
PIPELINING, RETIMING, REGISTER BALANCING是同一项技术的不同说法。可以手工操作,也可以交给EDA工具自动执行。 riple
在复杂的组合逻辑路径当中添加一级寄存器,通过增加一级流水线级别来割断关键路径,这是解决时序收敛问题和提高电路时序性能最常用的方法。在hustzq博友的LPM函数的LPM_PIPELINE参数研究一文中,针对这一问题有详尽的论述。在fpgasdr博友的cordic verilog 程序及仿真结果 8级流水线和cqcrr博友的pipiline加法器两篇文章中,还给出了具体的代码。这一方法是在RTL级别进行流水线负载均衡操作,是通过修改HDL代码半自动或完全手工实现的。 riple
在Quartus II的Synthesis Netlist Optimizations设置选项中,可以使能Perform gate-level register retiming;在Quartus II的Physical Synthesis Optimizations设置选项中,还可以使能Perform register duplication和Perform register retiming来进一步优化关键路径上组合逻辑路径的长度。这一方法是在gate级别进行流水线负载均衡操作,是通过Fitter的时序驱动布局算法自动实现的。 riple
在上述的两种方法中,手工设计多级流水线是应该优先考虑的。但是在实际操作中,往往有这样几种情况,导致手工优化变得很难操作。 riple
1. 没有从电路性能角度出发进行逻辑设计,导致忽略进行组合逻辑路径分割。
2. 包含有优先级的组合逻辑,很难进行逻辑路径的分割。
3. 包含复杂算法的组合逻辑,逻辑路径分割后,不能做到流水线各级负载均衡。
4. 代码设计者并不了解器件底层结构,或者出于代码可移植性的考虑,不能顾及底层结构,而不能手工进行有效的逻辑路径分割。
在这样的情况下,就需要依靠Fitter的自动化寄存器复制和调整功能,来实现流水线各级的负载均衡。 riple
所以,在实际操作中,需要结合手工插入寄存器与自动化的寄存器调整功能:手工添加充足的寄存器供Fitter进行流水线负载均衡。寄存器并不一定需要精确插入到组合逻辑路径的内部,只需要在组合逻辑路径的两端添加冗余寄存器,然后交给Fitter根据器件的底层结构进行精确的计算和权衡。一级冗余寄存器不够,就再增加一级。 riple
在最近的一次分析和解决时序收敛问题的过程中,我就遇到了一个有趣的问题。原有设计中手工添加了一个寄存器用以分隔DPRAM与后级模块内部的加法器。没有经过Fitter优化前,该组合逻辑路径过长;经过Fitter优化后,关键路径仍然存在于该寄存器附近。经过分析,由于该组合逻辑比较复杂,仅一级寄存器并不能提供给Fitter足够的资源进行有效的路径分割,通过手工添加了多一级的寄存器,该问题得到解决。 riple
下面,就结合Post-Mapping Technology Map Viewer(布局前)和Post-Fitting Technology Map Viewer(布局后)对该问题及其解决过程进行图解:
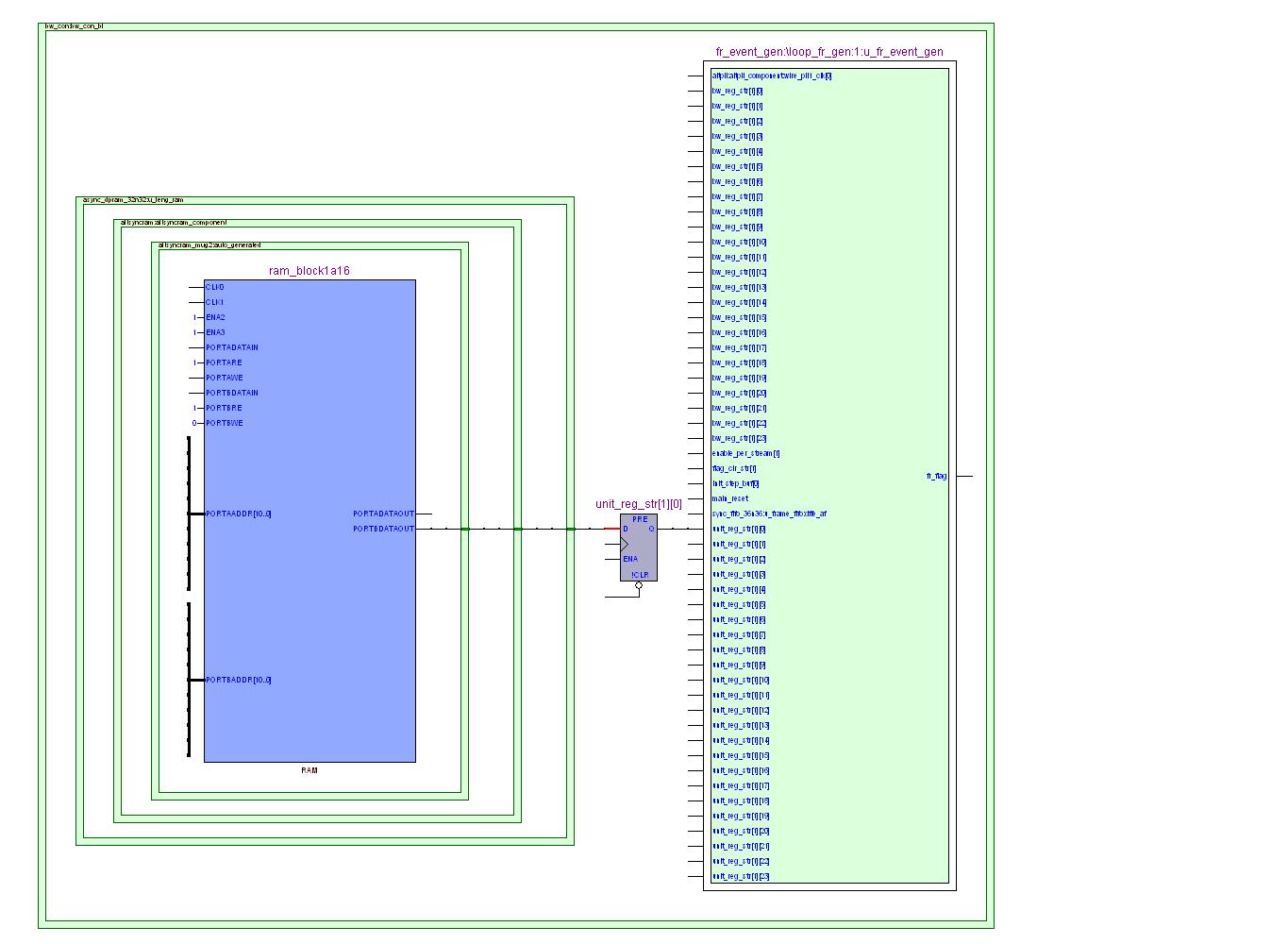
图1 外部视图
布局前, 两个模块之间由一级寄存器unit_reg_str[1][0]分隔。
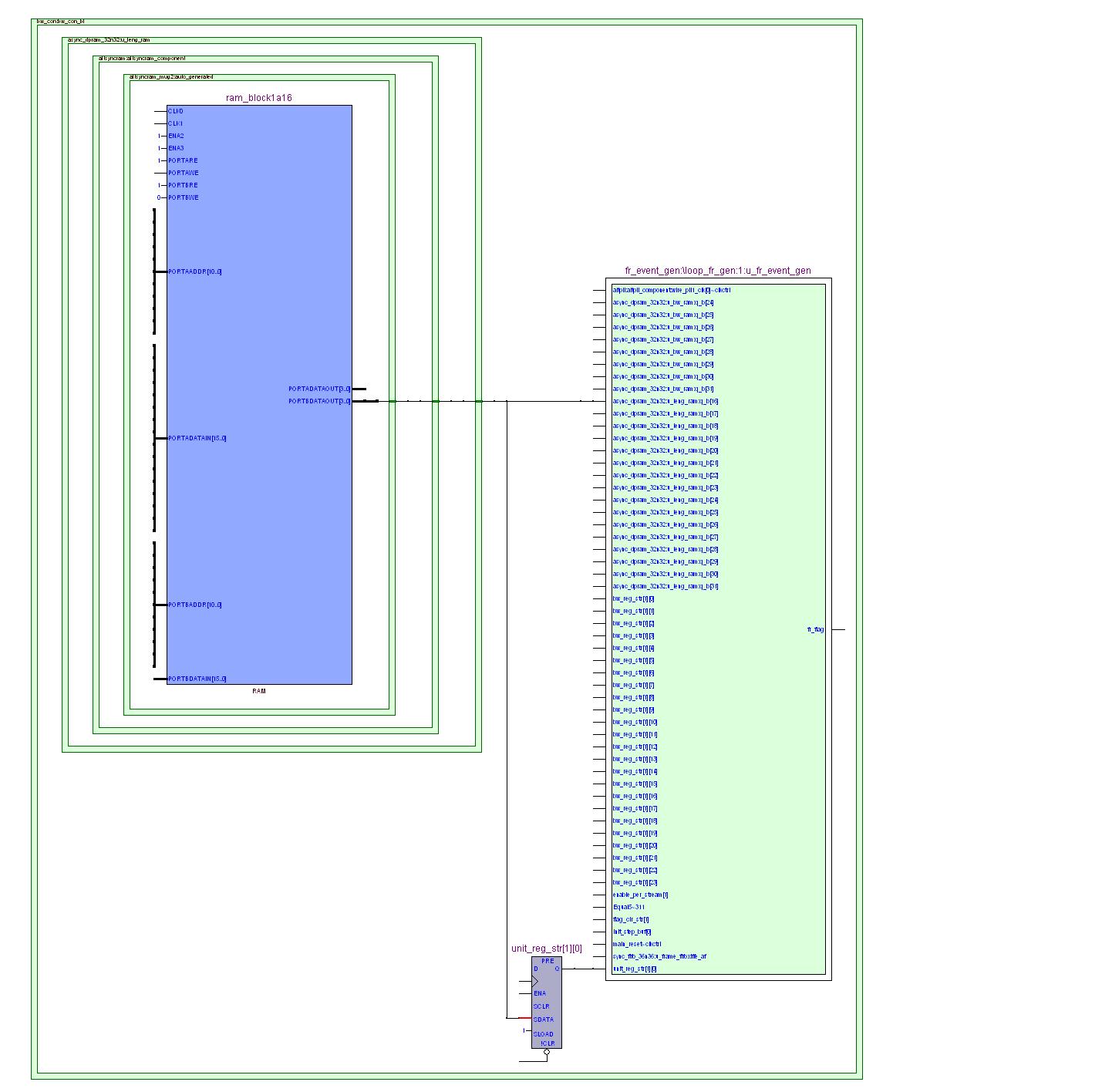
图2 外部视图
布局后,寄存器unit_reg_str[1][0]被复制并移动到该模块内部,ram_block1a16直接驱动该模块端口。

图3 内部视图
布局前,被驱动模块内部的两条组合逻辑路径:
1. 从寄存器unit_reg_str[1][0]到寄存器unit_cycle_carryout(加法器逻辑);
2. 从寄存器unit_reg_str[1][0]到寄存器unit_cycle_carryout(比较器逻辑)。
两条路径分享共同的起点和终点。

图4 内部视图
布局后,被驱动模块内部的三条组合逻辑路径:
1. 从ram_block1a16的read_en输入寄存器到寄存器Add1~477_NEW_REG1210(加法器逻辑);
2. 从寄存器Add1~477_NEW_REG1210到寄存器unit_cycle_carryout_NEW_REG1116(简单组合逻辑);
3. 从寄存器unit_reg_str[1][0]到寄存器unit_cycle_carryout_NEW_REG1120(比较器逻辑)。
寄存器unit_reg_str[1][0]被复制为Add1~477_NEW_REG1210并移动到加法器之后。
寄存器unit_cycle_carryout被复制为unit_cycle_carryout_NEW_REG1116和unit_cycle_carryout_NEW_REG1120。
由于加法器被移动到了等价于寄存器unit_reg_str[1][0]的寄存器Add1~477_NEW_REG1210之前,ram_block1a16与adder的组合逻辑成为最长的组合逻辑路径,该路径造成时序违规。ram_block1a16可以被认为是一个复杂的组合逻辑,该逻辑引入延时1.728ns。adder逻辑虽然有近20级,但是引入的延时只有3.2ns。
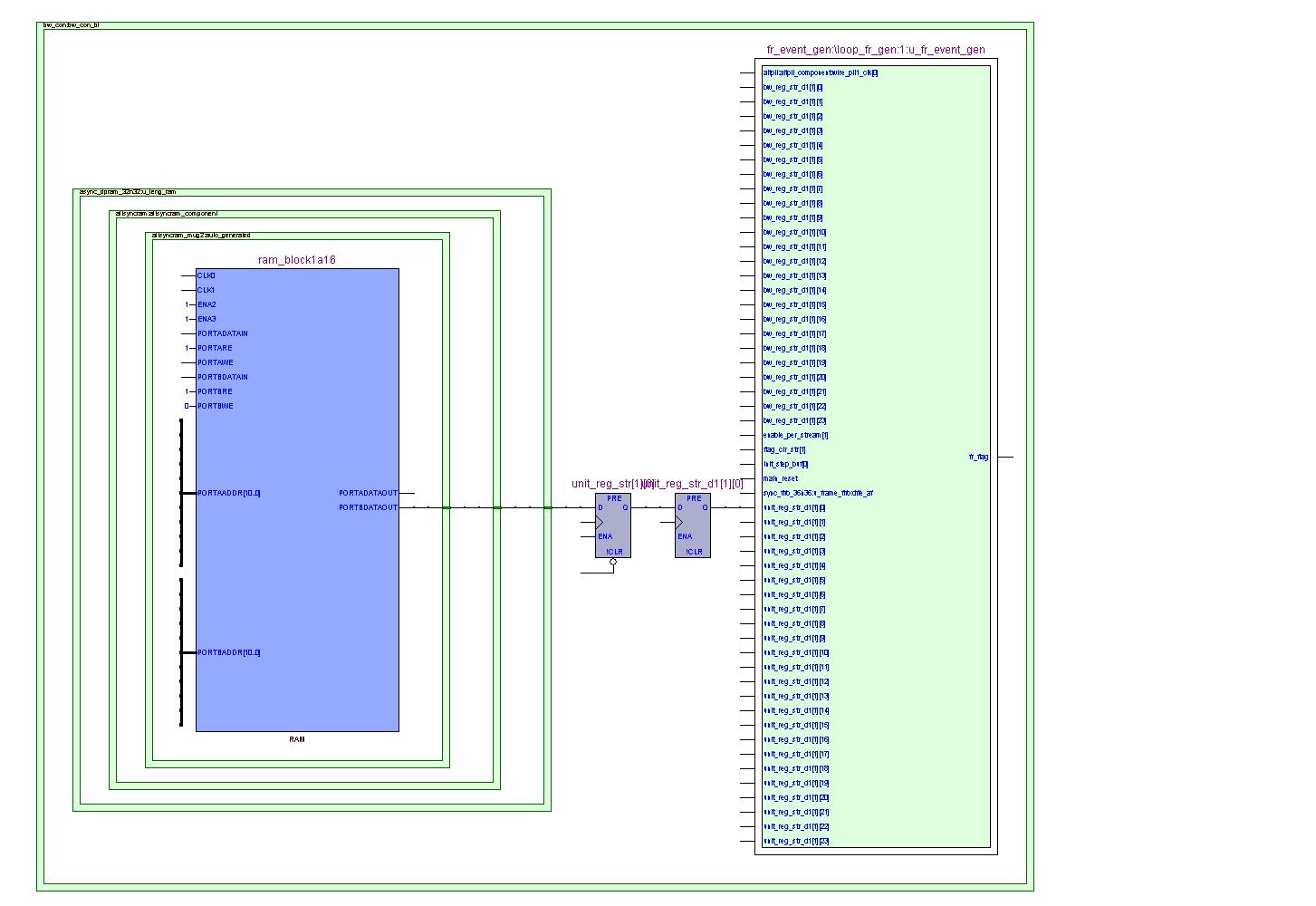
图5 外部视图
布局前,添加一级寄存器unit_reg_str_d1[1][0],增加一级流水线级别。
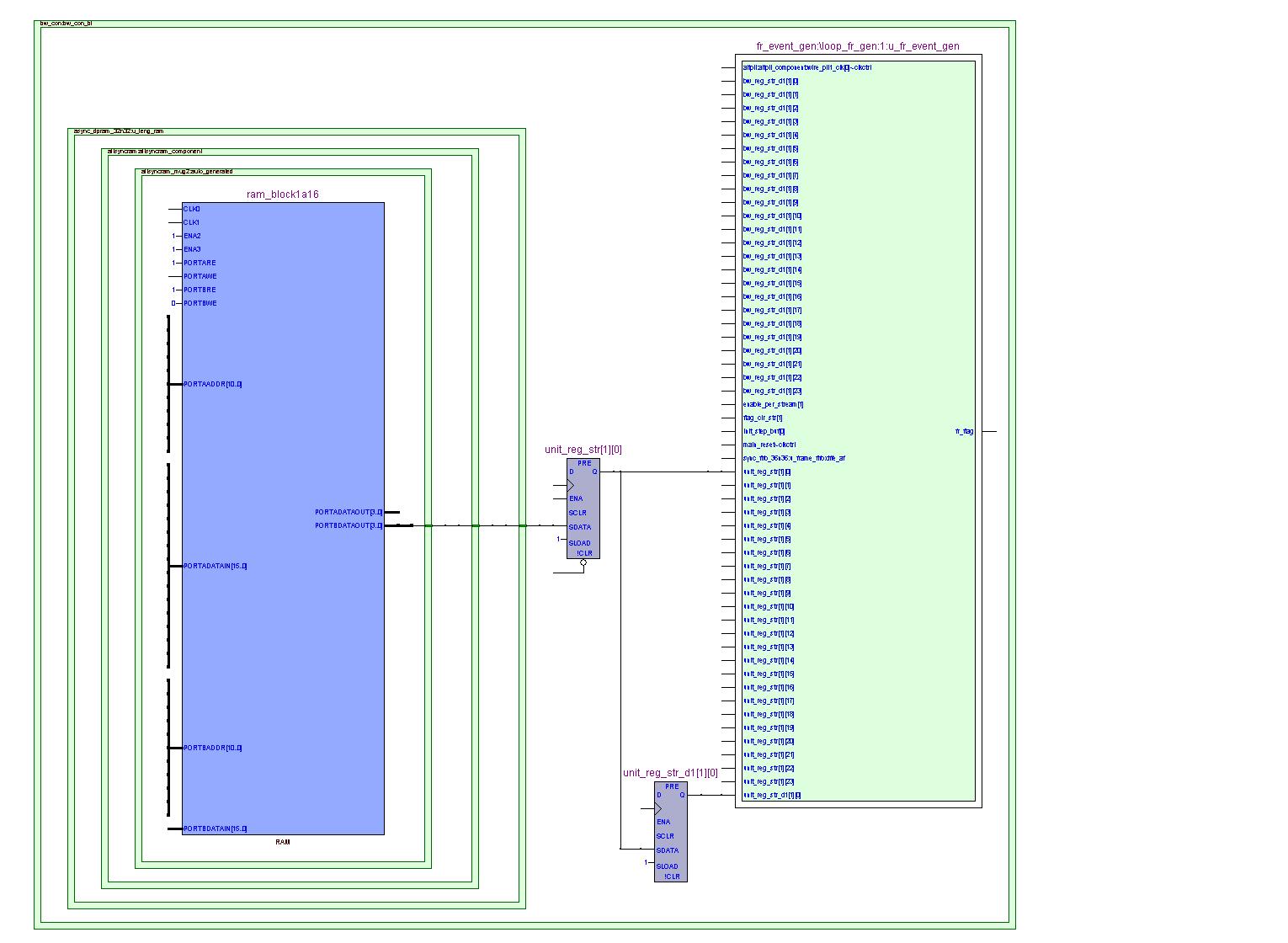
图6 外部视图
布局后,新添加的寄存器unit_reg_str_d1[1][0]被复制和移动到后级模块内部。

图7 内部视图
布局前,所有的组合逻辑路径被限制在寄存器unit_reg_str_d1[1][0]与寄存器unit_cycle_carryout之间。

图8 内部视图
布局后,被驱动模块内部的三条组合逻辑路径:
1. 从寄存器unit_reg_str[1][0]到寄存器Add1~477_NEW_REG860(加法器逻辑);
2. 从寄存器Add1~477_NEW_REG860到寄存器unit_cycle_carryout_NEW_REG2466(简单组合逻辑);
3. 从寄存器unit_reg_str_d1[1][0]到寄存器unit_cycle_carryout_NEW_REG2464(比较器逻辑)。
寄存器unit_reg_str_d1[1][0]被复制为Add1~477_NEW_REG860
寄存器unit_cycle_carryout被复制为unit_cycle_carryout_NEW_REG2466和unit_cycle_carryout_NEW_REG2464
虽然加法器移动到了unit_reg_str_d1[1][0]之前,但是仍然在unit_reg_str[1][0]寄存器之后,ram_block1a16与adder不再构成组合逻辑路径,最长的组合逻辑路径被成功割断。
从上面的图中可以看到,该组合逻辑的复杂之处在于:
1. ram_block1a16的组合逻辑不能被进一步分割;
2. Adder的组合逻辑虽然可以分割,但是由于同一个MLAB内部存在速度极快的进位链,多级加法器之间不用寄存器分割反而能够获得更快的电路。
由于上面的两个原因,在添加寄存器之前,Fitter没有尝试把Adder分割成两个更短的Adder,而是尝试把ram_block1a16和Adder组合到一起。 riple
这一现象说明,在手工分割复杂组合逻辑时,需要考虑FPGA器件的底层结构。一味地分割类似于Adder这样已经优化的电路并不一定能得到最优的电路实现。 riple
用户1303485 2010-6-24 22:52
用户134835 2009-2-25 16:52
用户1395232 2009-2-21 15:03
ilove314_323192455 2009-2-4 17:44
ash_riple_768180695 2009-2-4 09:24
ash_riple_768180695 2009-2-4 09:10
ilove314_323192455 2009-2-3 18:41
ash_riple_768180695 2009-2-2 22:39
ilove314_323192455 2009-2-2 21:12