
第三章 操作(operation)
本章将具体描述OR1200核的运算。对于运算,它隶属于架构定义,详情可参考OR1000系统架构手册。
复位(Reset)
OR1200采用异步复位,可以在更高层次进行软件或硬件复位。

图4给出了OR1200核上电后的异步复位时序。复位信号连接于RISC核中的所有FF上。必须指出的是相比于RISC时钟,必须保证触发器(FF)的建立和保持时间。
如果系统实现了门控时钟,那么门控时钟可以用于确保合适的复位时序。

CPU/DSP
CPU/DSP仅仅实现了OR1000架构的32位部分,只含OR1000架构的部分特点。
指令(Instructions)
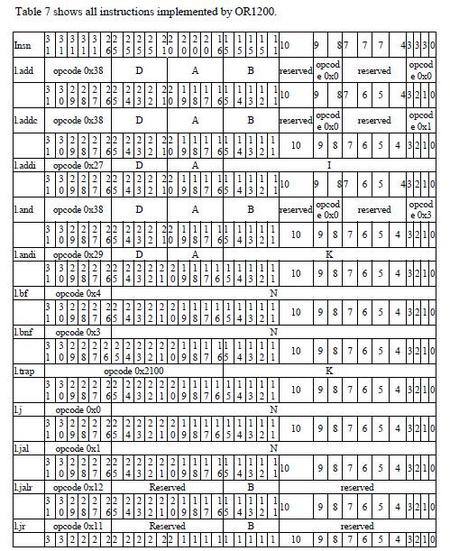
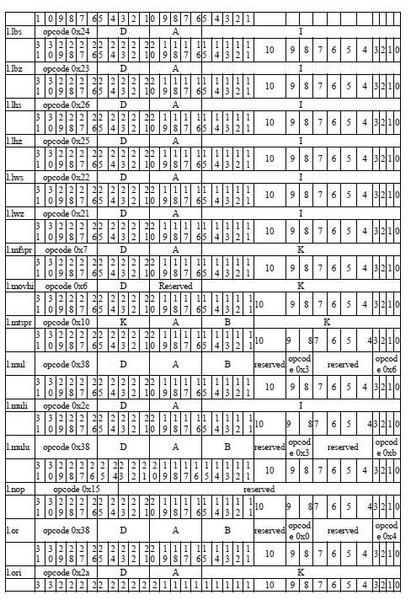

完整的指令操作描述请参考OR1000系统架构手册。
指令单元(Instruction unit)
指令单元产生指令有效地址从指令缓存中取指令,每个周期可以取一条指令。取指令的EA(effective address)被IMMU翻译成物理地址。
通用目的寄存器(general purpose register)
通用目的寄存器文件支持每个周期2个读操作及存储一个结果到目的寄存器。GPRs通过开发接口也可以进行读和写操作。
存取单元(load/store unit)
假定load指令在data cache中被hit,那么LSU可以每两个周期执行一个load指令。假定store指令在data cache中被hit,那么每一个周期可以执行一条store指令。
LSU计算load/store有效地址(EA),EA被DMMU翻译成物理地址。
通过开发接口也可以访问load/store EA、load data及store data。
整数执行流水线(integer execution pipeline)
核实现了下面的各种32位的整数指令:
算术指令
比较指令
逻辑指令
翻转和移位指令

表8列出了每种指令采用整数执行流水线时所需要的时间。大部分的指令可以在一个周期内完成。
MAC unit
MAC单元执行1.mac 指令,MAC单元实现了32*32全流水线乘法器和48-bit的累加器,MAC单元可以每个周期获取一条新的mac指令。
System unit
系统单元实现系统控制和状态目标寄存器,执行所有的1.mtspr/1.mfspr指令。
Exception 异常
核实现了精确的异常模式,这意味着当异常发生时会出现下面的一些状况:
后面出现在程序流程的指令将被忽略
之前的指令结束及写回它们的结果
默认指令的地址保存在EPCR寄存器中,状态机被保存在ESR寄存器中

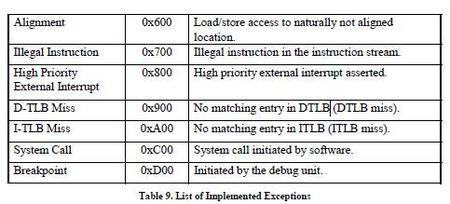
OR1200异常支持的并不包含快速内容切换(fast context switching)。
Data cache operation
Data cache load/store access
Load/store 单元从data cache中请求数据,存数据到通用目的寄存器文件中,然后送到整数执行单元执行指令。因而LSU和data cache紧密耦合。
如果没有data cache line miss或者DTLB miss,load指令将花费2个周期执行,store操作花费1个周期执行。LSU处理所有的数据对齐操作。
数据可以以word,half-word或者字节的方式写入cache中,由于data cache仅执行write-through模式,所有的写都会立刻写回主存或者下级cache中。

图6给出了当存指令hits到data cache中时,write-through在总线wishbone上的时序。如果dwb_ERR_I or dwb_RTY_I被检测到,而不是dwb_ACK_I被检测到,总线错误(bus error)异常将会发出。
Data cache line fill operation
当执行load指令和cache miss发生时,4拍(第一拍是关键字)顺序读突发将会发生,关键字is forwarded to the load/store unit防止由于cache miss造成的性能损失。

图7给出了cache line在wishbone总线上读周期,它由4个读传输构成。如果dwb_ERR_I or dwb_RTY_I被检测到,而不是dwb_ACK_I被检测到,总线错误(bus error)异常将会发出。
当执行store instruction和cache miss发生时,带有关键字的4拍连续读突发将会发生。读突发之后,单字写会将store instruction的数据写回主存或者下级cache中。无论store instruction的宽度时多少,综合有一个word write 执行。

图8给出了cache line在wishbone总线上读周期,其后跟了写传输。如果dwb_ERR_I or dwb_RTY_I被检测到,而不是dwb_ACK_I被检测到,总线错误(bus error)异常将会发出。
Cache/Memory coherency(存储器和高速缓存一致性)
在OR1200中Data cache仅按照write-through模式运行。OR1200目标并不是多处理器环境。因而在本地data cache和另外处理器cache或者主存中并未考虑一致性问题。
Data cache enabling/Disabling
Data cache在刚上电时是禁用的,可以通过设置SR[DCE]的bit位进行使能。在data cache使能前,它必须是无效的。
Data cache Invalidation
在OR1200中,并不支持所有的data cache 无效,正常的过程是通过循环访问cache lines单独无效每一行。
Data cache locking
Data cache采用存储在data cache中的way locking bits的方式控制DCCR寄存器。Bits LWx lock individual ways when they are set to one。
Data cache line prefetch
Data cache line prefetch 在OR1000架构中是可选择的,在OR1200中并未去实现。
Data cache line flush
由于data cache 操作仅仅是write-through 模式,data cache line flush表现为行无效(line invalidation),仅执行将EA(effective address)写回DCBFR寄存器中。事实上data cache line flush和data cache line invalidate没什么区别。
Data cache line invalidate
Data cache line invalidate 无效单个数据cache line。执行写EA到DCBIR寄存器的操作。
Data cache line write-back
Data cache line write-back 操作并不执行任何命令,这是由于data cache操作仅仅执行write-through mode。
Data cache line lock
锁住单个的data cache lines在OR1200中并未实现。(locking of individual data cache lines is not implemented in or1200)
Instruction cache operation
Instruction cache instruction fetch access
Instruction 单元从instruction cache中请求指令,然后放入instruction单元的指令队列中,因而instruction 单元和instruction cache是紧密耦合的。
如果没有instruction cache line miss或者ITLB miss,取指令操作仅仅花费一个周期取执行。Instruction cache不能像data cache一样很明确的被修改,可以进行存指令。(can be with store instructions)
Instruction cache line fill operation
当cache miss时,会执行带关键字的连续4拍的读操作,关键字先到指令单元用于减少cache miss原因造成的性能损失。
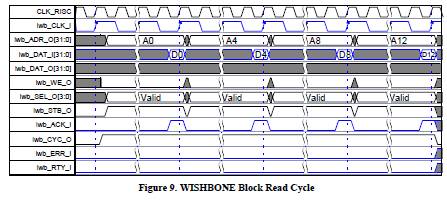
图9给出了cache line在wishbone 总线上的读周期,由4次读传输构成。如果dwb_ERR_I or dwb_RTY_I被检测到,而不是dwb_ACK_I被检测到,总线错误(bus error)异常将会发出。
Cache/Memory coherency(存储器和高速缓存一致性)
OR1200目标并不是多处理器环境。因而在本地data cache和另外处理器cache或者主存中并未考虑一致性问题。
Instruction cache enabling/Disabling
Instruction cache在刚上电时是禁用的,可以通过设置SR[ICE]的bit位进行使能。在Instruction cache使能前,它必须是无效的。
Instruction cache Invalidation
在OR1200中,并不支持所有的Instruction cache 无效,正常的过程是通过循环访问cache lines单独无效每一行。
Instruction cache locking
Instruction cache采用存储在Instruction cache中的way locking bits的方式控制ICCR寄存器。Bits LWx lock individual ways when they are set to one。
Instruction cache line prefetch
Instruction cache line prefetch 在OR1000架构中是可选择的,在OR1200中并未去实现。
Data cache line invalidate
Instruction cache line invalidate 无效单个数据cache line。执行写EA到ICBIR寄存器的操作。
Instruction cache line lock
锁住单个的Instruction cache lines在OR1200中并未实现。(locking of individual Instruction cache lines is not implemented in or1200)
Data MMU
Translation disabled
设置SR[DME]位可以屏蔽load/store地址翻译功能,如果屏蔽了翻译,采用物理地址访问data cache,可选择的提供dwb_addr_o信号,和load/store有效地址一样的功能。
Translation Enabled
设置SR[DME]位可以使能load/store地址翻译功能,如果使能了翻译功能,它会提供load/store有效地址进行物理地址翻译及存储器访问页保护机制。

在OR1200中,page tables必须由虚拟内存管理单元管理(virtual memory),图10给出了采用两级page table进行地址翻译的示意。参考OR1000系统架构设计手册中一级page table地址翻译及地址翻译和page table的详细内容。
DMMUCR and Flush of Entire DTLB
DMMUCR在OR1200系统架构中并未实现,因而基于pointer的page table必须存储在软件变量中,DTLB的flush操作必须采用软件实现,软件flush通过手动的将TLB entries写回PTEs中。
Page Protection
After a virtual address is determined to be within a page covered by the valid PTE,则访问是被存储器保护机制确认的,如果保护机制限制了访问,data page fault exception会产生。
存储器保护机制分别允许supervision and user模式进行读写访问,而页保护机制提供了在所有页面级粒度的保护。

图10列出了DTLBWyTR寄存器中定义的页保护属性,For the individual page appropriate strategy out of seven possible strategies programmed with the PPI field of the PTE。由于OR1200没有实现DMMUPR,翻译PTE[PPI]到合适的protection位必须由软件写入DTLBWyTR。
DTLB entry reload
OR1200并不支持硬件进行DTLB entry reload,采用软件为正确的PTE(page table entry)搜索page table及拷贝其到DTLB。软件负责管理在page table中的accessed和dirty bits。
当LSU计算load/store有效地址的时候,但其物理地址在DTLB还没有的时候,DTLB miss异常会发出。
DTLB reload过程必须load正确的PTE到正确的DTLBWyMR中。
DTLB entry invalidation
目的寄存器DTLBEIR必须写入有效地址,相应的DTLB entry在本地的DTLB中将会无效。
Locking DTLB Entries
由于所有的DTLB entry采用软件load,因而无硬件locking DTLB entry。采用软件的方式可以避免一些entry被替换掉。
Page attribute-dirty(D)
Dirty attribute在OR1200DTLB中并未实现,It is up to the operating system to generate dirty attribute bit with page protection mechanism。
Page attribute-accessed(A)
Accessed attribute在OR1200DTLB中并未实现,It is up to the operating system to generate dirty attribute bit with page protection mechanism。
Page attribute-weakly ordered memory(WOM)
由于存储器访问是顺序的,WOM在OR1200中也并未实现。
Page attribute-write back cache(WBC)
由于data cache仅仅进行write-through模式的操作,因而WBC在OR1200中并未实现。
Page attribute-Caching-Inhibited (CI)
Cached和uncached边界是以30bits作为有效地址划分的,因而CI在OR1200中也并未实现。

当所有的I/O寄存器采用存储器映射时,必须采用uncached访问,必须采用直接读写外部接口的方式,而不是访问data cache。
由于不支持多处理器环境及data cache仅进行write-through模式,因而cache coherency attribute并未在OR1200中进行实现。
Instruction MMU
Translation Disabled
可以通过设置SR[ime]位屏蔽指令取地址翻译功能,如果翻译功能被屏蔽,采用物理地址访问指令缓存and optionally provided on iwb_ADDR_O,和取EA效果相同。
Translation Enabled
设置SR[IME]位可以使能load/store地址翻译功能,如果使能了翻译功能,它会提供指令取有效地址进行物理地址翻译及存储器访问页保护机制。
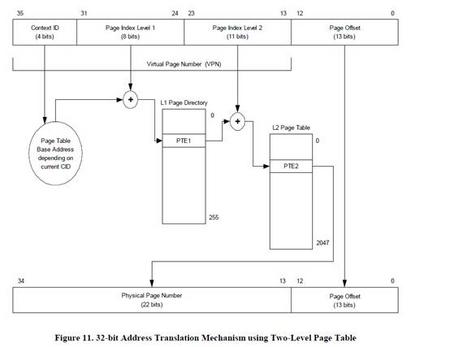
在OR1200中,page tables必须由虚拟内存管理单元管理(virtual memory),图11给出了采用两级page table进行地址翻译的示意。参考OR1000系统架构设计手册中一级page table地址翻译及地址翻译和page table的详细内容。
IMMUCR and Flush of Entire DTLB
IMMUCR在OR1200系统架构中并未实现,因而基于pointer的page table必须存储在软件变量中,ITLB的flush操作必须采用软件实现,软件flush通过手动的将TLB entries写回PTEs中。



 /5
/5 






文章评论(0条评论)
登录后参与讨论