
一、前言
GPT的发布让AI再次热了起来,与上次阿尔法狗不同的是,现在人人都可以跟聊上几句,给它出出难题,还能调戏下。同期英伟达发布了针对AI领域的全新GPU H100,有的童鞋会疑惑,这个英伟达不是做显卡打游戏的吗,怎么就跟AI扯上关系了。其实英伟达的显卡不是简单的与AI有关系,而是大有关系。
二、图形处理与GPU
GPU的起源确实是基于图形处理的需求。早期还没有专门GPU时,我们打游戏所有的逻辑处理都放在CPU执行,CPU的处理能力越来越强,但经不住游戏画面增长的更快,这就对图形处理提出了更高的要求。
而图形处理的本质其实就是光影的计算,以下图为例,在屏幕上画一个圆非常简单。
但如过要让这个圆“立体”起来,其实就是要给它加上光影,像下图这样。

游戏画面也是这样的逻辑,一个画面优质的游戏一定是有丰富的光影效果,而光影效果的本质其实就是在虚拟的3维空间里,模拟光的照射。屏幕中的画面其实就是特定角度下,由计算机计算出的,你应该看到的光影效果。
需要特别注意的是,游戏中你会不停的移动,也就是所有光影的效果都需要实时的计算出来。假设屏幕分辨率为1920*1080,即2073600(207.36万)个像素,游戏中每个像素都需要根据光影参数来计算显示的颜色和明暗。假设一个常见的Inter I5 CPU主频为3.2GHz,即最多每秒可做32亿次运算。但这里的一次运算只是做了一次简单的二进制加减法或数据读取,一个像素的光影计算我们可以假设需要100次运算,即CPU一秒约处理3200万次像素运算,大概15张图片,用专业点的说法,这个游戏流畅度大概是每秒15帧的样子。
那我们能不能继续提升CPU的主频呢,可以但是能提升的空间非常有限。所谓主频本质上其实就是一个节拍器,CPU执行命令时其实是要按照一个特定的节拍来同步其各模块的操作。可以想象CPU其实就是个工厂流水线,1+1=2的本质其实至少包含了3个步骤:
1、将第一个1和第二个1从内存提取到CPU
2、两个1在CPU中相加得到2
3、将2从CPU存放到内存
本质上来说,所有的指令操作、图形计算,最终到达CPU时都会被拆分成类似于1+1=2这样的加法运算。而每一个节拍又只能执行其中的一步,如果我们可以将节拍打的更快一些,上述3个步骤执行的也就越快,那我们就说CPU的频率越高。但再往下看,我们打节拍又受到了晶体管开关速度的限制。简单来说,节拍打的越快,晶体管的开关速度也就更高,这就直接导致了CPU的发热问题。所以目前高性能CPU的频率始终被限制在5GHz,可见从CPU频率上已没有太多空间可以提升。工程师们就想到“其实任何一个像素的计算与其他像素的计算结果关系不大”,那为啥不多整几个计算核心“并行”计算呢,于是GPU就出现了。
一个典型的显卡GTX1060,主频是1.5GHz大概是Inter I5一半左右,但是它具备1280个计算核心。每个计算核心每秒可做15亿次运算,1280个核心每秒就是19200亿次运算,那一秒可以处理192亿次像素计算,大概925张图片,是CPU计算能力的61倍!但GPU的特性只能应用于图形计算这种可以并行的任务,若是做普通的串行任务其速度远远不如CPU。
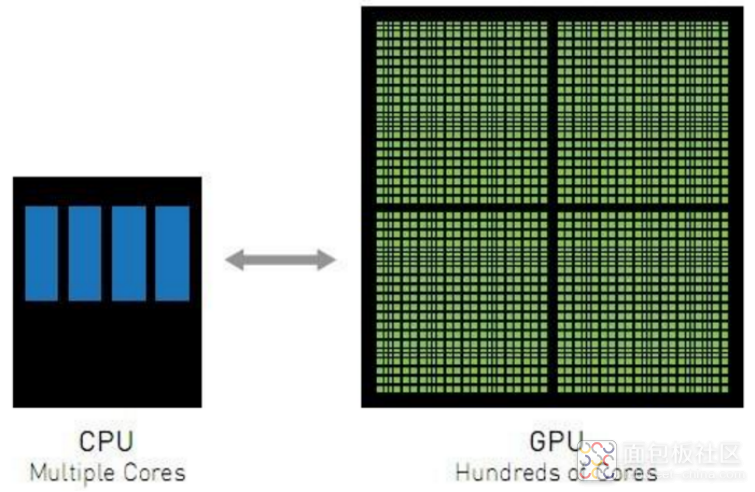
那我们能不能把CPU和GPU结合起来,让他频率高,核心数量还多呢?还是不得行,上千个核心提升一点点的主频就会带来一些列问题,比如撒热、抖动、稳定性等等。所以内核数与频率就是不可能三角,CPU与GPU都只能侧重于其中一面,在不同的领域发挥作用。
AI的本质其实与游戏差不多,也是大量的计算,只是计算的数据量会更庞大。
三、AI训练与矩阵计算
所谓训练AI,其实就是向神经网络中投喂大量的数据。比如我想要生成美女图片,以前的做法是建设一个有足够素材的库,让美女的各个元素(手、脚、嘴巴、眼睛、身材等等)随机组合在一起,结果可能差强人意。现在则只需要向神经网络里导入大量的美女图片,当你导入的图片数量足够多时,神经网络也就“学会”了什么是美女,这样它就能自动产出美女。相对应的,如果你一直输入的是猛男,那它也只能生产猛男了。
我们知道其实图片就是像素构成的,比如下面这张图的像素是8x8(简化示意),也就是64个像素点,我们可以用1x64这样的数组来表示它。
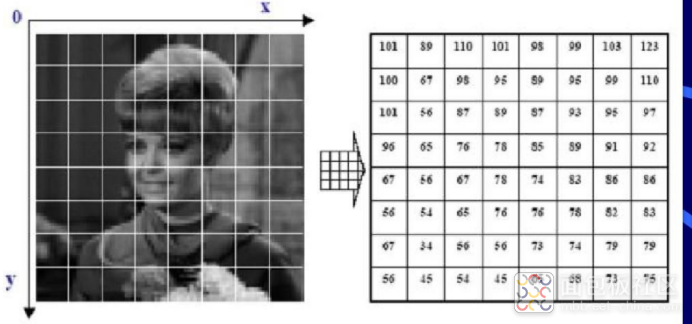
以下图这样的3层神经网络为例(原本是7个输入,我们修改为64个输入),所谓的数据“投喂”其实就是将图片以64个数字表示,然后输入到网络中。
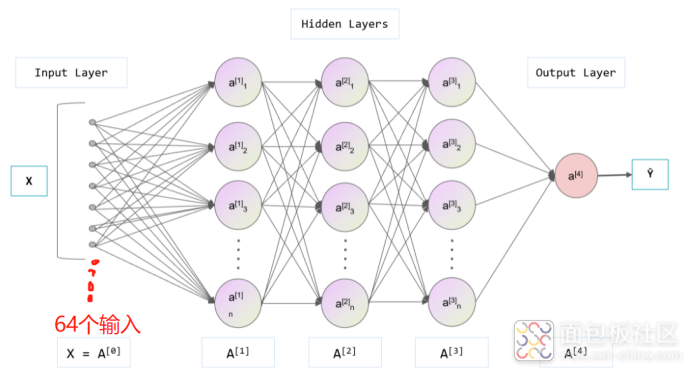
具体怎么输入呢,其实就是以A0(图片原始数据)为基础,来计算A1,接着以A1为基础计算A2、A3及最终结果A4。计算过程遵循以下公式:
A1 = W1*A0 + b1
A2 = W2*A1 + b2
A3 = W3*A2 + b3
A4 = W3*A3 + b4
其中W1\W2\W3\W4、A1\A2\A3\A4的数据量大小由每一层神经元的个数决定,比如我们每一层设置为64个神经元,则W1是一个64x64的数字矩阵,A1则是1x64的数字矩阵(与输入一样)。下图是一个矩阵相乘的示意。

所以对神经网络的投喂问题就变成了A0与W1两个数据矩阵的乘法问题,那么每一层神经网络的计算就需要至少4096次乘法计算,3层网络就需要至少12288次乘法计算。这还只是64x64像素的图片,如果是1280x1280的像素,就需要数百万次计算。
我们很容易就能想到也可以用GPU(显卡)来执行这些计算,因为每一张图片的输入都可以独立运行,那么我们给显卡的每一个核都输入一张图片,那同时就可以有上千张图片一起在计算,这样的计算效率自然是杠杠的。
五、AI与算力
综上所述,AI的发展离不开大量的算力资源,以GPT4来说,每1000字的算力大约需要0.06美元(约0.4元)。在小规模使用时可能还看不出成本的高低,当AI成为基础设施,比如搜索引擎,每天上亿次的搜索频率,成本可能也会去到上亿的数量级,这还只是其中一个应用。所以未来AI的发展离不开算力,英伟达则是在显卡的基础上,专门针对AI开发了特殊的GPU以满足算力需求,但可见的未来还是远远不够的。
参考前几年的数字挖矿,显卡的价格将迎来一波上涨。除计算性能外,另外还有更大的成本就是电力。所以可以预见的是,国内会出现一批专门做AI芯片设计的公司(参考比特大陆),还会有一批将数据中心建设到大西北以获取更廉价电力的小团队(普通人的机会),这些还都是国家大力支持的。所以发财的路子已经有了,朱军加油。
作者: 布兰姥爷, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3887969.html
版权声明:本文为博主原创,未经本人允许,禁止转载!


 /1
/1 





自做自受 2023-3-30 10:50