
玩单片机,做人机交互,少不了需要字库,咱中国人呢,更是少不了汉字字库。在嵌入式环境中,由于屏幕尺寸一般都比较小,使用最常见的16点阵汉字库,做界面的美观性是比较差的——经常菜单做出来顶天立地的,虽然不影响使用,但是用户体验着实不好。
我一般使用的是12点阵汉字库,在两行英文的16像素高度下,12点阵汉字库不但没有顶天立地,留下了美化的空间,而且文字看起来很秀气,做出来的产品显得高雅大方(仅限于黑白对比黑白啊,哈哈)
手头的12点阵汉字库,是十几年前UCDOS年代珍藏的,现在在网络上也能搜到大把,质量上说,是相当不错,套用一句广告词:我们一直都用它! 不过最近做开源遥控器代码时,遇到海峡对岸的朋友需要繁体软件的时候,卡壳了。。。在网络上找了许久,没有找到美观好用的12点阵繁体字库,UCDOS年代的繁体也是16点阵的了。。。
最终,决定自己动手,把12点阵繁体字库,从WINDOWS7里面偷出来。。。盖茨他老人家热衷慈善事业,对我等非盈利应用,应该不会有意见吧。。。
源码见附件,其中的release目录中已经有生成好的12点阵简繁体字库可用了。字库的检索方式,是传统的区位码方式:每个汉字占24个字节(16*12点阵),按照((区码-0XA1)*94+位码-0XA1)*24来定位汉字的点阵阵列。 之所以是16嘛。。。。自己动脑筋想想,字库的扫描顺序?我也卖个关子不说,随便挑一个汉字画出来就能解析明白,呵呵。
整个偷字库的思路是比较简单的,首先设置好12点阵的字体,然后将文字绘制到窗体上,接着按照一定的取模规律从窗体上逐像素取得点阵数据,最后写入文件。完成全部汉字的枚举就更简单了,用一个双重循环,分别穷举区码和位码,就可以做到6000多个二级汉字的遍历了。
由于我们一般都是用简体字内码来进行开发的,所以做繁体字库的时候,生成的字库需要按照简体字库的顺序进行排列,因此,要将简体字转换成UNICODE再转换成BIG5内码,才能绘制出简体字库顺序的繁体字。。。有点拗口,大家静下心分析可以想明白,其实不复杂。
行窃的过程中,发现按照UNICODE转换法,会有1%左右的汉字无法转成对应的繁体字(显示为?),因此代码要稍加修饰,对此类汉字,沿用简体字库,聊胜于无~
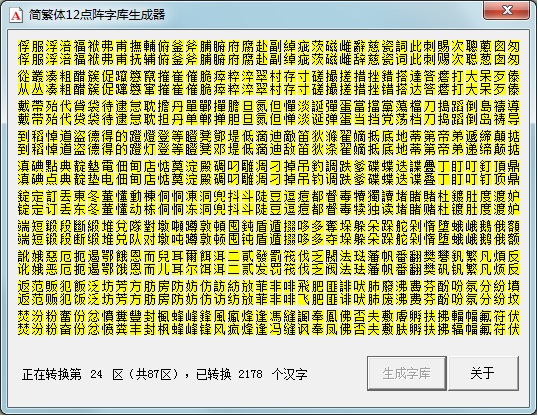
这是软件的工作界面,我按照上下简繁同步显示的方式来处理,同时生成简繁体汉字库,为了偷懒我没创建线程,工作时界面卡死,不必担心,详情请看源码了,使用VC++ 6.0编译,不过我是用的是最朴素的消息循环方式编程,所以可执行文件极小(不需要额外运行库哦)。
最终我将字库用在了GALEE开源遥控器当中,效果不错,对于看惯了简体字的我们来说,看看繁体字觉得别有韵味,哈哈



用户3989891 2022-2-18 15:10
用户1264390 2015-11-14 13:44
用户752156 2015-5-19 00:43
用户1835234 2015-4-17 11:21
用户1588142 2015-1-6 20:58
用户1761730 2014-5-25 19:47
用户1761325 2014-5-23 16:58