
一、前言
最近人工智能、深度学习又火了,我感觉还是有必要研究一下。三年前浅学了一下原理没深入研究框架,三年后感觉各种框架都成熟了,现成的教程也丰富了,所以我继续边学边写。原教程链接:
https://www.bilibili.com/video/BV1CW4y1r7Q7?p=1&vd_source=e8c67158ee12f84a27ae1bb40bb2775d
所以准备出个系列的教程,给不耐烦看视频或者只是想浅了解一下的同学。我选的框架tensorflow,据说GPT也是用的这个,应该是比较大众化的了。
二、前序准备
1.开发环境
(1)Python3.8
(2)Anaconda3
(3)Tensorflow
(4)Numpy
(5)Pandas
(6)Sklearn
先依次安装好上面的软件和包,其中python3.8和Anaconda3是直接下载安装,如果官方链接比较慢,可以搜下三方的源安装。其中Anaconda3不是必须的,用这个工具是因为确实挺香的。
剩下的3-6都是pip安装的包,注意使用Anaconda3的话就在Anaconda Prompt里使用pip命令,如果是其他集成环境或者原生的python环境,直接就在cmd里使用pip安装。
pip安装时可能会遇到下载特别慢的情况,建议使用国内源,方法参考下面链接:
https://mp.weixin.qq.com/s?__biz=MzUzOTY2OTcyMw==&mid=2247487143&idx=2&sn=b2cc99fcb09a774be78235c10d06d1c0&chksm=fac5ab13cdb222058f9b73d5c3600ad74194473ce9413cca5e069354f4e555b19f1293c39453&scene=27
实际安装过程可能会比较曲折,需要大家慢慢研究了,一般来说多搜索下都能解决问题。比如安装Sklearn不是pip install sklearn(虽然也能安装上另外一个不相干的包),实际应该用:
pip install scikit-learn
类似的坑多的很,一时半会也列不完,反正也是花了一个晚上才算是把开发环境给搞定。
2.数据准备
这次我们是要做天气预测,那自然是要弄到历史的天气数据。有三个路径,一是购买打包好的大数据,看了下便宜的都要好几千。二是网上爬数据,参考下面的链接:
http://lishi.tianqi.com/shanghai/201101.html
这个网站从2011年1月到最新的天气数据都有,可以自己爬下来,推荐使用“八爪鱼”,还是挺好用。
第三个路径就是做伸手党,正好我手上有上海的天气数据,在文章末尾链接提供。
我手上的这份数据分为“训练集”和“验证集”两个文件,直观来看训练集就是用于模型训练,验证集就是使用训练好的模型来预测试试,数据的格式一样,在使用时需要裁剪一下。
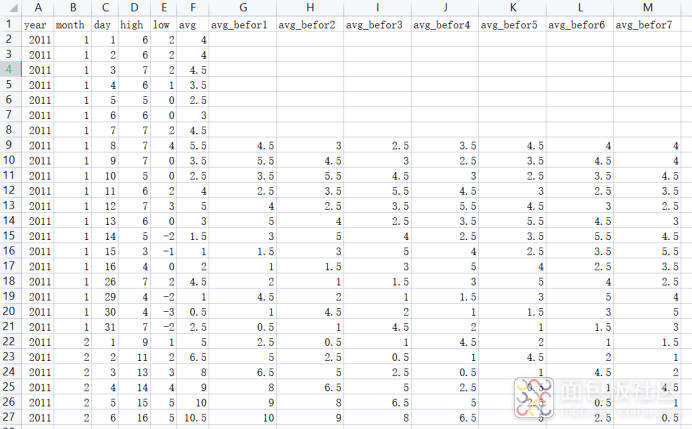
各字段的意思看名字就知道了,其中avg指的是当日平均温度,avg_befor1指的是昨天的平均温度,avg_befor2前天的,依次类推,一共回溯7天的。这个模型也就是用前7天的平均气温来预测当天的平均温度。
三、构建模型
1.读入待训练的数据
(完整代码跟前面天气数据放一起了)
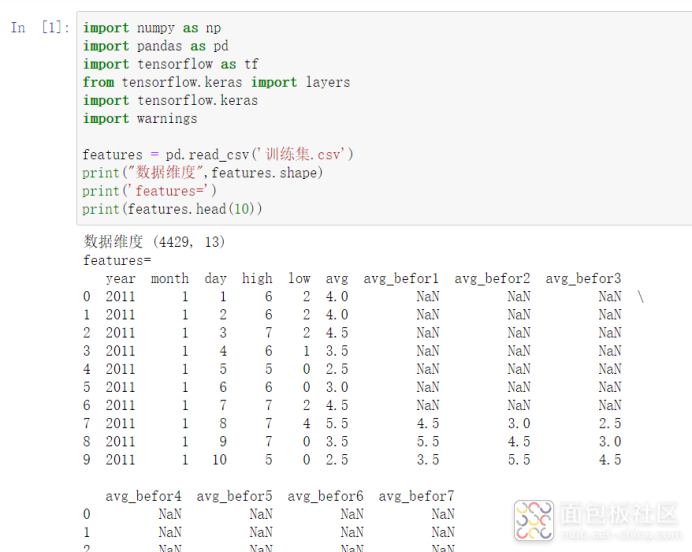
从上图,我们可以看到读入了4429行数据,每行有13列,这样的数据不能直接使用,需要裁剪一下。
2.数据裁剪
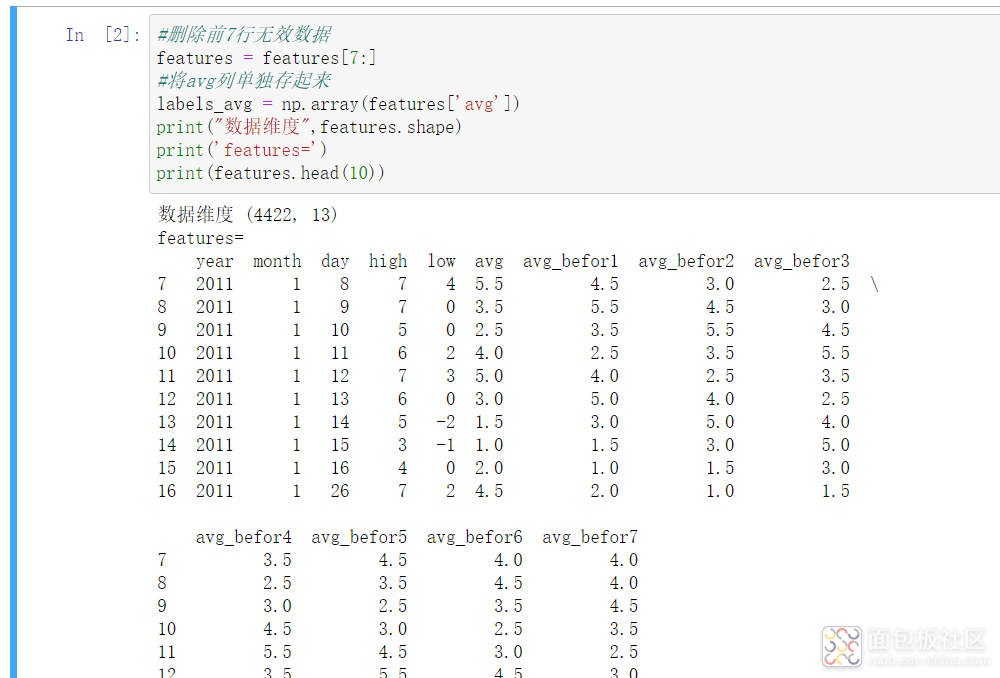
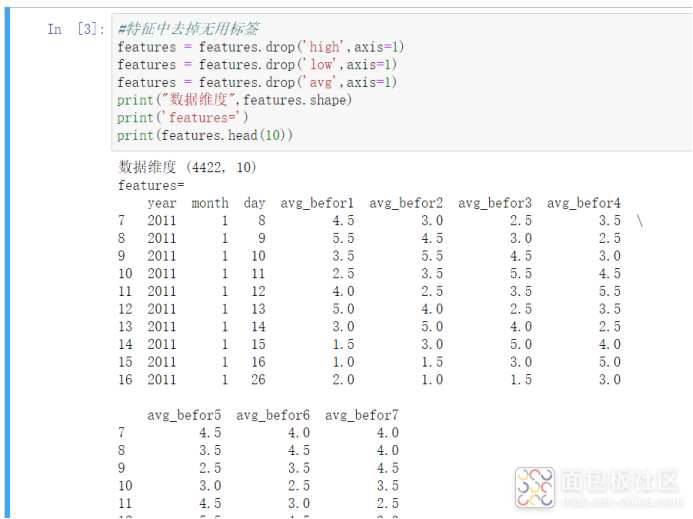
这里我们做了3个操作。
1)是将前7行有null的数据删除
2)是将avg这一列单独存起来了,用于后面的模型训练。
3)将high、low、avg三列从数据集中删除,因为我们是使用“历史数据”来预测当日的平均温度,这三列都属于当日数据所以要删除。
3.数据预处理
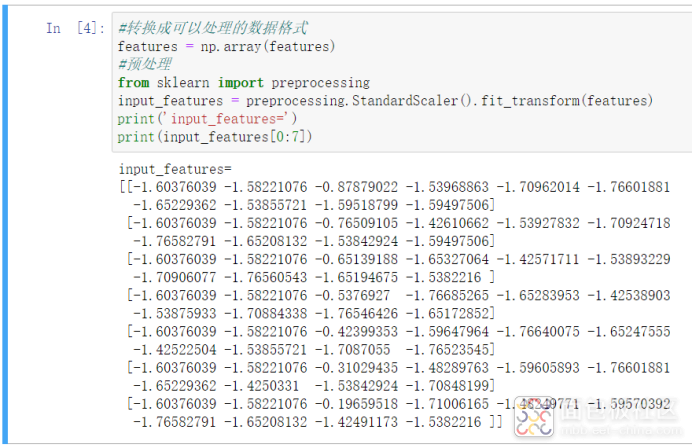
这里做了2个操作。
1)将数据集转化为array的形式,这样TensorFlow才能处理(自动去掉了title的内容)
2)将数据做归一化,主要是为了方便后面的模型训练,简单来说就是将15、20、30这些数字转化为-1到1之间的数字,可以参考下面这个链接。
https://blog.csdn.net/qq_51392112/article/details/129091683
4.构建模型

这里我们构建了一个16>32>1的神经网络模型,其中16、32、1指的是每一层的神经元数量,第一层与第二层的神经元数量无所谓可以随便写,第三层的1与预测的结果相对应,也就是我们使用前7天的平均温度,预测的是今天这“一个”平均温度。如果你预测的是当天最高温和最低温,就需要将第三层的1修改为2了。这里因为我们只预测1个结果(当天的平均温度),所以输出只需要1个。
其中model.compile是对神经网络进行配置,主要参数含义如下:


解释起来比较复杂,这里我们只管先用着,反正就是一些可以选择的参数,对模型的训练可能有很大影响,也可能没啥影响,一些资深人事主要工作就是调调这里改改哪里。
如果想改改参数看看效果,可以参考下面的链接:
https://blog.csdn.net/chaojishuai123/article/details/114580892
5.训练

model.fit里也有好几个参数,详细如下:
1)Input_features,输入的训练数据集
2)labels_avg,前面我们将avg列单独保存了起来就是为了用在这里
3)Validation_split=0.1,将其中的10%数据用于模型验证,剩下的90%用于模型训练
4)Epochs,迭代次数,也就是这些数据会被用于模型训练多少次
5)batch_size,每一次训练使用的数据量
除了features、labels,其他三个参数大家可以随意调调看对结果的影响。
上面截图中,注意有loss和val_loss两个结果,其中loss是模型训练后的“损失”,你可以理解loss越小则模型对你输入的数据匹配度越高(越契合你的训练数据)。Val_loss是模型验证的“损失”,也就是前面我们设置的那10%,这个值越小说明你的模型验证的结果也不错。
但Loss也不是越小越好,太小说明模型对你输入的数据产生了过拟合,可能结果是训练数据很不错但使用起来就很差。所以我们追求的其实是loss和val_loss的综合解,即在loss较低的情况下,val_loss也不太高。
6.输入待预测的数据
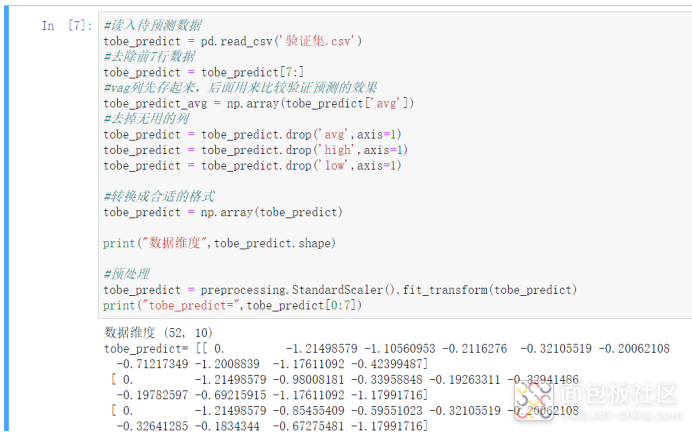
这里的操作与前面训练集其实很像,都是将数据读入后进行裁剪,同时将avg列另外存起来。最后将裁剪后的数据进行预处理。
7.预测
model1就是我们构建并训练好的模型了,现在我们可以使用前面准备好的训练集了。
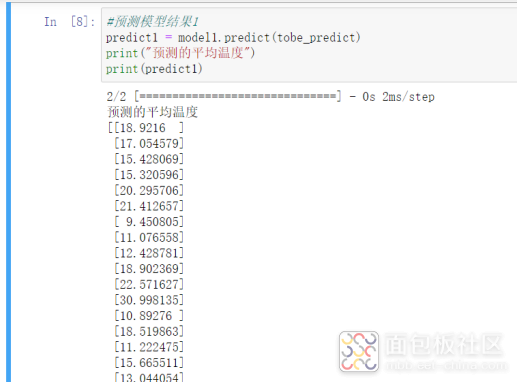
下面我们再看看实际温度,只能说是毫无关系,所以天气预报为什么不准呢对吧,说明根本就无法预测。不死心的同学可以试试自己修改下参数。

四、回顾
这是一次不太成功的示范,实际上我花了不少时间试图从最高温、最低温、平均温度、历史温度等找到温度变化的规律,但真的是没弄成。说明在深度学习中找对目标和数据集很重要啊。数据集和完整代码见下面的链接:
https://share.weiyun.com/mrL02s7J
作者: 布兰姥爷, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3887969.html
版权声明:本文为博主原创,未经本人允许,禁止转载!






Tyron 2023-4-26 11:34
怎么着也得60年的数据集吧