
风风雨雨二十载,多少bug在心间。
代码编译不通过,急得抓耳直挠腮。
回想当年恩师讲,基础知道全忘干。
忙里偷闲回首看,权当引玉的抛转。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
矩阵按键组成结构如下
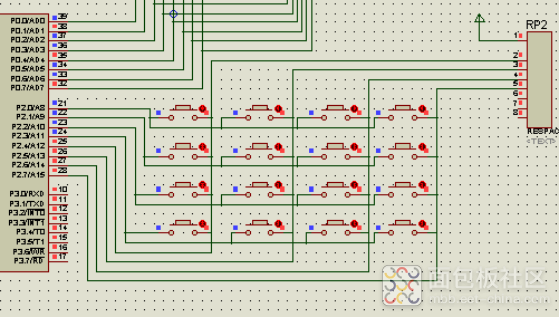
键盘中按键数量较多时,为了减少I/O口的占用,通常将按键排列成矩阵的形式。
按键的两种识别方法
若所有输入端均为高电平,则代表无键按下。假定行线输出为低电平,若有键按下,则输入为0,故,可通过读输入的状态可知是否有键按下。
<1>"行扫描法"。
又称逐行(或列)扫描查询法。
1、判断有无按键按下。首先行线置0,然后检测列线的状态。若某列为低,则有键按下;若列线均为高,则无键按下。
2、判断键所在位置。方法:将行线分别置0,即某行线为0时,其它行线为1。确定某行为0后,再逐行检测各列线的电平状态。若某列为0,则该列线与置为0的行线交叉处的按键即为按下的按键。
<2>"高低电平翻转法"。
首先假定P2高四位为1,低四位为0。若有按键按下,则高四位中会有一个1翻转为0,低四位不会变,此时即可确定被按下的键的列位置。
然后假定P2高四位为0,低四位为1。若有按键按下,则低四位中会有一个1翻转为0,高四位不会变,此时即可确定被按下的键的行位置。
上述两条即可确定被按下的键的位置。
设计如下:
1、电路图
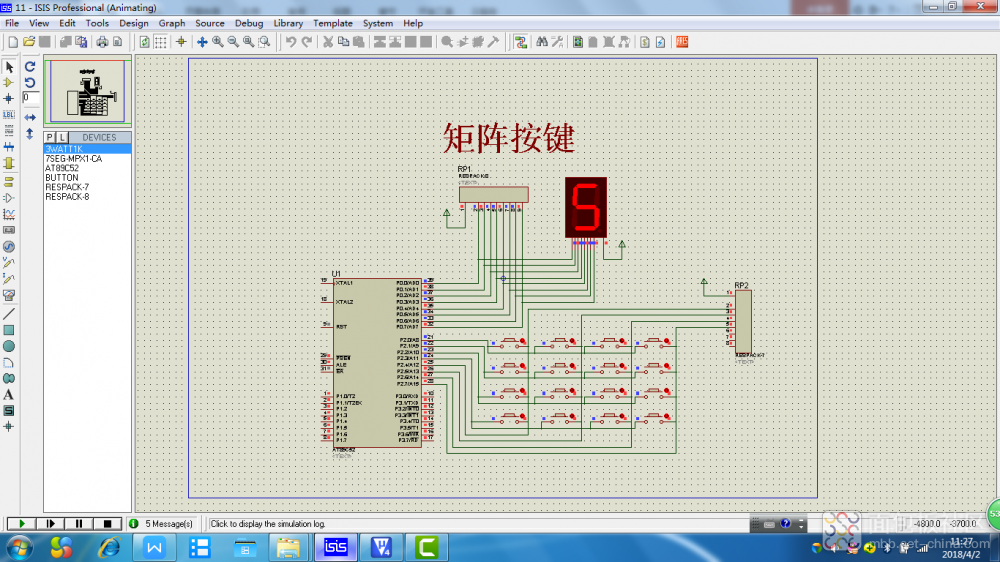
2、程序设计
#include
#define uchar unsigned char
uchar code keycode[16]={0xee,0xde,0xbe,0x7e,
0xed,0xdd,0xbd,0x7d,
0xeb,0xdb,0xbb,0x7b,
0xe7,0xd7,0xb7,0x77};
//输入是列,输出是行
uchar code lie[4]={0xfe,0xfd,0xfb,0xf7};//高四位列低四位行,列扫描:首先往行里置0,然后列扫描
uchar code shuma[]={0xC0,0xF9,0xA4,0xB0,
0x99,0x92,0x82,0xF8,0x80,0x90,0x88,0x83
,0xC6,0xA1,0x86,0x8E,0xBF,0xff};
uchar k=16;
void delayus(uchar t)
{
while(t--);
}
uchar keyscan(void)
{
uchar key,i;
P2=0xf0;
if(P2!=0xf0)
for(i=0;i<4;i++)
{
P2=lie;
if(P2!=lie)
{
delayus(30);
key=P2;
if(key!=lie)
{
while(P2!=lie);
return(key);
}
}
}
}
void bj(void)
{
uchar i,j;
j=keyscan();
for(i=0;i<16;i++)
{
if(keycode==j)
k=i;
}
}
void display()
{
P0=shuma[k];
}
void main()
{
while(1)
{
bj();
display();
}
}




 /4
/4 






文章评论(0条评论)
登录后参与讨论