
OpenEBS是一个广受欢迎的开源云原生存储解决方案,托管于CNCF(云原生计算基金会)之下,旨在通过扩展Kubernetes的能力,为有状态应用提供灵活的持久性存储。Mayastor是OpenEBS项目中的关键存储引擎,它以其高性能、耐久性和易于管理的特点,为云原生应用提供了理想的存储解决方案。Mayastor的特点包括:
基于NVMe-oF:Mayastor利用NVMe-oF协议,这是一种基于网络的NVMe访问方法,允许NVMe设备通过以太网或其他网络结构进行远程访问,这有助于提高存储系统的性能和可扩展性。
支持多种设备类型:虽然Mayastor优化了NVMe-oF的使用,但它并不要求必须使用NVMe设备或云卷,也可以与其他类型的存储设备配合使用。
与Kubernetes集成:Mayastor作为OpenEBS的一部分,与Kubernetes紧密集成,允许开发人员和运维人员使用Kubernetes的原生工具(如kubectl)来管理和监控存储资源。
Mayastor适用于需要高性能和耐久性存储解决方案的云原生应用场景,特别是在边缘计算、大数据分析、流媒体处理等领域。它可以帮助开发人员构建高可用性和可扩展性的有状态应用,同时降低存储系统的复杂性和成本。通过利用NVMe-oF协议和最新一代固态存储设备的性能能力,Mayastor能够提供低开销的存储抽象,满足有状态应用对持久性存储的需求。
当前Mayastor只提供了NVMe over TCP技术实现数据存储服务,不支持NVMe over RDMA技术,这就不能充分挖掘NVMe SSD盘的性能优势,主要问题和挑战包括:
1、性能瓶颈:
Mayastor依赖于TCP来实现NVMe SSD的数据传输,这意味着它不可避免地继承了TCP的性能瓶颈。TCP的头部开销和拥塞控制机制限制了数据传输的有效速率,尤其是在处理大量小数据包时更为明显。对于需要高速访问和处理的NVMe SSD来说,这种限制可能显著影响Mayastor的整体性能。
2、延迟敏感应用的挑战:
对于那些对延迟要求极高的应用(如高频交易、实时数据分析等),Mayastor当前的TCP实现可能无法提供足够的低延迟保证。TCP的延迟增加和抖动问题可能导致这些应用的性能下降,从而影响业务决策的时效性和准确性。
3、资源消耗:
在高并发场景下,Mayastor处理TCP数据包时涉及的频繁中断和上下文切换会显著增加CPU的负载。这不仅会降低系统整体的计算效率,还可能影响Mayastor处理其他存储请求的能力,导致整体性能下降。
本方案是基于驭云ycloud-csi架构,将Mayastor整合进来,通过Gateway提供数据通路的RDMA加速,提高IO性能。在Host侧通过DPU卸载,可以进一步解放工作节点上的CPU负载,获取更好的应用性能。整体架构如下所示(标绿和标蓝部分是自研组件):

本方案将不同的组件分别部署在不同的node,主要包含:
本方案主要由ycloud-csi、RDMA Gateway和Mayastor后端存储三个部分组成,下面将对这三个部分进行介绍。
通过ycloud-csi架构可以接入第三方的存储,让第三方存储很方便的使用DPU的能力。其包括ycloud-csi-controller、ycloud-csi-node-host和ycloud-csi-node-dpu,主要职责是为K8s的负载提供不同的存储能力。
2.2.1.1. Ycloud-csi-controller
Ycloud-csi-controller主要实现以下两类功能:
2.2.1.2. Ycloud-csi-node
Ycloud-csi-node使用插件系统,对接不同的第三方存储。 ycloud-csi-node按node角色分为ycloud-csi-node-dpu、ycloud-csi-node-host和ycloud-csi-node-default,不同角色的csi-node功能不同,下面分别加以说明:
RDMA Gateway是基于SPDK开发的存储服务,可以部署在io-engine相同的节点上,负责连接本地Mayastor的target,对外提供NVMe oF存储服务。
后端存储采用Mayastor,管理不同节点上的硬盘存储。
用户的App运行在POD中。为了能存放持久的数据,需要给POD挂载存储卷。在启动POD之前,可以先创建好PVC,以供后面使用。创建PVC的过程如下:
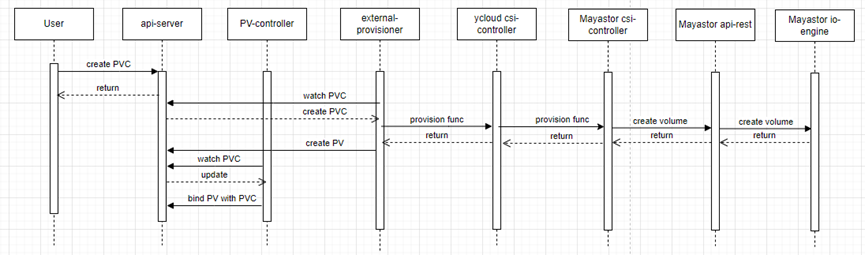
图中除了包含上一章节介绍的组件外,还有两个k8s系统提供的用于方便对接csi的组件:
在POD的描述yaml文件里,会指定使用的存储卷PVC。创建POD后,K8s的调度器会选择一个合适的节点来启动POD,然后attacher会把PVC连接到指定节点上,csi-node会把存储卷挂载到POD中。
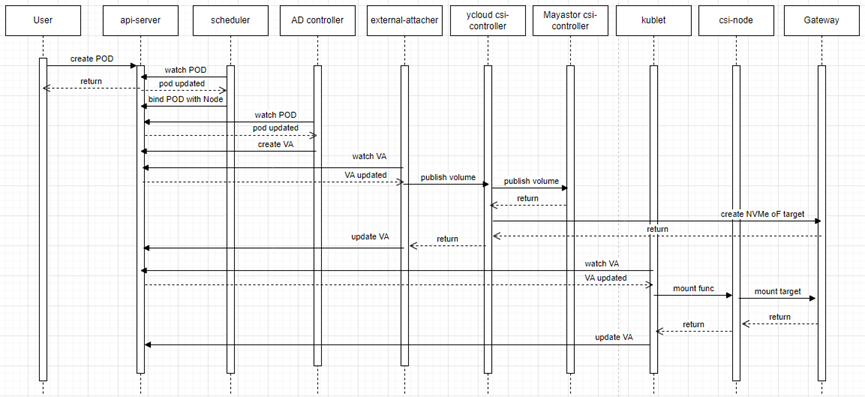
图中包含两个k8s系统提供的用于对接csi的组件:
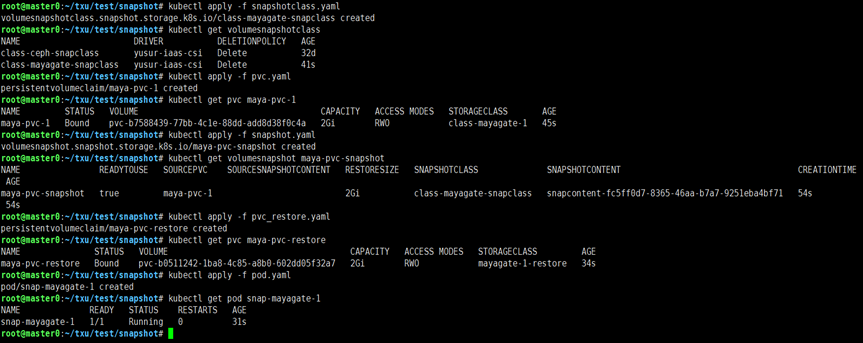
通过相应的 yaml 描述文件,可以完成创建PVC,删除PVC,创建/删除snapshot,在POD中挂载PVC,并验证操作成功。经验证可知,Mayastor原生支持的操作,在添加Gateway之后,仍可以支持。
操作截图如下:
运行kubectl describe pod snap-mayagate-1命令查看pod,结果如下:
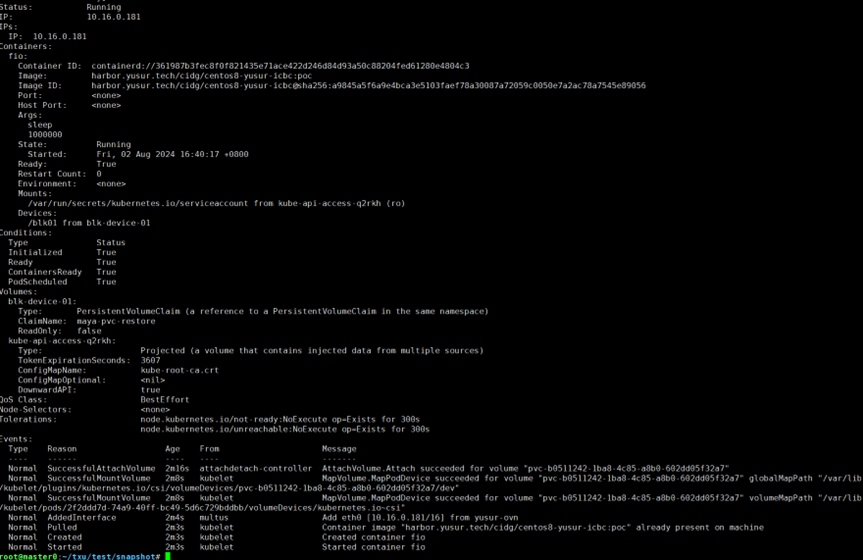
可以连进pod进行简单的写操作测试:
本方案基于单节点Mayastor创建单副本存储池,在以下测试场景与传统Mayastor方案进行对比:
(1) 随机写延迟分析
随机写延迟的测试结果,如下图所示:
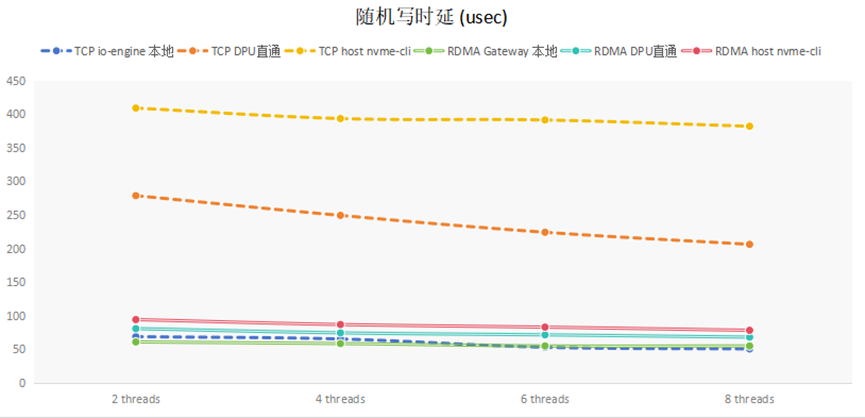
对比TCP和RDMA在不同地方的采样,可知,io-engine所在节点本地访问延迟较小,在另外一个节点访问,TCP延迟增加了一个数量级,而RDMA延迟增加较小。
(2)顺序写带宽分析
顺序写带宽的测试结果,如下图所示:
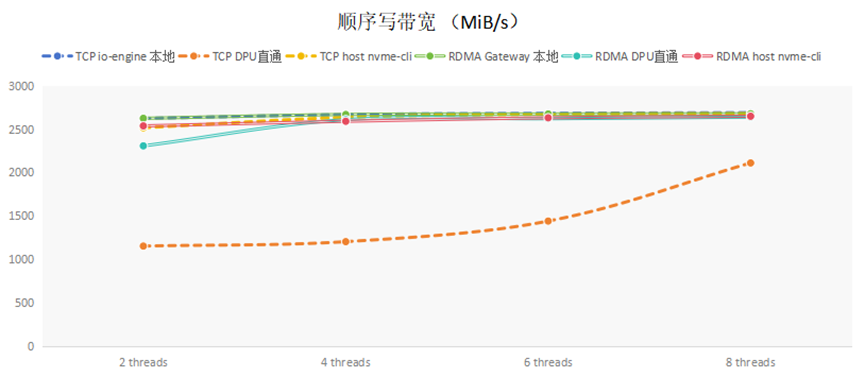
通过在本地直接对于NVMe SSD硬盘测试,发现SSD可支持带宽大约2680MiB/s左右。从表中可以看到,使用nvme cli连接,无论是TCP还是RDMA,都可以接近后端存储支持的最大带宽。单独看DPU直通的数据,RDMA的性能远远超过TCP的性能。这是因为TCP由软件栈处理,需要消耗大量CPU资源,DPU内仅有4core,CPU资源不足造成的。
(3) 随机写IOPS分析
随机写IOPS的测试结果,如下图所示:
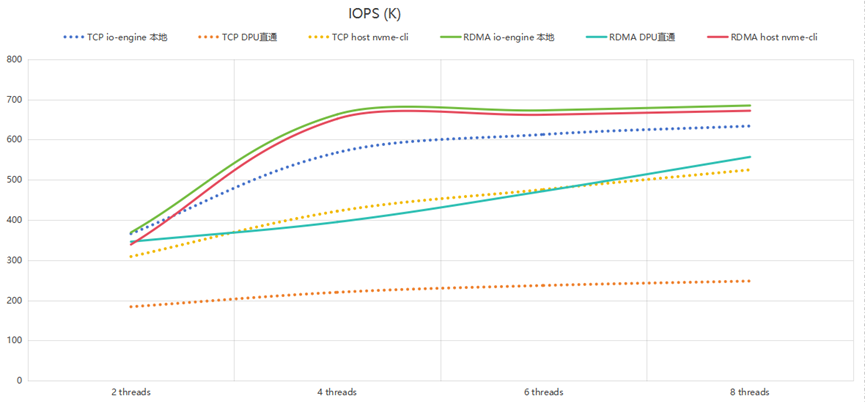
可以看到:
1. RDMA的io-engine本地和host nvme-cli两个测试位置曲线接近,说明RDMA是完全卸载到硬件处理,性能好;
2. TCP的两种方式性能有差别,特别是TCP DPU直通方式的上限是200kiops,说明瓶颈是在DPU的CPU上。
另外把Host cli访问的数据单独拿出来,用这两行单独作图,如下:
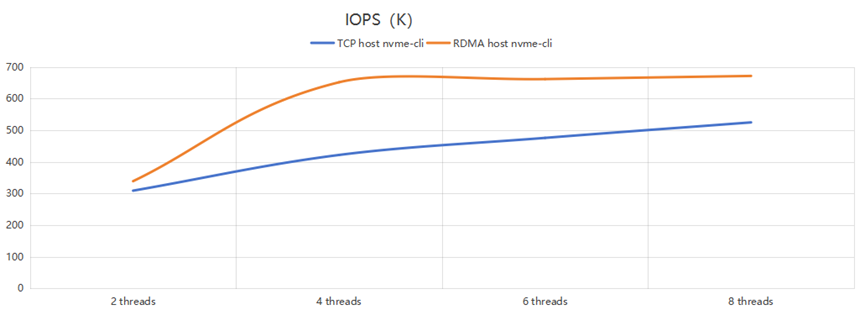
可以看到,当io-engine thread个数为4时,RDMA Gateway已经基本可以压满后端存储;再增加threads个数影响不大。但TCP直连时,性能还是会随着threads增加而增大。这说明RDMA在相对较低的资源条件下就可以达到较高的性能,其加速效果较好。
(4)随机读IOPS分析
随机读IOPS的测试结果,如下图所示:
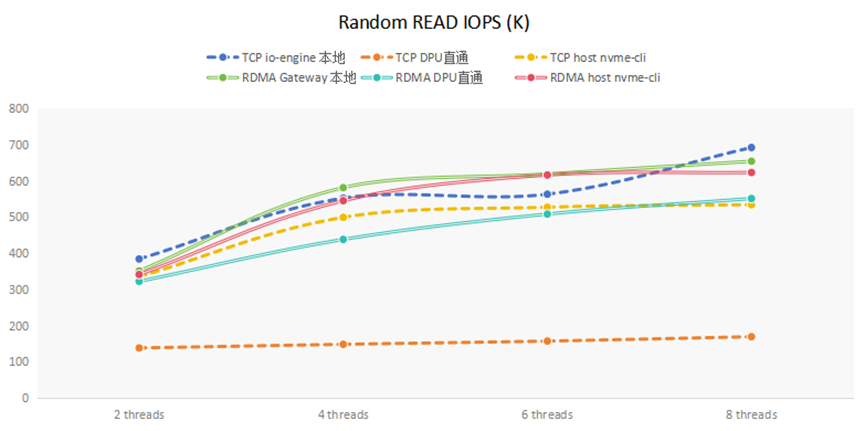
可以看到TCP DPU直通方式随机读的上限是150kiops,说明瓶颈是在DPU的CPU上。
另外把Host cli访问的数据单独拿出来,用这两行单独作图,如下:
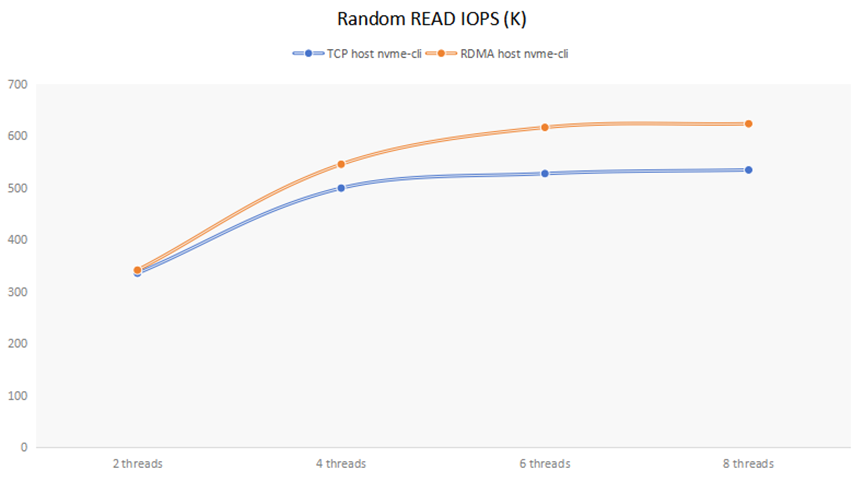
可以看到,当io-engine thread个数为2时,Mayastor TCP方式与RDMA Gateway相差不大,说明瓶颈在于存储后端;当io-engine thread个数大于等于4时,RDMA Gateway的性能要比TCP方式大约提高20%左右。
对于30%写的混合读写方式,由于读操作占主体,跟上面读操作的结果类似,在Host cli情形下,RDMA Gateway的性能要比TCP方式大约提高20%左右。
(5) Host侧CPU使用分析
在fio测试过程中,通过脚本记录Host上top命令的输出信息,获取CPU的使用信息。
下图是用Host cli连接时使用CPU的截图记录, TCP协议与RDMA协议的对比。(测试中Mayastor io-engine 采用8 core。)
测试命令是:
| fio -direct=1 -iodepth=64 -rw=randwrite -ioengine=libaio -size=100G -bs=4k -numjobs=16 -runtime=300 -group_reporting -filename=/dev/filename -name=Rand_Write_Testing |
依次对于三个不同的挂接设备进行测试:/dev/nvme2n1是Host侧TCP cli;/dev/nvme3n1是Host侧RDMA cli;/dev/nvme0n26是DPU侧RDMA直通。
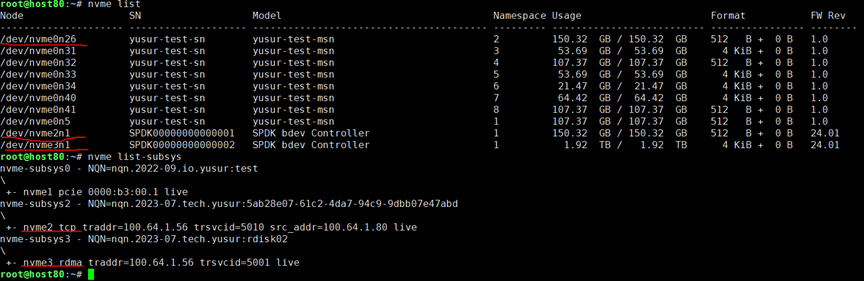
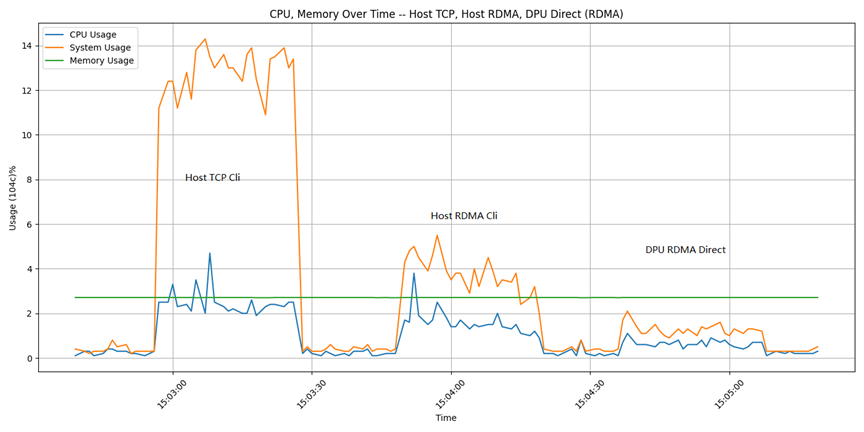
在3个挂载盘上分别做fio测试的IOPS结果分别是:655k,684k,646k。可以看到测试出的性能结果相差不大。上图是测试过程中通过脚本记录的CPU使用情况。可以看到,相对于TCP,使用RDMA协议可以节省大量的CPU。
1、显著提升性能:
通过前面测试数据可以看到,在DPU直通连入的场景下,本方案比原生的Mayastor方案随机写IOPS性能提升40%左右,随机读IOPS性能提升20%左右。在DPU直通的场景下,TCP方式延约200毫秒,RDMA方式约80毫秒,本方案可以减少60%左右的时延。这是因为本方案充分利用了RDMA的超低延迟和高性能特性。RDMA的零拷贝和绕过CPU的传输方式极大地减少数据传输过程中的延迟和CPU消耗,使Mayastor能够更高效地处理NVMe SSD的读写请求。
2、优化资源利用:
通过前面测试数据可以看到,采用RDMA的方式连接后端存储,相对于TCP方式可以节省50%左右的Host cpu。本方案通过NVMe over RDMA减少Mayastor对CPU和内存的占用,使系统资源能够更多地用于其他计算任务,这有助于提升Mayastor的整体稳定性和可靠性,同时降低运营成本。
3、增强可扩展性和灵活性:
RDMA技术还提供了更好的可扩展性和灵活性。随着数据中心规模的扩大和存储需求的增长,Mayastor可以通过支持NVMe over RDMA来更轻松地应对这些挑战。RDMA的远程直接内存访问特性使得跨节点的数据传输更加高效和可靠,有助于构建更强大的分布式存储系统。
4、支持更多应用场景:
有了NVMe over RDMA的支持,Mayastor将能够更好地满足那些对性能有极高要求的应用场景。无论是高频交易、实时数据分析还是大规模数据库事务处理,Mayastor都将能够提供更加稳定和高效的数据存储服务。
综上所述,从Mayastor影响的角度来看,NVMe over RDMA技术相较于TCP在性能、延迟和资源消耗方面均展现出显著优势。对于追求极致性能的数据中心和应用场景来说,Mayastor未来能够支持NVMe over RDMA将是一个重要的里程碑,有助于进一步提升其市场竞争力和用户体验。
本方案来自于中科驭数软件研发团队,团队核心由一群在云计算、数据中心架构、高性能计算领域深耕多年的业界资深架构师和技术专家组成,不仅拥有丰富的实战经验,还对行业趋势具备敏锐的洞察力,该团队致力于探索、设计、开发、推广可落地的高性能云计算解决方案,帮助最终客户加速数字化转型,提升业务效能,同时降低运营成本。
作者: Yusur_Tech, 来源:面包板社区
链接: https://mbb.eet-china.com/blog/uid-me-3991230.html
版权声明:本文为博主原创,未经本人允许,禁止转载!




 /4
/4 






文章评论(0条评论)
登录后参与讨论