
作者|羿川
审校|泰一

虚拟背景依托于人像分割技术,通过将图片中的人像分割出来,对背景图片进行替换实现。根据其使用的应用场景,大体可以分成以下三类:
直播场景:用于氛围营造,例如教育直播、线上年会等;
实时通讯场景:用于保护用户隐私,例如视频会议等;
互动娱乐场景:用于增加趣味性,例如影视编辑、抖音人物特效等。


语义分割旨在对图像的每个像素进行标签预测,在自动驾驶、场景理解等领域有着广泛的应用。伴随移动互联网、5G 等技术的发展,如何在算力受限的终端设备进行高分辨率的实时语义分割,日益成为迫切的需求。上图列举了近年来的实时语义分割方法,本小节将对其中的部分方法进行介绍。
BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation

先前的实时语义分割算法通过限定输入大小、减少网络通道数量、舍弃深层网络模块来满足实时性的需求,但是由于丢弃过多空间细节或者牺牲模型容量,导致分割精度大幅下降。因此,作者提出了一种双边分割网络(BiseNet,ECCV2018),网络结构如上图所示,该网络由空间路径(Spatial Path)和语义路径(Context Path)组成,分别用于解决空间信息缺失和感受野缩小的问题。
空间路径通过通道宽、深度浅的网络来获取高分辨率特征,保留丰富的空间信息;而语义路径则是采用通道窄、深度深的轻量骨干模型,通过快速下采样和全局平均池化提取语义信息。最后利用特征融合模块(FFM)对两个路径的特征进行融合,实现精度和速度之间的平衡。该方法在 cityscapes 测试集上的 MIOU 为 68.4%。

升级版 BiseNetV2 延续了 V1 版本的思想,网络结构如上图所示,V2 版本去除了 V1 空间路径中耗时的跳跃链接(skip connection),增加双向聚合层(Aggregation Layer)增加两个分支之间的信息聚合,并提出了增强训练策略进一步提升分割效果,在 cityscapes 测试集上的 MIOU 提升到了 72.6%,在使用 1080Ti 的 TensorRT 上 FPS 可以达到 156。
DFANet:Deep Feature Aggregation for Real-Time Semantic Segmentation

DFANet(CVPR2019)设计了子网聚合和子阶段聚合两种特征聚合策略来提升实时语义分割的性能。DFANet 的网络结构如上图所示,包含 3 个部分:轻量骨干网络、子网聚合和子阶段聚合模块。轻量骨干网络采用了推理速度较快的 Xception 网络,在其顶层加入全连接注意力模块增大高层特征的感受野;子网聚合通过重用先前骨干网络提取的高层特征,将其上采样后作为下一个子网的输入,增大感受野的同时,细化预测结果;子阶段聚合模块则是利用不同子网相应阶段的特征融合多尺度结构细节,增强特征的判别能力。最后通过轻量的解码器,融合不同阶段输出的结果,从粗到细地生成分割结果。在 Cityscapes 测试集上 MIOU 为 71.3%,FPS 为 100。
Semantic Flow for Fast and Accurate Scene Parsing

受到光流的启发,作者认为由同一张图片生成的任意两个不同分辨率的特征图之间的关系,也可以用每个像素的流动表示,提出了 SFNet(ECCV2020),网络结构如上图所示。
因此,作者提出了语义流对齐模块(Flow Alignment Module (FAM))来学习相邻阶段特征的语义流,然后通过 warping 将包含高层语义的特征广播到高分辨率的特征上,从而将深层特征的丰富语义高效传播到浅层的特征,使得特征同时包含丰富语义和空间信息。作者将 FAM 模块无缝插入到 FPN 网络中融合相邻阶段的特征,如上图所示。SFNet 能在实时分割的情况下(FPS 为 26),在 Cityscapes 可以达到 80.4% mIoU。
人像分割
人像分割是语义分割的子任务,目标是将图片中的人像从背景中分割出来,属于二类分割。相比于语义分割,人像分割相对简单,一般应用于手机端等端侧设备,目前的研究目标大体可以分为两类,一是通过改进网络设计轻量高效人像分割模型,二是增强人像分割的细节。
Boundary-sensitive Network for Portrait Segmentation

BSN(FG2019)主要关注于提升人像的边缘分割效果,主要通过两种边缘损失进行实现,分别是针对每幅人像的边缘 Individual Kernel 和针对人像数据集计算的平均边缘 Global Kernel。Individual Kernel 与之前的方法类似,通过膨胀、腐蚀操作获取人像边缘标签,不同的地方在于,它将边缘作为区分于前景、背景的第三种类别,用 soft label 表示,从而将人像分割转变为 3 类分割问题,如上图。Global Kernel 的标签则是通过统计人像数据集边缘平均值得到,通过 Global Kernel 告诉网络人像大致所在位置的先验信息。同时,为了提供更多的人像边缘先验,作者增加了区分长短发边缘的二分类分支,与分割网络进行多任务协同训练。BSN 在 EG1800 人像分割测试集的 MIOU 为 96.7%,但在速度上并无优势。
PortraitNet:Real-time Portrait Segmentation Network for Mobile Device

PortraitNet(Computers & Graphics 2019)基于深度可分离卷积设计了一个轻量的 u-net 结构,如上图所示,为了增加人像边缘的分割细节,该方法通过对人像标签进行膨胀、腐蚀操作生成人像边缘标签,用于计算边缘损失(Boundary loss)。同时,为了增强对光照的鲁棒性,该方法提出了一致性约束损失(Consistency constraint loss),如下图,通过约束光照变换前后图片的人像分割结果保持一致,增强模型的鲁棒性。PortraitNet 模型参数大小为 2.1M,在 EG1800 人像分割测试集的 MIOU 为 96.6%。

SINet:Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder

SINet(WACV2020)则侧重于在提升人像分割网络的速度,由包含空间压缩模块(spatial squeeze module)的编码器和包含信息屏蔽机制的解码器(information blocking scheme)组成,网络框架上图所示。空间压缩模块(如下图)在 shuffleNetV2 模块的基础上,在不同路径上使用不同尺度的池化操作压缩特征空间分辨率,提取不同感受野的特征来应对不同尺度的人像,减少计算延时。信息屏蔽机制则是根据深层低分辨率特征预测的人像置信度,在融合浅层高分辨率特征时,屏蔽高置信度区域,只融合低置信度区域的浅层特征,避免引入无关的噪声。SINet 在 EG1800 人像分割测试集的 MIOU 为 95.3%,但模型参数大小只有 86.9K,和 PortraitNe 相比减少 95.9% 的参数。


一张图像可以简单的看成是由两部分组成,即前景(Foreground)和背景(Background),图片抠图,就是将一张给定图像的前景和背景区分开来,如上图所示。由于图片抠图是一个欠约束问题,传统抠图算法和早期的基于深度学习的算法方法,主要通过输入额外的语义信息作为约束,最常见的是由前景、背景和不确定区域组成的 trimap,如下图所示。抠图算法的精度受 trimap 的精度影响很大,当 trimap 较差时,基于 trimap 的算法的预测结果下降严重。trimap 的获取主要通过其他算法生成(如语义分割)或人工标注生成,但是通过其他算法生成的 trimap 一般较为粗糙,而人工标注精确的 trimap 则费时费力。trimap-free 的抠图算法逐渐进入人们的视野,本小节将主要对近期的 trimap-free 的人像抠图算法进行介绍。

Background Matting: The World is Your Green Screen

Background Matting(CVPR2020)尝试通过引入静态的背景信息来提升人像抠图的效果,相比于使用人工精细标注的 trimap,获取前景所在的静态背景要相对容易,该方法的操作流程如上图所示,首先获取场景的两张图片,一张包含前景,另一张不包含,然后使用深度网络预测 alpha 通道,进而进行背景合成,因此,这个方法主要针对的场景是静态背景下只有轻微相机抖动的人像抠图。

该方法的模型结构如上图所示,模型处理流程大体如下:给定输入图片和背景图片,首先通过分割模型(如 deeplab)获取前景图片的粗分割结果,然后同 Context Switching Block 模块,对不同的输入信息的组合进行选择,随后输入到解码器中同时预测前景和 alpha 通道。训练过程分成两个阶段,首先在 Adobe 的合成数据集上进行训练,为了降低合成图片和真实图片的 domain gap 造成的影响,使用 LS-GAN 在无标签的真实图片和背景图片上进行第二阶段的对抗训练,通过拉近预测的 alpha 通道合成的图片和真实图片的距离,提升抠图的效果。当背景变换较大或与前景差异较大时,该方法的效果不佳。
Boosting Semantic Human Matting with Coarse Annotations

这篇文章(CVPR2020)认为影响人像抠图算法效果的原因主要来自两个方面,一是 trimap 的准确性,二是获取人像精确标注的成本高、效率低,导致人像抠图数据集图片数量较少,因此这篇文章提出了一种只需部分精细标注数据(上图 (b))结合大量粗标数据(上图 (a))提升人像抠图效果的方法。

该方法的网络结构如上图所示,由 3 个模块组成:MPN,粗 mask 预测网络;QUN:mask 质量统一网络;MRN,matting 细化网络,coarse-to-fine 地逐步优化分割的结果。训练时,首先使用粗标数据和精标数据同时训练 MPN,获取粗 mask,然后使用精标数据训练 MRN,细化分割结果。但是文章作者发现,由于粗标数据和精标数据的标注差异,导致两者 MRN 预测预期存在较大的 GAP,从而影响性能,因此,作者提出了 QUN,对粗 mask 的预测结果进行质量统一。

实验效果如上图所示,相比于只使用精标数据训练,结合粗标数据对于网络语义信息的提取有较大的帮助。同时,结合 QUN 和 MRN,可以对已有数据集的粗标数据进行细化,降低精细标注的获取成本。
Is a Green Screen Really Necessary for Real-Time Human Matting?
现有的人像抠图算法,或需要额外输入(如 trimap、背景), 或需要使用多个模型,无论是获取额外输入的开销还是使用多个模型的计算开销,使得现有方法无法实现人像抠图的实时应用。因此,文章作者提出了一种轻量的人像抠图算法,只使用单张输入图片即可实现实时人像抠图效果,在 1080Ti 上处理 512x512 大小的图片,可以到达 63FPS 的效果。

如上图所示,本文的方法可以分为 3 个部分,首先是在标注数据上通过多任务监督学习的方式训练人像抠图网络,然后通过 SOC 自监督策略在无标注的真实数据上进行微调,增强模型泛化能力;在测试时,使用 OFD 策略提升预测结果的平滑性,下面会对这 3 个部分进行详细介绍。

MODNet 的网络结构如上图所示,作者受到基于 trimap 的方法的启发,将 trimap-free 的人像抠图任务分解成了 3 个相关连的子任务进行协同训练,分别是语义预测、细节预测和语义 - 细节融合。通过低分辨率的语义分支捕捉人像主体,通过高分辨率的细节分支提取人像边缘细节,最后通过融合语义、细节得到最终的人像分割结果。
当应用到新场景的数据时,3 个分支产生的结果可能会有差异,因此作者提出了利用无标注的数据的 SOC 自监督策略,通过让语义 - 细节融合分支预测结果在语义上和语义分支预测结果保持一致,在细节结果上和细节分支预测结果保持一致,增强不同子任务之间预测结果一致性约束,从而增强模型的泛化能力。

直接对视频的每帧图片进行单独预测会导致相邻帧预测结果存在时序上的不一致,从而出现帧间跳闪的现象。作者发现,跳闪的像素点是可能可以通过相邻帧的预测结果进行纠正,如上图所示。因此,作者提出,当前一帧和后一帧的像素预测结果小于一定阈值,同时当前帧预测结果和前后帧的预测结果大于一定阈值时,则可以用前后帧的预测结果的平均作为当前帧的预测结果,从而避免不同帧预测结果时序上的不一定导致的帧间跳闪现象。
Real-Time High-Resolution Background Matting

现有的人像抠图算法虽然可以生成比较精细的抠图结果,却无法做到实时地处理高分辨率的图片,例如 Background Matting 在 GPU 2080Ti 上每秒只能处理约 8 张 512x512 大小的图片,这无法满足实时应用的需求。文章作者发现,对于高分辨率的图片,只有少部分区域是需要精细分割(如上图所示),大部分区域只需粗分割即可,如果让网络只对需要精细分割的少部分区域进行进一步的分割优化,就可以节省大量的计算。作者借鉴了 PointRend 的思路,基于 Background Matting,提出了一种实时处理高分辨率图片的双阶段人像抠图网络,在 2080Ti 上处理高清图片(分辨率为 1920x1080)可以达到 60FPS,对于 4K 图片 (分辨率为 3840x2160),可以达到 30FPS。

本文提出的双阶段网络框架如上图所示,由基础网络和细化网络组成。第一阶段的基础网络采用了类似 DeeplabV3+ 的 encoder-decoder 结构,用于生成人像粗分割结果、前景残差、错误预测图和包含全局语义的隐藏特征。第二阶段的细化网络,利用第一阶段产生的错误预测图,挑选出需要进行分割细化的前 k 个图片块,进行进一步分割优化,最后将细化后的分割结果和直接上采样放大的粗分割结果进行融合,得到最终的人像分割结果。和其他方法的对比,本文方法在速度和模型大小上均有明显的提升,如下图所示。


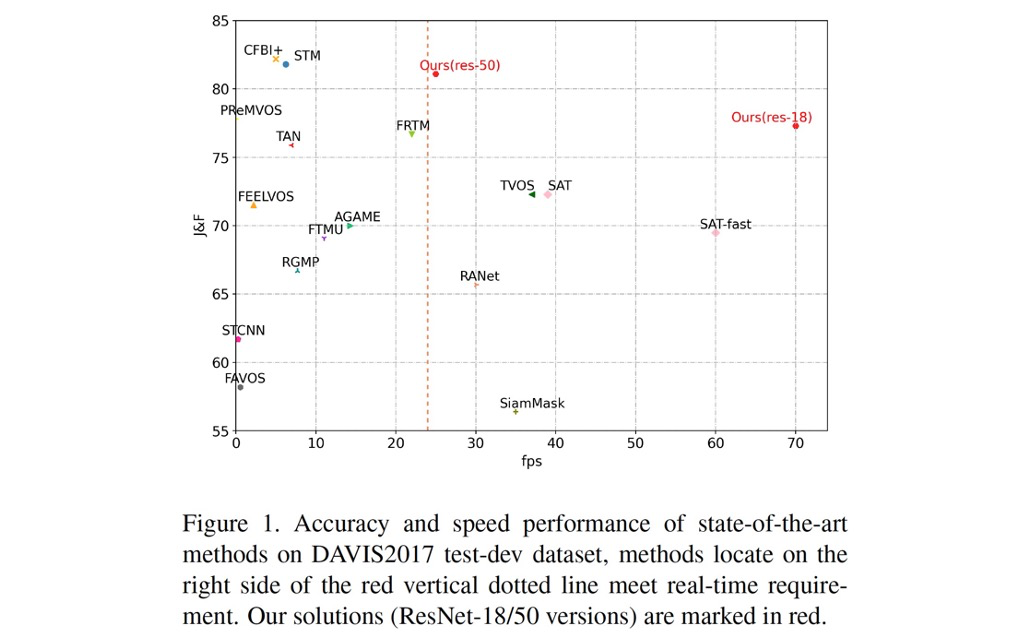
视频目标分割(Video Object Segmentation,简称为 VOS),旨在从视频每一帧获得兴趣目标的像素级分割结果。相比于单帧图像分割,视频分割算法主要依托于多帧间的连续性,从而实现分割结果的高平滑和高精度。目前,VOS 任务可以分为半监督(seme-supervised,one-shot)分割与无监督(unsupervised,zero-shot)两类。前者在运行时需要输入原始视频和视频首帧分割结果,而后者只需输入原始视频。现有半监督 VOS 算法很难达到精确且实时的分割,研究重心一般侧重于两者之一,现有 VOS 算法效果 [12] 如下图所示。
视频会议作为日常办公中高频场景,伴随着居家办公的火热,对用户隐私的保护提出了更高的需求,视频会议虚拟背景功能踏浪而来。相比于云端的高性能服务器,个人场景的视频会议载体主要是各色的笔记本电脑,不同型号笔记本电脑性能参差不齐,而视频会议对实时性要求较高,会议背景不一,这对端侧算法的性能提出了更严苛的需求。
实时性需求决定了端侧人像分割模型要做到足够轻量化,而小模型对一些困难场景(例如人像边缘与背景相似等)的处理能力较弱,同时对于数据比较敏感,这易导致背景错分为人像、人像边缘模糊等,针对这些问题,我们分别在算法和数据工程上,进行了一些针对性地调整和优化
算法探索1) 优化边缘:
第一种优化边缘的方法构造边缘损失,参考 MODNet,通过对人像标签进行膨胀腐蚀操作,得到人像边缘区域标签,通过对边缘区域计算损失来增强网络对边缘结构的提取能力。
第二种优化边缘方法是使用 OHEM 损失,相比于人像主体区域,人像边缘区域往往容易错误分类,在训练时,通过对人像分割的预测结果进行在线难例挖掘,可以隐性地优化人像边缘区域。
2) 无监督学习:
第一种无监督学习方法通过数据增强实现,参考 PortraitNet,对于给定的一张输入图片图片,对其颜色、高斯模糊和噪声组成的数据增强处理后得到变换后的图片图片,虽然图片相对图片在外观上发生了变化,但变化前后两张图片对应的前景人像是一样的,因此,可以通过 KL Loss 约束数据增强前后图片预测结果保持一致,从而增强网络对光照、模糊等外界条件变化的鲁棒性。
第二种无监督学习方法是通过利用无标签的真实图片和背景图片进行对抗训练实现,参考 Background Matting,在模型训练时,通过引入额外的鉴别器网络,判断输入鉴别器的图片是由网络预测的人像前景和随机背景合成的,还是真实的图片,减少人像预测结果中存在的 artifact。
3) 多任务学习
多任务学习通常是指增加与原任务相关的子任务进行协同训练,提升网络在原任务上的效果,例如 Mask-RCNN 中检测和分割任务。人像分割的难点之一是当视频中的人像做出一定动作时(例如挥手等),对于手臂等部位的分割效果较差。为了更好的捕捉人体的信息,我们尝试在模型训练引入人体姿势信息进行多任务训练,参考 Pose2Seg,通过解析人像姿势来更好地的捕捉肢体动作信息。在测试时,只需使用训练的人像分割分支进行推理,能在提升分割的准确率的同时,兼顾了性能。

4) 知识蒸馏
知识蒸馏被广泛的用于模型压缩和迁移学习中,通常采用 teacher-student 学习策略。首先事先训练性能较强的 teacher 模型(例如 DeeplabV3+),在训练 student 模型时,利用 teacher 模型生成的软标签作为监督信息,指导 student 模型训练。相比于原始的 one-hot 标签,teacher 模型预测的软标签包含了不同类别数据结构相似性的知识,使得 student 模型训练更易收敛。

5) 模型轻量化
针对业务场景的需要,我们选用了基于 mobilenet-V2 网络的 U-net 结构,根据 mnn 算子的特点,对模型进行优化裁剪,以满足实际业务性能需求。
6) 策略优化
在实际开会场景中,不少参会人员在很多时候是保持不动的。在这种状态下,用实时帧率去做人像分割,存在一定的浪费资源。针对这种场景,我们设计了一种边缘位置帧差法,基于相邻帧人像边缘区域的变化,对人像是否移动进行准确判断,同时该方法能够有效去除人物说话、表情变化、外部区域变化等干扰。边缘位置帧差法可以有效降低参会人员静止时人像分割算法的频率,从而大大降低了能耗。
数据工程人像分割对于数据较为依赖,现有的开源数据集与会议场景有较大差异,而分割数据的标注获取费时费力,为了降低数据获取成本、提升已有数据的利用率,我们尝试在数据合成、自动化标注上做了一些尝试。
1) 数据合成
在数据合成时,我们利用已有模型筛选出部分较好的子数据集,利用平移、旋转、薄板变换等方式,增加人像姿态和动作的多样性,然后与会议场景的不同背景进行融合,扩充训练数据。在数据变换时,若人像标签与边界相交,则利用坐标关系,在合成新图片时,保持标签和边界的原有相交关系,避免人像与边界分离、浮空等现象,让生成的图片更加真实。
2) 自动化标注、清洗
通过利用现有多种开源的检测、分割、matting 算法,设计了一套高效的自动化标注、清洗工具,进行数据的快速自动化打标和清洗质检,降低数据标注获取成本(标注有效数据 5W+)。
算法成果目前该算法已在内部上线使用。
1) 技术指标

2) 效果展示

除了实时通讯场景,我们利用人像分割算法在互动娱乐场景也进行了一些尝试,例如照片换背景,效果如下图所示。

「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。
作者: CloudImagine, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3967638.html
版权声明:本文为博主原创,未经本人允许,禁止转载!





 /4
/4 






文章评论(0条评论)
登录后参与讨论