
一种改进型多路复用器实现:线性多路复用器
所谓的线性多路复用器,如图1所示,个人感觉就是多路复用器级联。使用这种结构可以组成大型多路复用器,前面我们知道4:1多路复用器消耗0.5N个LE(即2个),而且我们还知道前面最好的情况是消耗0.66N个LE,而图11所示的结构只需0.5N个LE,面积减少了25%。
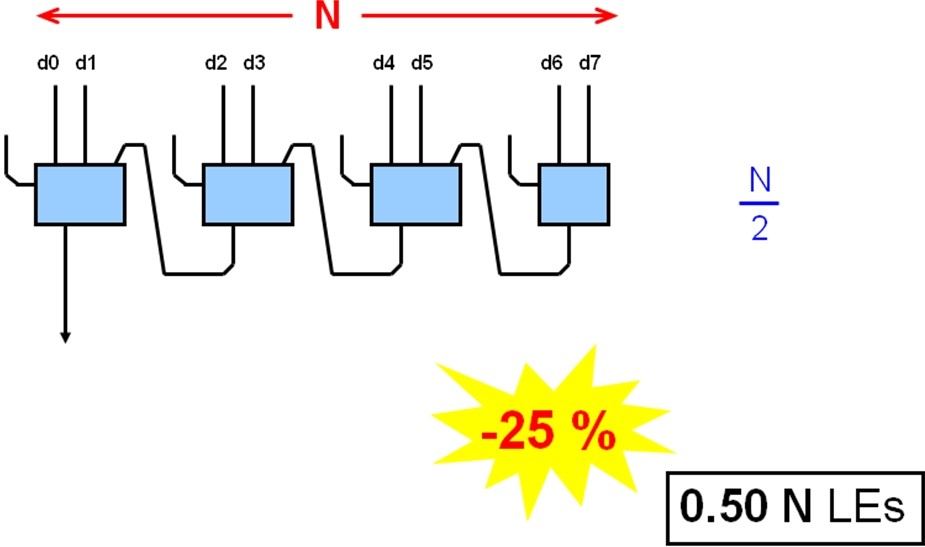
图1:线性多路复用器
那么它是如何工作的呢?如图2所示,每个LUT像我们前面介绍的4:1多路复用器那样被配置成两个MUX。选择线由原始选择输入信号产生,奇偶选择线用于选择每一对MUX中一个多路复用器作为输出,而选择MUX对的选择线只能有一个为高。
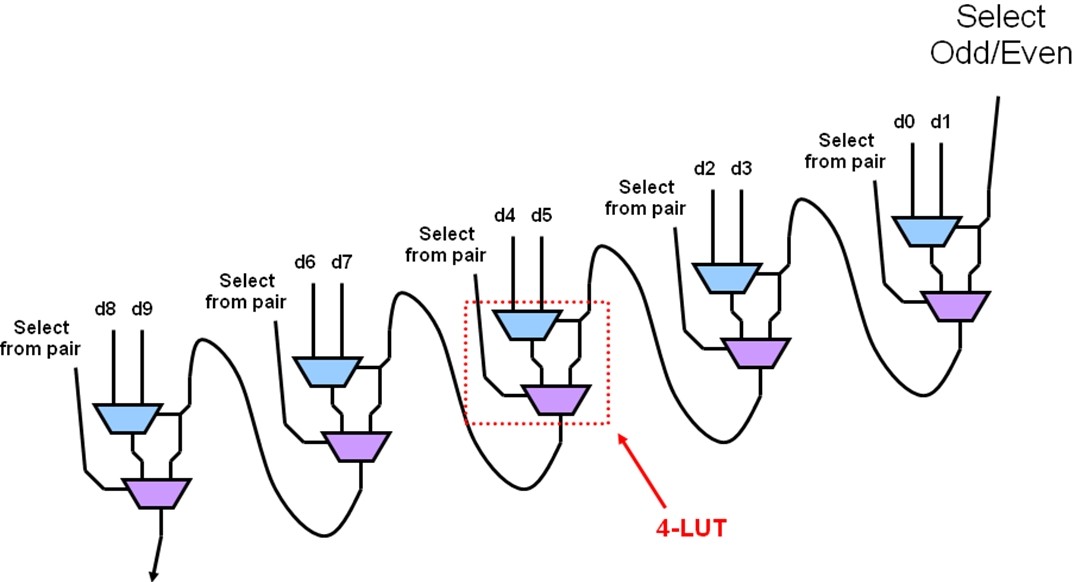
图2:线性多路复用器工作
根据以上分析,我们给出该多路复用器某次具体工作的示意图,如图3所示,此时输入d4被选择作为整个多路复用器的输出,因为只有它的选择线为“1”,而且同时它位于偶数位置。
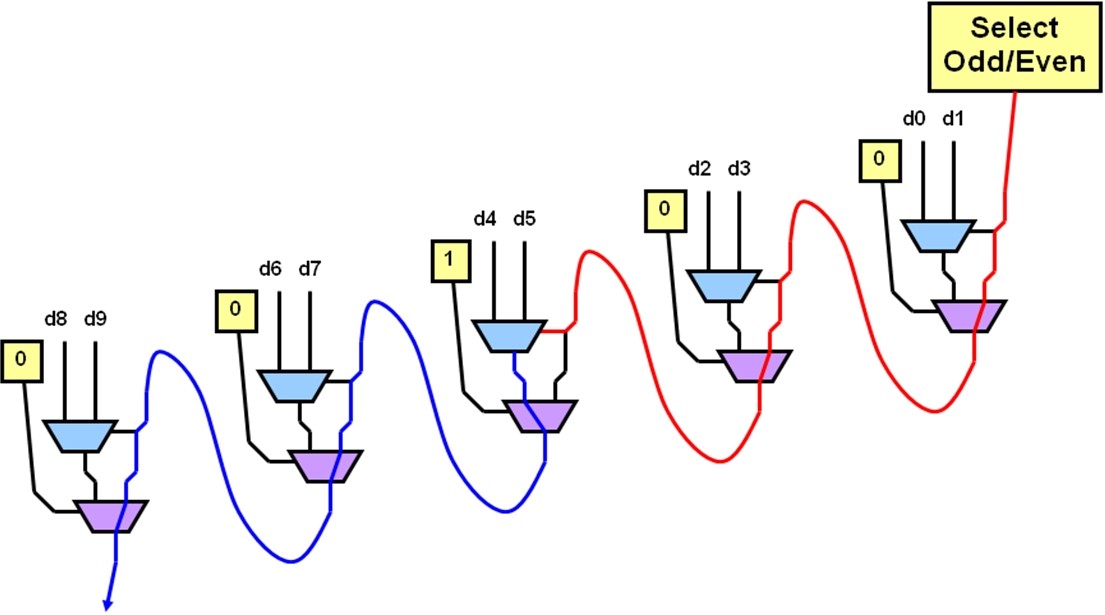
图3:线性多路复用器工作展示
此外,这种结构可以非常简单地实现对其置位和复位,如图4所示,这种结构的复位或置位并不需要额外特别的逻辑资源。选择线可以驱动总线上这些多路复用器,一根选择线即可使得所有这些多路复用器输出为0或1。
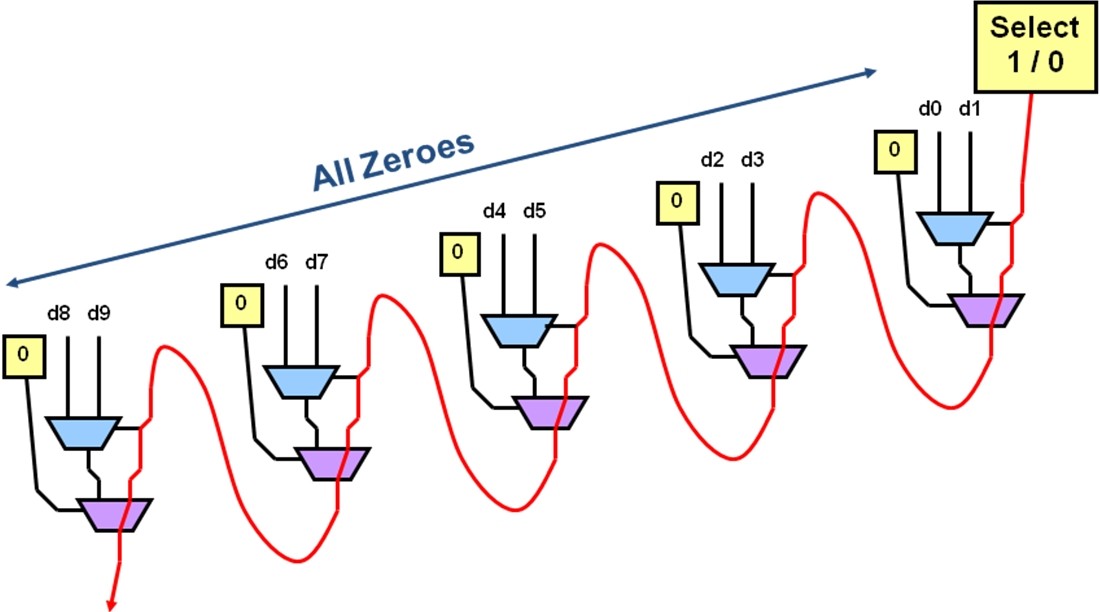
图4:异步置位复位的实现
那么我们来看这种结构的时序延时情况,如图15所示为该结构的局部示意。图5是一种最好情况,因为如图3所示,有时候复用器分解后从输入到输出可能需要不止两个4输入LUT。
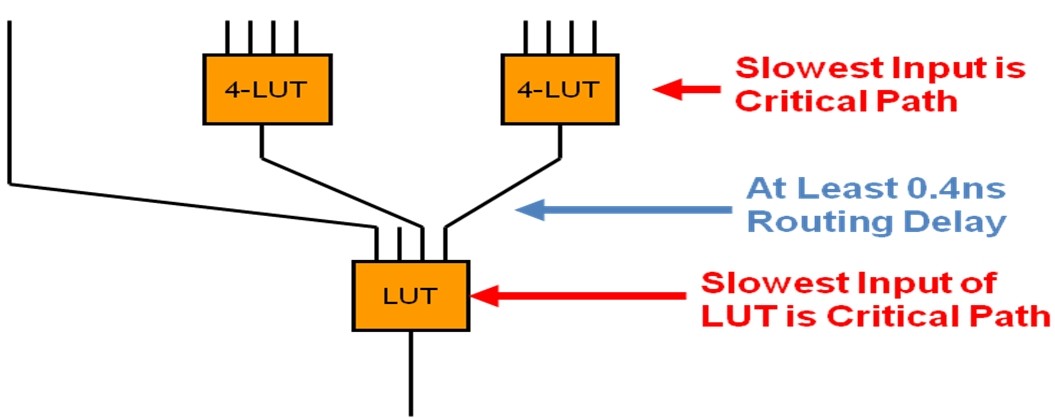
图5:无需优化树形LUT的延时
根据ALTRA的信息,四输入LUT四个输入端口中A输入最慢,D输入最快。而多路复用器必然会有一个输入是从A端口输入。那么具体这些端口之间的延时差异如何呢?我们以Stratix-6速度为例进行说明,该系列器件中LUT从D输入端口到COMB输出的延时是87ps,从A输入到COMB输出的延时450ps(B大约为300ps,C大约为200ps),所以比从D输入要慢了大概5倍。图5显示了关键路径布线延时至少达到了0.4ns。
前面我们也提到了,可以使用级联线来减少布线延时,从Cyclone和Stratix开始逻辑资源中分布有丰富的,速度特快的布线链,即级联链。可以让最慢的输入(关键路径)连接到级联输入,并让其驱动最快的LUT输入端口,即D输入端口,如图6所示。
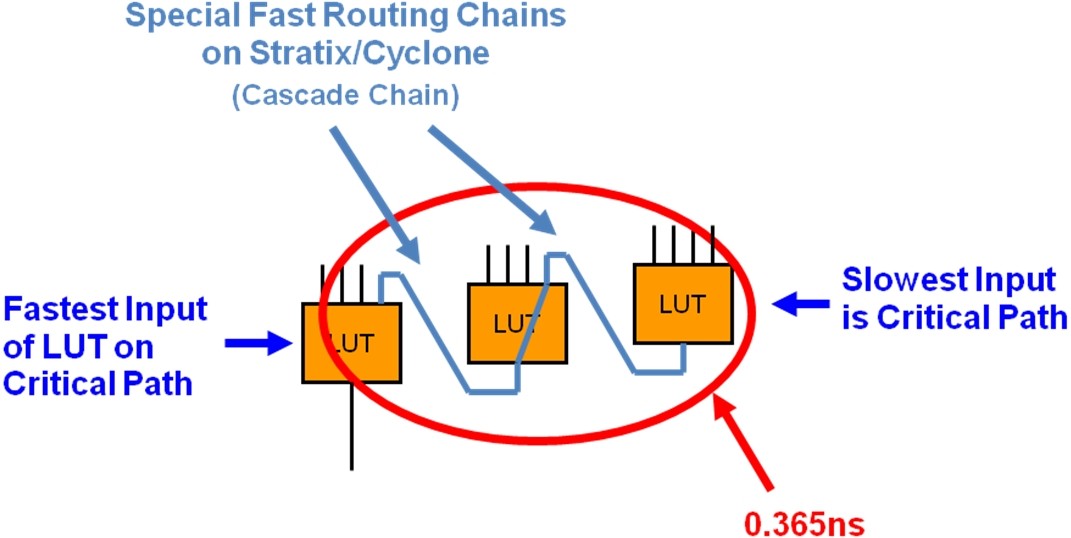
图6:级联逻辑速度更快


 /5
/5 







文章评论(0条评论)
登录后参与讨论