近年来,大数据行业的蓬勃发展除了来自软件层的持续迭代与创新,更有赖于计算机硬件环境的持续优化,尤其是在芯片与操作系统国产化的大趋势下,硬件升级带来的性能提升、成本降低、并行处理能力优化、存储与网络优化、安全风险管控等均为数据引擎的发展提供了阶梯式进步的空间。
在奇点云2024年版《OLAP数据库引擎选型白皮书》中,中科驭数联合奇点云针对Spark+Hive这类大数据计算场景下的主力引擎,测评DPU环境下对比CPU环境下的性能提升效果。特此节选该章节内容,与大家共享。
DPU概述
什么是DPU?为什么要关注DPU?
DPU(Data Processing Unit)是以数据为中心构造的专用处理器,采用软件定义技术路线支撑基础设施层资源虚拟化,支持存储、安全、服务质量管理等基础设施层服务。
提到DPU,2020年英伟达CEO黄仁勋在其GTC大会上的一句话引起业界高度关注:“DPU 将成为未来计算的三大支柱之一,未来的数据中心标配是“ CPU + DPU + GPU”。
NVIDIA GTC 2020(英伟达2020年GPU技术大会)上,其CEO黄仁勋的一句话引起了业界高度关注:“DPU 将成为未来计算的三大支柱之一,未来的数据中心标配是CPU + DPU + GPU。”
DPU的设计思路,是将“CPU处理效率低下、GPU处理不了”的负载卸载到专用DPU,提升整个计算系统的效率、降低整体系统的总体拥有成本(TCO,Total Cost of Ownership),以实现底层基础设施的“降本增效”。DPU最直接的作用是作为CPU的卸载引擎,接管网络虚拟化、硬件资源池化等基础设施层服务,释放CPU的算力到上层应用。
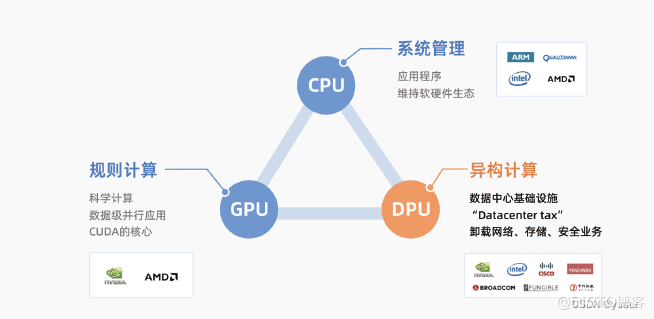
对比CPU、GPU与DPU:
CPU面向应用程序,负责进行系统管理维持软硬件生态;
GPU面向科学计算,负责进行规则计算支持数据级并行应用;
DPU面向数据中心基础设施,负责进行异构计算支撑卸载网络、存储、安全业务等降低“Datacenter Tax”。
图:CPU、GPU、DPU算力生态(相关厂商为不完全列举)
图源:《中科驭数DPU技术白皮书》
DPU与CPU最大的区别是,DPU是IO密集型,而GPU是计算密集型。CPU通过间接手段来支持网络IO,其前端总线带宽也主要匹配主存(特别是DDR)的带宽,而非网络IO的带宽;DPU的IO带宽则几乎可以与网络带宽等同,其在支持强IO基础上具备强算力。
DPU的出现并非偶然,而是IT产业发展到一定阶段的必然选择。随着AI、5G等技术的发展,端、边、云各处的计算节点暴露在了剧增的数据量下,CPU的性能增长率与数据量增长率出现了“剪刀差”现象。同时,以数据为中心的新兴应用对数据的实时处理提出了越来越高的要求。DPU则可以在数据流上就近计算,实现数据处理的低时延和高吞吐,更具灵活性与效率。
业内越来越多观点认为,CPU+DPU的异构计算解决方案将是应对大数据性能瓶颈的新趋势,DPU也越来越得到数据中心运营商和大数据软件厂商的关注。
因此,本书选择“Spark+Hive”(大数据计算场景下的主力引擎)为代表,进行了DPU与CPU环境下的性能对比测评,为读者提供参考。
DPU如何实现加速?有哪些应用场景?
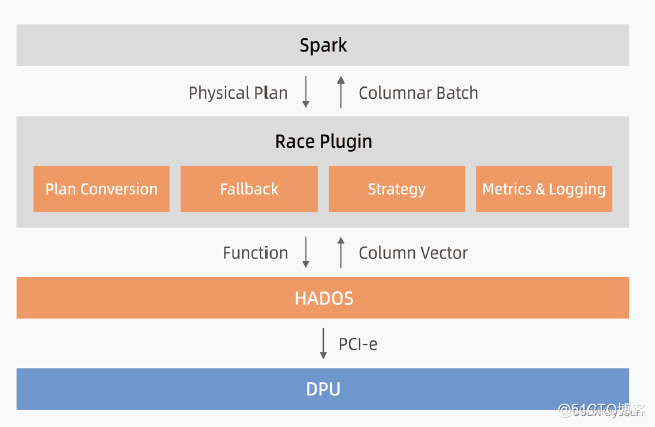
针对Spark+Hive的大数据计算场景测试,本次测评的技术方案中除了引入中科驭数Spark-Race解决方案中最底层的DPU硬件(面向数据中心的专用处理器)、HADOS平台层(异构软件开发平台)外,也包含专门针对Spark的DPU加速层,其最核心的能力就是修改查询计划树。简单来讲就是通过 Spark Plugin的机制(作为Spark插件),把 Spark 查询计划拦截并下发给 DPU来执行,跳过原生 Spark 不高效的执行路径。整体的执行框架仍沿用 Spark 既有实现,包括消费接口、资源和执行调度、查询计划优化、上下游集成等,用户可以直接使用已有的代码,“无痛”享受DPU带来的性能提升。
图:中科驭数Spark-Race技术方案架构图
图源:《中科驭数CONFLUX-2200D技术方案和测试总结报告》
中科驭数介绍,DPU环境对超大业务表或宽表的join联合查询场景有突破性的优化效果。例如,对于连续join 4张100万条数据的维表,在CPU模式下全部time out(3600s),而DPU模式下只需数百秒即可查询出结果,计算加速比达到8.4倍。在应对涉及复杂SQL多表查询的挑战时,Spark-Race 2.0的优势也尤为突出。
因此,本书就“Spark+Hive”引擎(包括高复杂度的数据查询任务场景),进行了测试和检验。
DPU测试方案说明
测评方案概述
DPU测评方案仍沿用引擎测评模型2.0,在相同环境与资源配置前提下,分别在底层硬件资源开启DPU模型与不开启DPU模式下,执行本次测评SQL用例三次,采集SQL执行耗时、整机CPU、整机内存消耗等核心数据进行对比实验。
在测试过程中,除底层硬件资源开启/关闭DPU加速功能外,保持DPU和CPU对比实验环境的主机与网络环境一致,大数据计算引擎Hive、Yarn、Spark配置一致,测评工具(即模型2.0)一致,测试表与数据一致。
环境参数说明
中科驭数DPU性能测试结果
经过对比测试,在数据计算和处理场景中,DPU环境相较于CPU环境下的查询性能提升能达到50%-60%,且DPU环境下整体较CPU环境的峰值性能资源有优化,整机CPU峰值降低24%,内存消耗降低50%且波动更平稳。
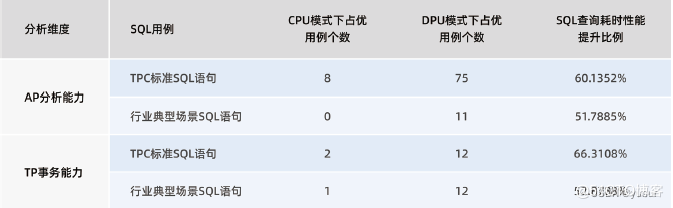
在数据处理相关的场景,如TPC-DS标准SQL和行业典型场景SQL的测试用例下,DPU模式下占优的用例数明显高于CPU模式下占优的用例数,且从相同SQL用例的查询耗时数据来看,DPU模式下的耗时相较于CPU模式有50%-60%的提升。
注:性能对比计算公式,针对执行结果数据(CPU-DPU)/CPU
表:DPU模式对比CPU模式下SQL查询耗时性能结果表
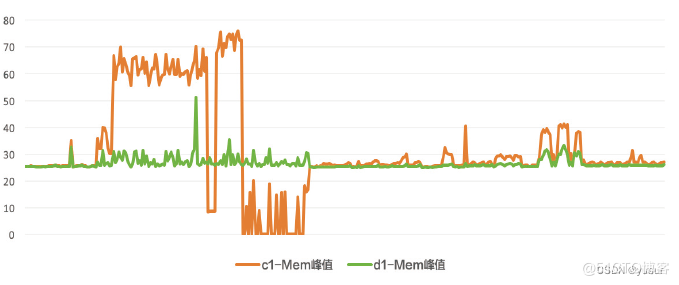
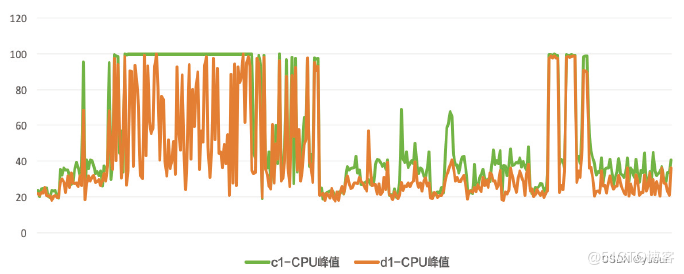
从测试过程中采集到的整机CPU峰值数据来看,DPU环境下的整机CPU峰值高位比CPU环境下整机CPU峰值高位低24%左右,配合大数据平台完善的调度体系,可以实现更多的任务并行。
图:DPU模式对比CPU模式下CPU峰值表现
测试过程中采集到的内存消耗数据来看,DPU环境在测试执行过程中内存消耗走势更平稳,且整体峰值相较于CPU环境更低。从性能优化的角度来看,DPU环境相较于CPU环境降低50%左右的内存配置,即本次实验DPU环境内存可从128G降为64G。
图:DPU模式对比CPU模式下内存峰值表现
附录:测评环境与数据详细说明
以下针对本次测评的测试环境、资源参数、测试数据集进行说明:
测试环境 | 操作系统:CentOS 7.9芯片:Intel Cascade Lake 3.0 16C/64G |
机器资源配置 | 16C/64G/3T物理机2台16C/64G/6T物理机1台 |
数据规模 | 总数据量2.8T,213亿行数据 |
数据类型 | 业内标准测试数据:400G • TPC-DS:300G。数据总量22亿5873万,最大表数据量8亿6400万 • PC-H:100G。数据总量约8亿6604万,最大表数据6亿条 各行业构造数据:合计138亿5111万 • 泛零售:最大表数据10亿条,场景合集数据条数:24亿8284万 • 金融:最大表数据10亿条,26亿300万条 • 制造:最大表数据10亿条,75亿300万条 • 政企:最大表数据3亿条,7亿6172万条 • 地产:最大表数据5亿条,5亿100万
标准业务表构造数据:合计43亿2440万 • 业务表:最大表数据20亿条 • 宽表:3亿条,130+维度
|




 /1
/1 







文章评论(0条评论)
登录后参与讨论