
4级流水线方式的32位全加器<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
之前一篇博文(流水线加法器设计(Verilog))介绍了2级流水线4位全加器,本来目的是和之前不运用流水线的加法器延时进行比较,不过结果程序写得不太好,也被codeman 大侠指出了错误的地方,于是尝试一下从新改写,于是有了这篇博文。
流水线设计是用于提高所设计系统运行速度的一种有效的方法。为了保障数据的快速传输,必须使系统运行在尽可能高的频率上,但如果某些复杂逻辑功能的完成需要较长的延时,就会使系统很难运行在高的频率上,在这种情况下,可使用流水线技术,即在长延时的逻辑功能快中插入触发器,使复杂的逻辑操作分步完成,减少每个部分的处理延时,从而使系统的运行频率得以提高。流水线设计的代价是增加了寄存器逻辑,即增加了芯片资源的耗用。
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
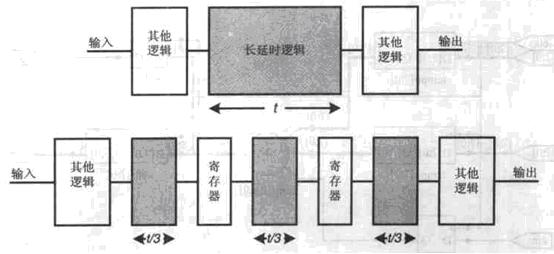
流水线操作概念示意图
流水线设计的概念:
所谓流水线设计实际上就是把规模较大、层次较多的组合逻辑电路分为几个级,在每一级插入寄存器组暂存中间数据。K级的流水线就是从组合逻辑的输入到输出恰好有K个寄存器组(分为K级,每一级都有一个寄存器组)上一级的输出是下一级的输入而又无反馈的电路。
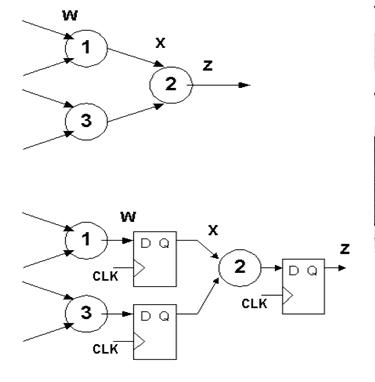
组合逻辑设计转化为流水线设计
上图表示如何将把组合逻辑设计转换为相同组合逻辑功能的流水线设计。
组合逻辑设计:
这个组合逻辑包括两级。
第一级的延迟是T1和T3两个延迟中的最大值;
第二级的延迟等于T2的延迟。
为了通过这个组合逻辑得到稳定的计算结果输出,需要等待的传播延迟为:
[max(T1,T3)+T2]
流水线:
在从输入到输出的每一级插入寄存器后,流水线设计的第一级寄存器所具有的总的延迟为T1与T3时延中的最大值加上寄存器的Tco(触发时间)。同样,第二级寄存器延迟为T2的时延加上Tco。采用流水线设计为取得稳定的输出总体计算周期为:
max(max(T1,T3)+Tco,(T2+Tco))
流水线设计需要两个时钟周期来获取第一个计算结果,而只需要一个时钟周期来获取随后的计算结果。开始时用来获取第一个计算结果的两个时钟周期被称为采用流水线设计的首次延迟(latency)。
但对于CPLD来说,器件的延迟如T1、T2和T3相对于触发器的Tco要长得多,并且寄存器的建立时间Tsu也要比器件的延迟快得多。因此流水线设计获得比同功能的组合逻辑设计更高的性能。
采用流水线设计的优势在于它能提高吞吐量(throughput)。
首次延迟(latency)——(从输入到输出)最长的路径进行初始化所需要的时间总量;
吞吐延迟——执行一次重复性操作所需要的时间总量。
假设T1、T2和T3具有同样的传递延迟Tpd。
组合逻辑设计:
首次延迟为2*Tpd
吞吐延迟为2*Tpd
流水线设计:
首次延迟为2*(Tpd+Tco)
吞吐延迟为Tpd+Tco
如果CPLD硬件能提供快速的Tco,则流水线设计相对于同样功能的组合逻辑设计能提供更大的吞吐量。
如Xilinx的XC9572-7的Tpd为7.5ns,Tco为4.5ns。

`timescale 1ns / 1ps
module pipeline_add(a,b,cin,cout,sum,clk);
input[31:0] a,b;
input clk,cin;
output[31:0]sum;
output cout;
reg[31:0] sum;
reg[31:0] tempa,tempb;
reg tempci;
reg cout;
reg firstco;
reg[7:0] firstsum;
reg[23:0] firsta,firstb;
reg secondco;
reg[15:0] secondsum;
reg[15:0] seconda,secondb;
reg thirdco;
reg[23:0] thirdsum;
reg[7:0] thirda,thirdb;
always@(posedge clk) /输入数据缓存
begin
tempa<=a;
tempb<=b;
tempci<=cin;
end
always@(posedge clk)
begin
{firstco,firstsum}<=9'b0+tempa[7:0]+tempb[7:0]+tempci;
//第一级加(低8位)
firsta<=tempa[31:8]; //未参加计算的数据缓存
firstb<=tempb[31:8];
end
always@(posedge clk)
begin
{secondco,secondsum}<={9'b0+firsta[7:0]+firstb[7:0]+firstco,firstsum};
//第二级数据加([15:8]位相加)
seconda<=firsta[23:8]; //数据缓存
secondb<=firstb[23:8];
end
always@(posedge clk)
begin
{thirdco,thirdsum}<={9'b0+seconda[7:0]+secondb[7:0]+secondco,secondsum};
//第三级数据加([23:15]位相加)
thirda<=seconda[15:8]; //数据缓存
thirdb<=secondb[15:8];
end
always@(posedge clk)
begin
{cout,sum}<={9'b0+thirda[7:0]+thirdb[7:0]+thirdco,thirdsum};
//第四级数据加([31:24]位相加)
end
endmodule
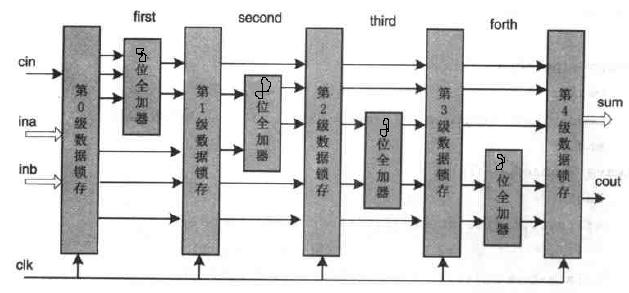
上图是上述4级流水线加法器的框图,从该图可以看出,上面的加法器采用5级缓存、4级加法,每一个加法器实现8位数据和一个进位的相加,整个加法器只受8位全加器的工作速度的限制。
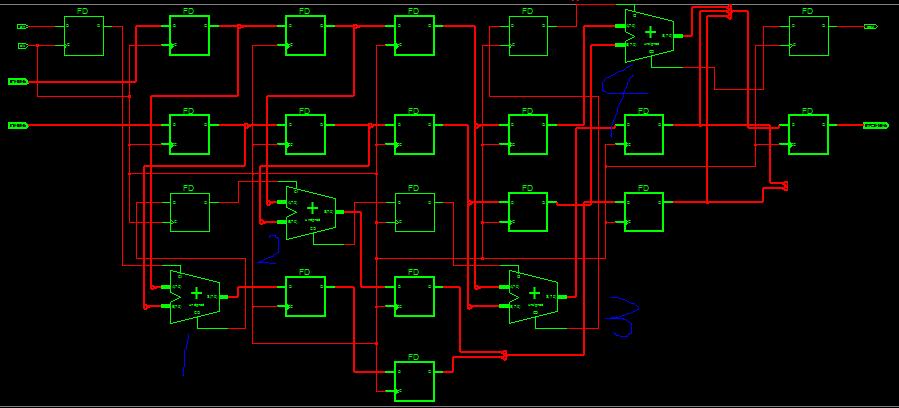
例化后可以看到4个8位全加器和缓存。
顶层测试程序:
`timescale 1ns/1ps
module test;
reg [31:0] a = 32'b00000000000000000000000000000000;
reg [31:0] b = 32'b00000000000000000000000000000000;
reg cin = 1'b0;
wire cout;
wire [31:0] sum;
reg clk = 1'b0;
parameter PERIOD = 200;
parameter real DUTY_CYCLE = 0.5;
parameter OFFSET = 100;
initial // Clock process for clk
begin
#OFFSET;
forever
begin
clk = 1'b0;
#(PERIOD-(PERIOD*DUTY_CYCLE)) clk = 1'b1;
#(PERIOD*DUTY_CYCLE);
end
end
pipeline_add UUT (
.a(a),
.b(b),
.cin(cin),
.cout(cout),
.sum(sum),
.clk(clk));
initial begin
// ------------- Current Time: 1585ns
#1585;
cin = 1'b1;
a = 32'b00000000000000000000010011010010;
// -------------------------------------
// ------------- Current Time: 2185ns
#600;
b = 32'b00000000000000000000001000110111;
// -------------------------------------
// ------------- Current Time: 3385ns
#1200;
b = 32'b00000000000000000000000011010100;
// -------------------------------------
// ------------- Current Time: 3985ns
#600;
a = 32'b00000000000000000000000101000100;
// -------------------------------------
// ------------- Current Time: 6185ns
#2200;
a = 32'b00000000000000000000000011011111;
// -------------------------------------
// ------------- Current Time: 8385ns
#2200;
cin = 1'b0;
b = 32'b00000000000000000000000101001110;
// -------------------------------------
// ------------- Current Time: 13185ns
#4800;
cin = 1'b1;
// -------------------------------------
// ------------- Current Time: 14585ns
#1400;
b = 32'b01000000000000000000000000000000;
// -------------------------------------
// ------------- Current Time: 16385ns
#1800;
cin = 1'b0;
// -------------------------------------
// ------------- Current Time: 16585ns
#200;
a = 32'b01110101101001001110100100000000;
// -------------------------------------
// ------------- Current Time: 17785ns
#1200;
b = 32'b10000000000000000000000000000000;
// -------------------------------------
// ------------- Current Time: 17985ns
#200;
a = 32'b10010101101000010001000100010001;
// -------------------------------------
end
endmodule
布线布局后仿真(选择XC3S500E)

4个时钟周期后获得计算结果。

延时大概为5ns。

注意:
要注意在加法的过程中的位宽问题
{cout,sum}<={9'b0+thirda[7:0]+thirdb[7:0]+thirdco,thirdsum};
等式左边33位:cout (1bit )+sum(32bit)
等式右边32位:thirda/thirdb(8bit)+thirdsum(24bit)
如果没有加上<?xml:namespace prefix = st1 ns = "urn:schemas-microsoft-com:office:smarttags" />9’b0的话,cout会被综合掉,一直接地。
参考资料:
1) Verilog数字系统设计教程,夏宇闻,北京航空航天大学出版社,P105页 ,2.6流水线
2) Verilog HDL程序设计教程,P151页,10.2流水线设计技术 (程序不能综合,具体参考上文)
下载地址:http://bbs.ednchina.com/ShowTopic.aspx?id=73098




 /4
/4 






文章评论(0条评论)
登录后参与讨论