
一、序言
Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以这里我们先由动量梯度下降引申出RMSprop,最后再介绍Adam。不过,由于RMSprop、Adam什么的,真的太难理解了,我就只说实现不说原理了。
二、RMSprop
先回顾一下动量梯度下降中的“指数加权平均”公式:
vDW1 = beta*vDW0 + (1-beta)*dw1
vDb1 = beta*vDb0 + (1-beta)*db1
动量梯度下降:
W = W - learning_rate*vDW
b = b - learning_rate*vDb
简而言之就是在更新W和b时不使用dw和db,而是使用其“指数加权平均”的值。
RMSprop只是做了一点微小的改变,为了便于区分将v改成s:
sDW1= beta*sDW0 + (1-beta)*dw1^2
sDb1 = beta*sDb0 + (1-beta)*db1^2
RMSprop梯度下降,其中sqrt是开平方根的意思:
W = W - learning_rate*(dw/sqrt(sDW))
b = b - learning_rate*(db/sqrt(sDb))
需要注意的是,无论是dw^2还是sqrt(sDW)都是矩阵内部元素的平方或开根。
三、Adam
Adam是结合动量梯度下降和RMSprop的混合体,先按动量梯度下降算出vDW、vDb
vDW1 = betaV*vDW0 + (1-beta)*dw1
vDb1 = betaV*vDb0 + (1-beta)*db1
然后按RMSprop算出sDW、sDb:
sDW1= betaS*sDW0 + (1-beta)*dw1^2
sDb1 = betaS*sDb0 + (1-beta)*db1^2
最后Adam的梯度下降是结合了v和s:
W = W - learning_rate*( vDW/sqrt(sDW) )
b = b - learning_rate*( vDb/sqrt(sDb) )
我们来看下最终实现后的效果:
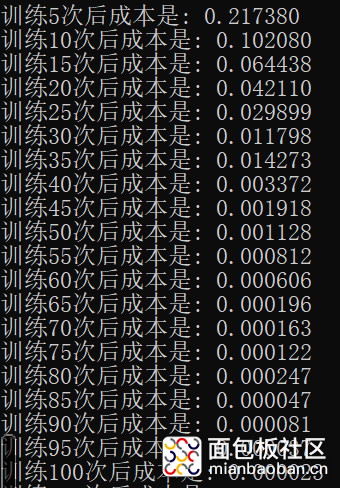
是的,你没有看错。。。只需要100次训练,就比以前2000次训练的效果还要好!看到这个结果其实我也很震惊,反复查了几遍。
不过使用Adam优化后的神经网络一定要注意learning_rate的设置,我这里改成了0.01(之前一直是0.1,多次试错后才发现是这个问题)否则会发生梯度消失(表现为dw等于0)。
四、回顾
本篇是在mini_batch的基础上,结合动量梯度下降、RMSprop做的Adam梯度下降,其目的与mini_batch、动量梯度下降一样,都是使神经网络可以更快找到最优解,不得不说Adam实在太给力了。完整的实现代码请关注公众号“零基础爱学习”回复“AI13”获取。

作者: 布兰姥爷, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3887969.html
版权声明:本文为博主原创,未经本人允许,禁止转载!



 /1
/1 







curton 2019-10-31 19:10