
 改进的分布式算法解决方案:<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
改进的分布式算法解决方案:<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
如果滤波器的阶数N过大,用前述的方法需要查找表有2的N次方个数据供查找。也就是说,例如对于一个10阶的滤波器来说,建立的查找表就需要2的10次方即查找表内存储1024个数据。这时我们就可以利用部分表并将结果相加,我们吧10阶的表分成两个5阶的分别制作查找表,那么对于一个5阶的查找表只要2的5次方(32)个数据,两个5阶一共只需要64个数据,这相对与1024个数据的查找表而言,节约了相当可观的硬件电路资源。10阶的滤波器尚且如此,那么15阶、20阶……的查找表设计就能节约更多硬件资源了。
这是一种很实用的改进方法,下面我们就用这个方法设计一个6阶的FIR滤波器。它的6阶系数分别为-2,3,1,3,-1,2。
仿真的结果如下:
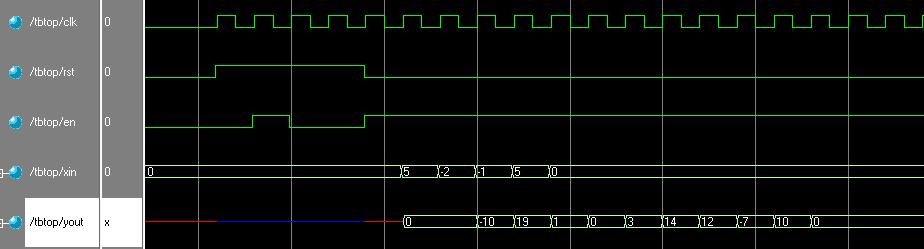
输入激励信号为5,-2,-1,5;经过6阶FIR滤波器后得到的结果应该是:-10,19,1,0,3,14,12。也正是我们仿真得到的输出yout。
<?xml:namespace prefix = v ns = "urn:schemas-microsoft-com:vml" />
Verilog代码:
//顶层模块
module fir_top(clk,rst,en,xin,yout);
input clk;
input rst;
input[3:0] xin;
input en;
output[7:0] yout;
reg[3:0] xreg1,xreg2,xreg3,xreg4,xreg5,xreg6;
reg[7:0] yreg1,yreg2,yreg3,yreg4;
reg[7:0] yout;
wire[3:0] yreg11,yreg12,yreg13,yreg14,yreg21,yreg22,yreg23,yreg24;
always @ (posedge clk) begin
if(rst) begin
xreg1 <= 4'd0;
xreg2 <= 4'd0;
xreg3 <= 4'd0;
xreg4 <= 4'd0;
xreg5 <= 4'd0;
xreg6 <= 4'd0;
yout <= 8'hzz;
end
else if(en) begin
xreg6 <= xreg5;
xreg5 <= xreg4;
xreg4 <= xreg3;
xreg3 <= xreg2;
xreg2 <= xreg1;
xreg1 <= xin;
yreg1 <= {{4{yreg11[3]}},yreg11} + {{4{yreg21[3]}},yreg21};
yreg2 <= {{3{yreg12[3]}},yreg12,1'b0}
+ {{3{yreg22[3]}},yreg22,1'b0};
yreg3 <= {{2{yreg13[3]}},yreg13,2'b00}
+ {{2{yreg23[3]}},yreg23,2'b00};
yreg4 <= ~({yreg14[3],yreg14,3'b000})
+ ~({yreg24[3],yreg24,3'b000}) + 8'd2;
yout <= yreg1 + yreg2 + yreg3 + yreg4;
end
else begin
xreg1 <= 4'd0;
xreg2 <= 4'd0;
xreg3 <= 4'd0;
xreg4 <= 4'd0;
xreg5 <= 4'd0;
xreg6 <= 4'd0;
yout <= 8'hzz;
end
end
find_123 find_11({xreg1[0],xreg2[0],xreg3[0]},yreg11);
find_123 find_12({xreg1[1],xreg2[1],xreg3[1]},yreg12);
find_123 find_13({xreg1[2],xreg2[2],xreg3[2]},yreg13);
find_123 find_14({xreg1[3],xreg2[3],xreg3[3]},yreg14);
find_456 find_21({xreg4[0],xreg5[0],xreg6[0]},yreg21);
find_456 find_22({xreg4[1],xreg5[1],xreg6[1]},yreg22);
find_456 find_23({xreg4[2],xreg5[2],xreg6[2]},yreg23);
find_456 find_24({xreg4[3],xreg5[3],xreg6[3]},yreg24);
endmodule
//头3阶的查找表
module find_123(xin2,yout2);
input[2:0] xin2;
output[3:0] yout2;
reg[3:0] yout2;
always @ (xin2) begin
case (xin2)
3'd0: yout2 <= 4'b0000;
3'd1: yout2 <= 4'b0001;
3'd2: yout2 <= 4'b0011;
3'd3: yout2 <= 4'b0100;
3'd4: yout2 <= 4'b1110;
3'd5: yout2 <= 4'b1111;
3'd6: yout2 <= 4'b0001;
3'd7: yout2 <= 4'b0010;
default: ;
endcase
end
endmodule
//后3阶的查找表
module find_456(xin1,yout1);
input[2:0] xin1;
output[3:0] yout1;
reg[3:0] yout1;
always @ (xin1) begin
case (xin1)
3'd0: yout1 <= 4'b0000;
3'd1: yout1 <= 4'b0010;
3'd2: yout1 <= 4'b1111;
3'd3: yout1 <= 4'b0001;
3'd4: yout1 <= 4'b0011;
3'd5: yout1 <= 4'b0101;
3'd6: yout1 <= 4'b0010;
3'd7: yout1 <= 4'b0100;
default: ;
endcase
end
endmodule
除此以外,在这个实验中,我们还将讨论一个提高速度的问题。在顶层模块中,yout = yreg1 + yreg2 + yreg3 + yreg4,在我们的程序中是已经做过优化的了。而往往有时候,我们会直接将程序写成如下形式:
yout <= {{4{yreg11[3]}},yreg11} + {{4{yreg21[3]}},yreg21}
+ {{3{yreg12[3]}},yreg12,1'b0} + {{3{yreg22[3]}},yreg22,1'b0}
+ {{2{yreg13[3]}},yreg13,2'b00} + {{2{yreg23[3]}},yreg23,2'b00}
+ ~({yreg14[3],yreg14,3'b000}) + ~({yreg24[3],yreg24,3'b000}) + 8'd2;
这样的设计虽然不需要经过yreg1/yreg2/yreg3/yreg4然后再累加,似乎能够提前一个时钟周期输出数据。但是,这样的设计却要求一个时钟周期的时间必须足够大才能够完成这个一个庞大的累加操作。
那么,我们就让综合结果来说话吧。首先,下面是使用后者(未经优化的程序)得出的综合报告:
Maximum frequency (也就是硬件实现允许的最大频率)是80.476MHz。下面让我们再看看优化后的实现报告作一个对比吧。

看出差距了吧,优化后速度可以达到129.722MHz,比之前的快1/2还多。其实这个优化的过程采用了流水线的操作,虽然第一个输出滞后了一个时钟周期,但是整体的运行速度却提高了很多。



 /5
/5 







文章评论(0条评论)
登录后参与讨论