
软瓦格化 RISC-V 处理器集群可加速设计并降低风险
作者:John Min
 John Min是Arteris的客户成功副总裁。他拥有丰富的架构专业知识,能够成功管理可定制和标准处理器在功耗、尺寸和性能方面的设计权衡。他的背景包括利用 ARC、MIPS、x86 和定制媒体处理器来设计 CPU SoC,尤其擅长基于微处理器的 SoC。
John Min是Arteris的客户成功副总裁。他拥有丰富的架构专业知识,能够成功管理可定制和标准处理器在功耗、尺寸和性能方面的设计权衡。他的背景包括利用 ARC、MIPS、x86 和定制媒体处理器来设计 CPU SoC,尤其擅长基于微处理器的 SoC。
RISC-V 指令集架构 (ISA) 以其强大的功能、灵活性、低采用成本和开源基础而闻名,正在经历各个细分市场的快速增长。这种多功能 ISA 支持汽车、航空航天、国防、网络、电信、数据中心、云计算、工业自动化、人工智能 (AI)、机器学习 (ML)、嵌入式系统、物联网设备和消费电子等领域的应用。
在系统级芯片 (SoC) 设计中,RISC-V的可扩展性得到了充分展现。低端应用可能只需要一个单核处理器,中端应用可能会采用一组RISC-V 处理器核,而高端应用则可能需要一组RISC-V 集群。然而,传统的处理器集群手动配置方法费时费力且容易出错,限制了可扩展性,在设计灵活性和速度方面造成了瓶颈。一种名为片上网络 (NoC) 软瓦格化 (soft tiling) 的新技术能够有效解决这些问题。
RISC-V 配置的演进
RISC-V 的适应性使其能够应用于各种性能水平,从单核实现到支持数千个核的多集群配置。NoC 在促进这些配置之间的通信方面发挥着关键作用,具体如下:
在中端应用中,RISC-V 设计通常会扩展到 2 到 8 个核的集群,从而提供更强大的计算能力并支持并行处理。在这些应用中,核之间的高效通信对于保持性能至关重要。NoC互连提供了一个连接集群内各核的统一结构,并将它们连接到内存和外设,确保低延迟、高带宽的数据传输。NoC 通过优化的通信路径来实现这些配置所需要的灵活路由和高效资源,从而最大限度地降低功耗和延迟。
RISC-V 高端 SoC 架构
基于 RISC-V 的现代高端 SoC 可能采用这样的架构:中央处理器 (CPU) 由 RISC-V 处理器集群 (processor cluster, PC) 阵列组成,每个集群承载多个核(见图1)。同样,作为专为AI和 ML 任务定制的硬件加速器,神经处理单元 (network interface unit, NPU) 可能由处理部件 (processing element, PE) 阵列组成,为复杂的工作负载提供专门处理。
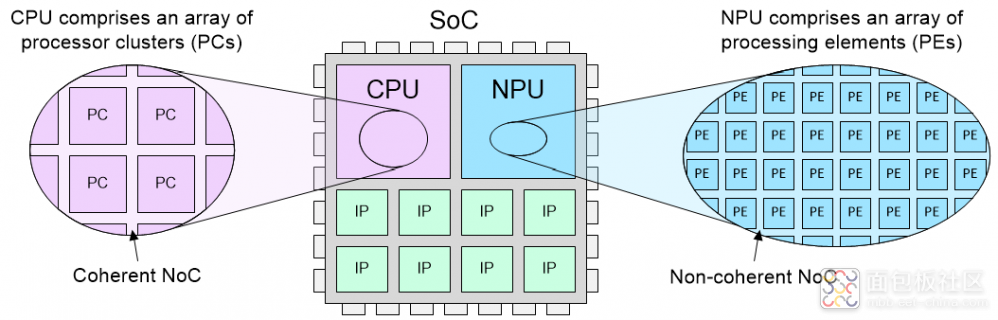
图1. 采用RISC-V的高端SoC示例。(Source: Arteris)
当今的 SoC 可以包含数十亿个晶体管,集成了数百个 IP 模块的功能单元。虽然一些 IP 来自可信赖的第三方供应商,但设计团队通常会在内部开发定制的IP 模块,以增强其SoC的竞争力。
NoC 技术已成为 SoC 中这些 IP 的标准互连解决方案。虽然 SoC 团队可以在内部设计 NoC,但这是一项资源密集型工作,需要与其他 SoC 组件进行大量调试和测试。这就占用了他们用于提高产品核心竞争力的时间。因此,许多团队选择从专门从事该技术的供应商处购买 NoC IP。
根据设计方法的不同,SoC 团队可以开发自定义 RISC-V 处理器内核和集群,也可以将其作为 IP 从可信供应商处获取。在每个集群内部,RISC-V 核通常使用其专有总线(一种专门的 RISC-V 总线协议)进行通信。不过,有些集群可能会使用其他 NoC 技术,可以内部开发也可以外部采购。
在将 RISC-V 集群与 SoC 的其他部分或集群阵列连接时,每个集群都会向外界公开一个接口。传统上采用的是 Arm 的 AXI 一致性扩展 (ACE) 协议。但最近Arm 的一致性集线器接口 (CHI) 规范大受欢迎,因为它提供一致性接口,能够将处理器集群连接到实现缓存一致性协议的一致性 NoC中。
相比之下,组成 NPU 阵列的 PE 通常使用非一致性 NoC 连接。它们将使用类似于 Arm 高级可扩展接口 (AXI) 的接口连接到该 NoC。值得注意的是,每个 PE 可能包含多个通过内部 NoC 连接的 IP。
手工生成阵列
创建 PC 阵列和 PE 阵列的过程基本相同。唯一真正的区别在于 PC 使用一致性 NoC 而 PE 使用非一致性 NoC。处理单元 (processing unit, PU) 包括 PC 和 PE两部分。
阵列生成通常由人工完成。第一步是创建或获取第一个 PU。然后将该 PU 复制到所需大小的阵列中(图 2a)。第二步是使用 NoC 工具自动生成 NoC(图 2b)。
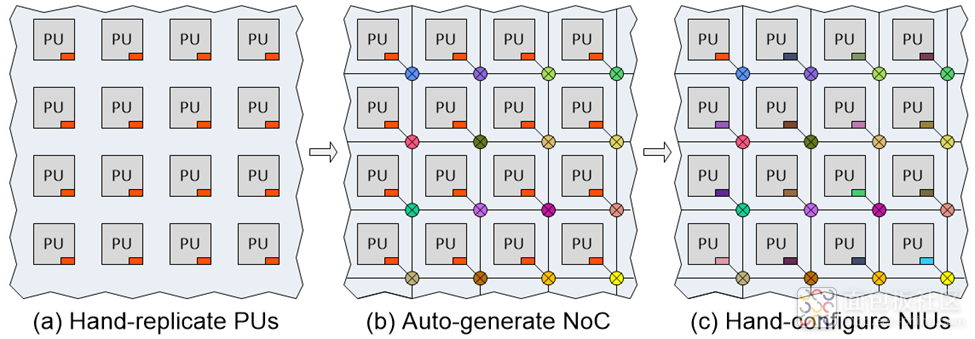
图2. 手工生成阵列。(Source: Arteris)
在图 2 中,每个处理单元 (PU) 角落里的红色小矩形代表网络接口单元 (NIU)。这些单元允许 IP 块与 NoC 通信。每个 NIU 都需要一个唯一的地址,以便 NoC 将数据包从源 IP 引导到目的地。传统上,这些地址都是手工添加到 NIU 中的。
复制 PU 和手动配置 NIU 的工作既费时又费力,还容易出错。此外,在开发周期的早期,PU 可能会经历多次更改,每次更改都需要重新复制 PU 并重新配置 NIU。
使用基于 NoC 的软瓦格化技术生成阵列
Arteris开发了一种新的软瓦格化 (soft tiling) 技术,该技术已无缝集成到我们的Ncore和FlexNoC片上网络IP技术中(图3)。SoC 开发团队创建初始 PU 后,只需指定阵列的行数和列数并启动流程。然后,该工具就会自动复制 PU、生成 NoC 并为 NIU 配置唯一地址。
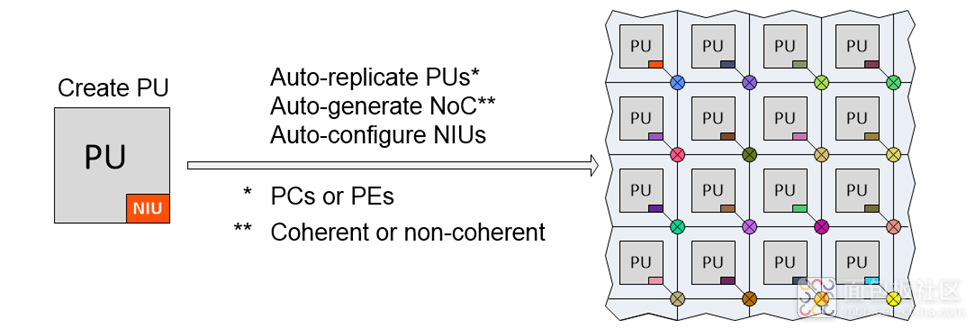
图3. 使用Arteris的基于NoC的软瓦格化技术生成阵列 。(Source: Arteris)
这项技术既可用于 NPU 等非一致性阵列中的 FlexNoC 互连 IP,也可用于 RISC-V 处理器集群等一致性阵列中的 Ncore 一致性 NoC IP。
这种自动复制和自动配置需要几秒到几分钟的时间,具体取决于阵列的大小和 PU 的复杂程度。因此,可以快速轻松地适应对原始 PU 的任何设计更改。同样,阵列也可以根据需要轻松扩展,并且很容易生成具有更大或更小阵列的衍生设计。
总结
开发具有 RISC-V 处理器集群阵列的高端 SoC 是一项复杂且成本高昂的工作,需要花费大量的时间和精力。手动 PU 复制和 NIU 配置等低端任务很容易出错,而且会耗费宝贵的时间,而这些时间本可以更好地用于应对更高端的设计挑战。
Arteris的NoC软瓦格化技术通过自动配置和扩展复杂的RISC-V架构解决了这些问题。这种自动化使设计团队能够将时间和精力集中在其他方面。通过简化 RISC-V 核和集群的集成,Arteris 的解决方案加快了开发进程。了解有关 NoC 瓦格化的更多信息,请访问 arteris.com。
作者: ArterisIP, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3893295.html
版权声明:本文为博主原创,未经本人允许,禁止转载!


 /2
/2 





文章评论(0条评论)
登录后参与讨论