电容. AD9280 可以DIFFERENTIAL 输入信号,可以短路REFTS 和REFBS pins 驱动differential 信号,在这种配置下,AD9280 可以接受1V P-P 的信号. AD芯片5-12 pin 是输出8位的并行数据到CPLD 复用芯片.时钟信号的CLK输出到cpld . RX:AD9708 数转模电路部分 AD9708 DAC : ① 高性能低电压数子到模拟转换器 ,在3V 电压工作模式下功耗为:45mw (3v );在5V 的工作电压下功耗为175MW ,在休眠工作模式下功耗仅为20mw @ 5V; ② 模拟和数字部分的电压为图中 AVDD DVDD,支持电压范围再2.7v-5. 5v , 数字部分可以运行在 125MSPS 的时钟速率下 ③ 输出电流在 2MA -- 20ma .外围电阻结合内部参考放大器 参考电压 V REF 来调整 I REF ④ 芯片的每个针脚( pin)的定义见下表: ⑤ 芯片要求输出阻抗大于 100K欧 ,所以电路图中可见芯片的IOUTA IOUTB 输出PIN 的外接电路的加上了51欧的下拉电阻R63 R64及22pf 的C116 C117滤波及采用510欧的R56 R57 电阻对输出信号达到要求的阻抗。 ⑥ 电路中芯片的 FSADJ PIN 要求外接2K欧对地的R67 电阻,用来控制数字信号的输出电流. ⑦ 芯片分模拟和数字两部分,在接地和供电方面也要求,接地 ACOM DCOM 和供电AVDD DVDD 要分开,不能通用。 ⑧ 电路中芯片的 REFLO 参考地和ACOM 模拟地连接,才能REFIO 参考输出电压要达到1.2V ,这样需要REFIO外接补偿 0.1uf 电容。 ⑷ 三阶低通滤波电路部分 。 视频信号经过 OPA691放大后进入8MHZ 的三阶低通滤波电路,对信号的优化后传到AD9280转换芯片进行AD转换处理. Ⅳ LVDS 国办芯片部分 本设备串并数据转换部分采用国办的 DS92LV1021A 和DS92LV1212A 芯片 ,把并行数据转换成高速的串行数据最后传给TTL电平的光模块转称光信号传给远端的设备,在由接收端DS92LV1212A芯片解出串行信号恢复出同步的并行信号。两边采用的同步时钟为16.384MHZ. ⑴ TX :DS921021A 电路部分 ⑵ R X :DS921212A 电路部分 Ⅴ、 AUDIO 部分 本设备得音频部分是采用 PCM3008T 芯片搭建的双向立体声的电路通道。PCM3008T 芯片是低成本数字立体声音频处理芯片,16bit 的ADC 和 DAC ,8khz-48khz 采样、 Ⅵ RS488/422 RS232数据部分 Ⅶ 时钟晶振电路部分 设备时钟采用 Ⅷ 指示灯部分 Ⅸ 光模块 光模块采用的是普通的 1×9针光模块,采用+5V供电, 发射是1.25G PECL电平和155M TTL电平的双向光模块,主芯片工作电压为+3.3V,因此使用交流耦合。 光接收检测信号 ,此信号分两路,送LVDS1021/1212A 光口信号检测输入。经LVDS1021A组成的并转串电路转换成串行光信号送入发送至对端设备。

 标签: 实战
标签: 实战



