
定时器在操作系统中起到了举足轻重的作用。在做IO操作时,需要超时机制保证任务不处于无休止的等待状态;在延时处理时,可以通过“闹表”进行相对准点的唤醒操作。在多任务操作系统中,定时器是一种非常常用的资源。
对于熟悉硬件的工程师,定时器一般是芯片中的硬件定时器资源,实际上在操作系统中指的定时器资源并非局限于硬件资源,更重要的是软件定时器资源。硬件定时器资源通常实现操作系统的心跳,在uc/os中心跳频率默认值为200Hz,也就是5ms产生一次操作系统心跳。软件定时器是在操作系统心跳的基础上实现的。
下面对Linux中的定时器实现算法作详细分析。
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
Linux中的定时器实现有点意思,在定时器较多的情况下实现效率较高,并且该算法思想可以在其它嵌入式系统中得以应用。
定时器实现的核心思想是采用了多级hash链表,并且每级hash的长度都不一样,多级hash链表可以类比为秒、分、时、天、月,每级的时间跨度都不一样。Linux中实现的五级hash链表关系如下图所示:

如上图所示为5级hash链表,V1为最低层的hash链表,V5为最顶层的hash链表。V1~V5 hash table的每一项为一条定时器链表,新添加的定时器会通过expire(定时时间值)和base->timer_jiffies(当前定时值)的差值expire_time来索引应该挂接到哪一层hash table中,并且索引到hash table中的具体项,然后将新增加的定时器加入到该项的timer list中。hash长度从V1到V5变得越来越大。V1的hash长度为1个jiffies,也就是说V1的hash table每一项为同一jiffies的定时器链表;V5的hash长度为<?xml:namespace prefix = st1 ns = "urn:schemas-microsoft-com:office:smarttags" />64M jiffies,也就是hash table的每一项会链接连续64M jiffies定时长度的timer。不同层次的hash table具有不同的hash长度,离当前时间点越远的timer位于hash长度越长的table中,因为这些定时器还需要等待较长时间才能得以处理,所以可以采用大块分类的方法,离当前时间点越近的timer需要细粒度的切分,因为jiffies每变化一次都需要处理timer,所以最低层的table按一个jiffies进行切分。随着时间点的后移,不断的对最底层的hash table进行处理,并且通过当前时间点索引上层hash table,将定时器分配到下几级的hash table中。每个hash table与定时器之间的关系如下图所示。
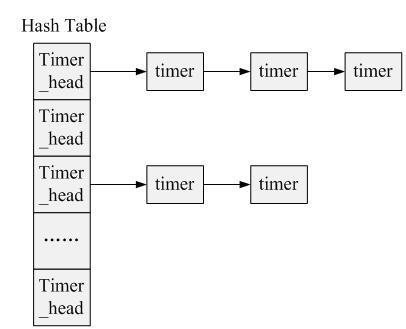
Linux中描述多级hash table的数据结构如下:
struct tvec_t_base_s {
spinlock_t lock; /* 多级hash table自旋锁 */
struct timer_list *running_timer; /* 当前运行的定时器 */
unsigned long timer_jiffies; /* 当前运行的jiffies */
tvec_root_t tv1; /* V1 hash table */
tvec_t tv2; /* V2 hash table */
tvec_t tv3; /* V3 hash table */
tvec_t tv4; /* V4 hash table */
tvec_t tv5; /* V5 hash table */
} ____cacheline_aligned_in_smp;
添加一个定时器需要进行hash table操作,根据定时值索引具体的定时器list,该算法描述如下:
1、 通过定时器的expire(定时时间点,以jiffies为基本度量单位)和当前的时间点(timer_jiffies)计算得到定时间隔idx。
2、 如果idx小于TVR_SIZE(通常为256个jiffies),那么可以将定时器加入到V1 hash table中,通过expire计算得到V1 hash table的索引块,然后加入到该块所对应的定时器链表中。
3、 如果idx位于V2~V5的hash table中,那么同样通过expire,根据(expire >> (TVR_BITS + N * TVN_BITS)) & TVN_MASK得到hash table中的块索引号,然后加入到该块所对应的定时器链表中。
当硬件定时器计完一个jiffies之后,会引起硬件中断,在硬件中断服务程序中会触发软中断,在定时器软中断服务程序中会调用__run_timers()完成定时器多级hash table的处理,并且处理定时时间到的所有timer。__run_timers算法实现描述如下:
1、 根据当前jiffes和base->timer_jiffies循环判断多级hash table扫描条件,如果满足条件,那么继续(2),否则退出循环。
2、 通过base->timer_jiffies计算得到V1 table中需要处理的索引项。并且将索引高层hash table中的具体项,将该项中的timer分散到低层table中去。
3、 增加base->timer_jiffies值,提取出V1中索引得到的定时器链表。
4、 如果该定时器链表不为空,那么依次处理链表中的定时器,处理过程为调用定时器的处理函数timer->function。
5、 循环至(1)。
个人认为Linux中软定时器的实现还是非常漂亮的,特别对于定时器应用较多的场合效率非常高。其通过hash索引的方法避免了定时器链表的反复查询,并且其通过多级链表分类对待离当前时间点不同的定时器,离当前时间点较远的定时器可以在一个时间区间内共享一个定时器链表,离当前时间点较近的定时器只能是相同的定时时间点才能共享一个定时器链表。在uc/os嵌入式操作系统中,延时定时器是通过扫描、递减每个任务的当前定时值实现的,所以在硬件定时器的中断服务程序中不断扫描任务链,这样的做法可扩展性很差,效率较低。当定时的任务一多,中断服务程序就忙不过来了,成为系统瓶颈,甚至会影响心跳频率的选择。相比而言,Linux的定时器实现漂亮的多。但是,Linux的定时器实现会占用一定量的内存资源,一般来说,所有定时器链表为空时还需要占用2K的存储空间,所以,对于一些对内存资源非常在意的小型应用而言,需要慎重考虑这个算法。




 /4
/4 






文章评论(0条评论)
登录后参与讨论