
在Tcl中,用binary format 和binary scan来处理二进制文件用得比较多,但这个两个命令比较难理解。我花了一天的时间,终于略知一二。现和大家分享下。
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
一:binary命令的解释
binary format
binary scan
帮助给出的解释:
This command provides facilities for manipulating binary data. The first form, binary format, creates a binary string from normal Tcl values. For example, given the values 16 and 22, on a 32-bit architecture, it might produce an 8-byte binary string consisting of two 4-byte integers, one for each of the numbers. The second form of the command, binary scan, does the opposite: it extracts data from a binary string and returns it as ordinary Tcl string values.
大意是:
该命令是对二进制数据进行操作。binary format命令,是把普通的Tcl 数据转换成二进制字符,例如:在32位的机器上,可以把16和22这样的数据,转换成由两个4字节的整数组成的8字节的二进制字符串(一个二进制字符的显示图形,是由字符编码方式决定的,在记事本里有ANSI、Unicode、Unicode big endian和UTF-8编码方式,关于字符编码可看:字符编码笔记:ASCII,Unicode和UTF-8)。binary scan命令,功能正好与binary format命令相反,是把二进制字符转换成正常的Tcl 数据。
二:binary命令的语法
1.binary format formatString ?arg arg ...?
The binary format command generates a binary string whose layout is specified by the formatString and whose contents come from the additional arguments. The resulting binary value is returned
binary format命令接收数据(arg arg ...?)并根据模板(formatString)进行压缩转换,最后返回转换的值。
处理不同的数据用不同的模板,比如待处理的数据是二进制数(例:1001010)可用b或B,待处理的数据是十六进制数(例:FF)可用h或H;并根据待处理数据的长度,设置count,比如待处理二进制数1001010长为8,则count=8,(在其它模板中,count还可表示重复特征等)。
2.binary scan string formatString ?varName varName ...?
The binary scan command parses fields from a binary string, returning the number of conversions performed. String gives the input bytes to be parsed (one byte per character, and characters not representable as a byte have their high bits chopped) and formatString indicates how to parse it. Each varName gives the name of a variable; when a field is scanned from string the result is assigned to the corresponding variable.
Binary scan 命令根据模块(formatString)从一二进制字符里解析获得一数值,并把该数值赋给变量(arg arg ...?),该命令返回解析的字符的个数。
待解析的字符可能是由几个字节组成,到底由几个字节组成一个字符,由通道的属性来决定,比如fconfigure channel -encoding binary ,则是一个字节构成一个字符,可以认为高8位的字节被砍掉了。
三:二进制编码模式的设置
fconfigure stdout –translation binary –encoding binary
在文件中处理二进制数据时,要先关闭换行转换和字符设置编码方式:fconfigure stdout –translation binary –encoding binary,关闭换行转换还可在puts 命令后面加上变元-nonewline。设置了二进制编码后,在进行二进制输出(puts)时,Tcl就会把每个Unicode字符的高8位舍去,保留低8位写入二进制文件中;在进行读(gets或read)二进制文件时,Tcl就会读取每个8位字节并将其储于一个16位Unicode字符的低半部分中,同时将高半部分设置为0。
例1:
set fileID [open test.hex w+];
fconfigure $fileID -translation binary -encoding binary;
puts –nonewline $fileID "\u<?xml:namespace prefix = st1 ns = "urn:schemas-microsoft-com:office:smarttags" />30ac";
close $fileID
在tclsh运行上面代码后,用UltraEdit打开test.hex,可看到<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />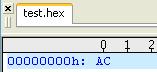 ,已把高8位字节30给舍去了。
,已把高8位字节30给舍去了。
例2:把I/O通道的字符集编码设置成unicode,即下面的代码,再运行一次。
set fileID [open test.hex w+];
fconfigure $fileID -translation binary -encoding unicode;
puts –nonewline $fileID "\u30ac";
close $fileID
可看到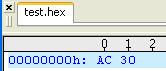 ,高8位的字节30还保存在。
,高8位的字节30还保存在。
注意:puts stdout 与puts $fileID时的区别
在Tclsh编译环境中,一般系统默认编码为cp936(用encoding system查询),跟unicode编码方式差不多吧?错,不完全相同。当然stdout的默认编码也为cp936,用puts “\u00ca”,能正确输出为 ;而当把这个字符写入到fileID文件时,用 puts –nonewline $fileID “\u00ca”,然后用记事本打开看到的是一个“?”字符,显然是记事本的无法用正常的编码方式打开,用UltraEdit可看到其实写入3F,而\u003F正好就是“?”字符的编码。这是因为pust $fileID的编码方式用的默认的cp936,而一般的文档的编码用的是unicode,不支持cp936(这也是为什么Tclsh环境中能正确显示,而文档不行),当用cp936编码的字符存入到unicode编码的文档中,就丢失信息了,不能正确显示。
;而当把这个字符写入到fileID文件时,用 puts –nonewline $fileID “\u00ca”,然后用记事本打开看到的是一个“?”字符,显然是记事本的无法用正常的编码方式打开,用UltraEdit可看到其实写入3F,而\u003F正好就是“?”字符的编码。这是因为pust $fileID的编码方式用的默认的cp936,而一般的文档的编码用的是unicode,不支持cp936(这也是为什么Tclsh环境中能正确显示,而文档不行),当用cp936编码的字符存入到unicode编码的文档中,就丢失信息了,不能正确显示。
所以在把数据写入文件I/O中,一定要先设置I/O通道的编码方式。用fconfigure $fileID –encoding binary(或unicode或utf-8),来设置输出到文件的模式,当然从文件I/O中读出数据也要同样设置I/O通道的编码模式,否则也会丢失信息。
五:其它:
1.关于待要写入文件的数据的格式。
在用Tcl处理中会产生一些数据,我们想把它保存起来,这些数据不外乎二进制数据和十六进制数据,其它这两种格式的数据是可以转换,例如:11001010B=CAH ,binary scan [binary format “B8” 11001010] “H2” tmp,转换后的tmp值为CA。不转换也可以,用binary format "B8" 11001010和 binary format “H2” CA产生的效果是一样的。
为什么要转换后,存入文件,因为小。
2.关于big-endian 和little-endian



用户292689 2010-7-19 11:26
用户143696 2009-3-31 16:14
ash_riple_768180695 2009-2-24 13:11