
专题三:乘法器(一)
乘法运算在数字信号处理中也是比较常用,如常系数FIR中需要输入数据与FIR系数进行乘法运算。在FPGA实现乘法时可选择采用逻辑实现,也可使用硬资源,如Xilinx FPGA中的DSP48。相比于逻辑实现的乘法器,采用DSP48实现的乘法器速度较块,但是个数有限,如果在DSP48资源比较紧缺时,则只能采用逻辑实现乘法器。
首先介绍一下逻辑实现乘法器的方法,最常用的是移位相加法,基于此方法本文介绍全并行结构和半并行结构的乘法器。
1. 全并行结构
如图1所示为两个16位无符号数a、b的全并行乘法器结构。
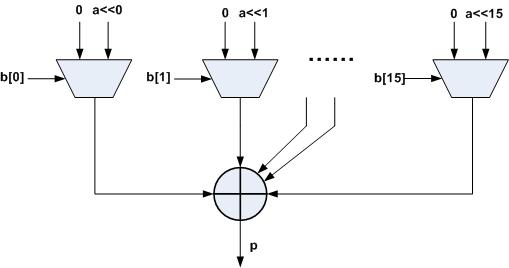
图1
全并行结构乘法器并行输入数据a、b,直接进行移位并且累加,所有操作都在一个时钟周期完成,输出的数据速率可以与输入数据的相同,并且输入与输出只有一个时钟周期的延时,Verilog HDL代码如下:
module multiply_lut_FP
(
input clk,
input rst,
input [15:0] a,
input [15:0] b,
output reg [31:0] p
);
//one path
reg [15:0] a_in,b_in;
always@(posedge clk)
if(rst)
begin
a_in<=16'd0;
b_in<=16'd0;
end
else
begin
a_in<=a;
b_in<=b;
end
wire [31:0] p_tmp[0:15];
generate
genvar i;
for(i=0;i<16;i=i+1)
begin:bit_mult
assign p_tmp = (b_in==1'b1) ? ({16'd0,a_in})<<i : 32'd0;
end
endgenerate
always@(posedge clk)
if(rst)
p<=32'd0;
else
p<= p_tmp[0] + p_tmp[1] + p_tmp[2] + p_tmp[3] +
p_tmp[4] + p_tmp[5] + p_tmp[6] + p_tmp[7] +
p_tmp[8] + p_tmp[9] + p_tmp[10]+ p_tmp[11]+
p_tmp[12]+ p_tmp[13]+ p_tmp[14]+ p_tmp[15];
endmodule
通过XST综合报告如下:
Number of Slice Registers: 64
Number of Slice LUTs: 598
Minimum period: 5.304ns (Maximum Frequency: 188.523MHz)
以上报告中的Fmax的结果不是很理想,在无线通信数字中频中数据速率一般都需要达到200M以上,因此需要对此全并行结构乘法器做结构优化,可采用加入流水线级,分隔其中的组合逻辑,如图2所示,分了两级流水线结构,第一级中判断b中比特位、a移位和1个加法操作,第二级流水线中有4个加法操作,Verilog HDL代码如下:
module multiply_lut_FP
(
input clk,
input rst,
input [15:0] a,
input [15:0] b,
output reg [31:0] p
);
//pipeline
reg [15:0] a_in,b_in;
always@(posedge clk)
if(rst)
begin
a_in<=16'd0;
b_in<=16'd0;
end
else
begin
a_in<=a;
b_in<=b;
end
wire [31:0] p_tmp[0:15];
reg [31:0] p_tmp_d[0:7];
generate
genvar i;
for(i=0;i<16;i=i+1)
begin:bit_mult
assign p_tmp = (b_in==1'b1) ? ({16'd0,a_in})<<i : 32'd0;
end
endgenerate
always@(posedge clk)
if(rst)
begin
p_tmp_d[0]<=32'd0;
p_tmp_d[1]<=32'd0;
p_tmp_d[2]<=32'd0;
p_tmp_d[3]<=32'd0;
p_tmp_d[4]<=32'd0;
p_tmp_d[5]<=32'd0;
p_tmp_d[6]<=32'd0;
p_tmp_d[7]<=32'd0;
end
else
begin
p_tmp_d[0]<=p_tmp[0] + p_tmp[1];
p_tmp_d[1]<=p_tmp[2] + p_tmp[3];
p_tmp_d[2]<=p_tmp[4] + p_tmp[5];
p_tmp_d[3]<=p_tmp[6] + p_tmp[7];
p_tmp_d[4]<=p_tmp[8] + p_tmp[9];
p_tmp_d[5]<=p_tmp[10] + p_tmp[11];
p_tmp_d[6]<=p_tmp[12] + p_tmp[13];
p_tmp_d[7]<=p_tmp[14] + p_tmp[15];
end
always@(posedge clk)
if(rst)
p<=32'd0;
else
p<= p_tmp_d[0] + p_tmp_d[1] + p_tmp_d[2] + p_tmp_d[3] +
p_tmp_d[4] + p_tmp_d[5] + p_tmp_d[6] + p_tmp_d[7];
endmodule
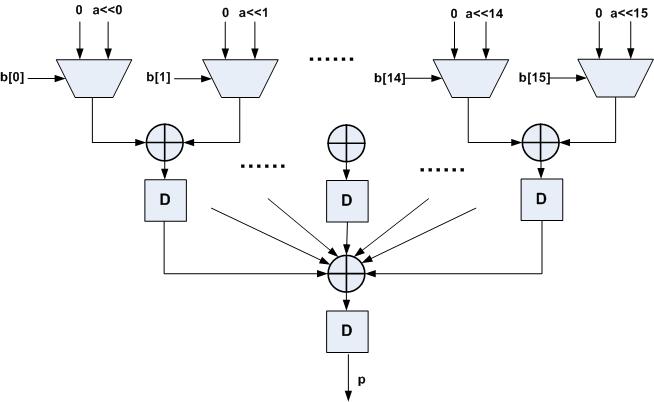
图2
得到综合报告:
Number of Slice Registers: 208
Number of Slice LUTs: 452
Minimum period: 3.828ns (Maximum Frequency: 261.219MHz)
与优化前结构比较,register消耗由64增至208,但是Fmax提高到了261.219MHz,相当于以面积换取速度。而数据速率方面,此结构输出数据速率与输入数据速率仍相同,但是输出数据有2个时钟周期的延时。优化前后结构的仿真如图3所示,其中p_one是优化前输出,p_pip是加入流水线级后的输出,结果验证了如上所述功能。
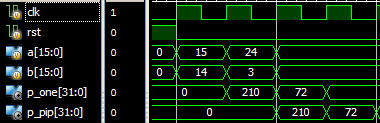
图3
2. 半并行结构
半并行结构乘法器结构如图4所示,a为并行输入,b按比特位串行输入,其中有15级寄存器寄存中间累加数据,因此计算一次半并行乘法需要15个时钟周期的延时。
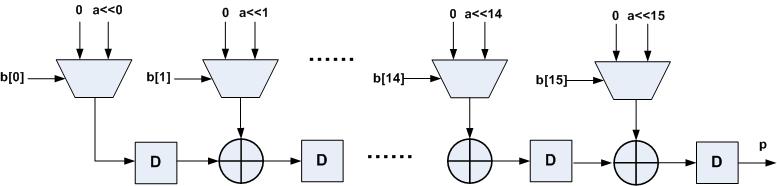
图4
半并行结构乘法器Verilog HDL代码如下:
module multiply_lut_HP(
input clk,
input rst,
input [15:0] a,
input [15:0] b,
output reg [31:0] p,
input ivalid,
output reg ovalid
);
reg [15:0] a_in,b_in;
reg [31:0] p_tmp;
integer cnt;
reg [2:0] cs;
parameter [2:0] IDLE=3'b001,
ST0 =3'b010,
DONE=3'b100;
always@(posedge clk)
if(rst)
begin
ovalid<=1'b0;
a_in<=16'd0;
b_in<=16'd0;
p_tmp<=32'd0;
p<=32'd0;
cs<=IDLE;
end
else
begin
ovalid<=1'b0;
p<=32'd0;
case(cs)
IDLE: begin
p_tmp<=32'd0;
cnt<=0;
if(ivalid)
begin
b_in<=b;
a_in<=a;
cs<=ST0;
end
else
begin
b_in<=16'd0;
a_in<=16'd0;
cs<=IDLE;
end
end
ST0:begin
if(b_in[cnt])
p_tmp<=p_tmp + ({16'd0,a_in}<<cnt);
else
p_tmp<=p_tmp;
if(cnt==15)
begin
cs<=DONE;
cnt<=0;
end
else
begin
cs<=ST0;
cnt<=cnt+1;
end
end
DONE:begin
cs<=IDLE;
ovalid<=1'b1;
p<=p_tmp;
p_tmp<=32'd0;
end
endcase
end
endmodule
综合报告如下:
Number of Slice Registers: 105
Number of Slice LUTs: 117
Minimum period: 2.909ns (Maximum Frequency: 343.716MHz)
分析综合报告,半并行结构乘法器无论资源还是Fmax性能上都优于全并行结构乘法器,但是数据吞吐率不如全并行结构,在此例中出去输入和输出数据的寄存,乘法操作有15个时钟周期的延时,如图5所示为半并行结构乘法器仿真。
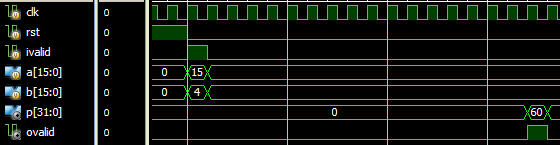
图5



 /3
/3 







用户1857338 2015-10-9 15:35