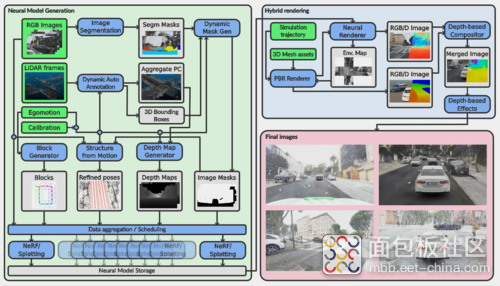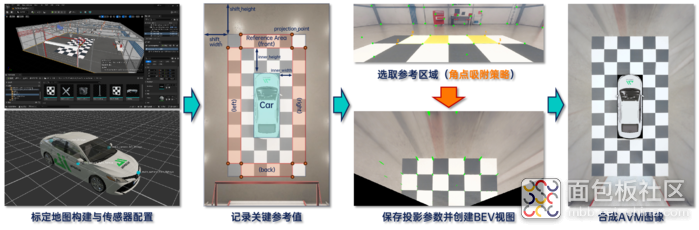
随着自动驾驶技术的快速发展,仿真软件在开发过程中扮演着越来越重要的角色。 仿真传感器与环境 不仅能够加速算法验证,还能在安全可控的条件下进行复杂场景的重复测试。 本文将分享如何利用 自动驾驶仿真软件配置仿真传感器与搭建仿真环境 ,并对脚本进行修改,优化和验证4个鱼眼相机生成AVM(Around View Monitor) 合成数据 的流程。通过这一过程,一同深入体验仿真软件的应用潜力! 一、流程概述 AVM 是一种通过多相机实现车辆周围环境的 实时监控和显示 的系统,广泛应用于自动驾驶和高级驾驶辅助系统(ADAS)的环境感知中。本文基于仿真软件与脚本生成AVM图像的流程如下所示: 图1:基于aiSim构建AVM图像流程 首先,在 Unreal Engine 中配置标定投影参数所需的地图,并在仿真器中为车辆部署4个方向的鱼眼相机; 其次,基于相机内参进行 去畸变 ,并记录求解投影矩阵所需的 关键参考值 ,例如AVM画幅尺寸、参考点的相对坐标、参考区域的大小与位置、车辆与参考区域的距离等; 随后,在完成了角点提取预处理的标定图像中快速 选取参考点 ,生成单方向的BEV视图,重复4次完成 标定去畸变 ; 后文将对每个流程进行具体描述。 二、仿真传感器与环境配置 对于AVM功能而言,通常需要配备4个及以上的 大FOV相机 以拍摄车辆周围的图像,在此基础上还可 配备雷达 以更好地获取车辆周围的障碍物信息。 图2:aiSim相机传感器障碍物真值输出 由于本文所使用仿真软件的相机传感器可以直接输出识别对象(车辆、行人等)的2D、3D边界框真值,所以只需配置 4个方向的鱼眼相机 即可满足整体需求: (1)前置鱼眼相机: 安装在前方车标附近,约15°俯视角; (2)后置鱼眼相机: 安装在后备箱附近,约25°俯视角; (3)左、右侧鱼眼相机: 分别安装在左右后视镜下方,约40°俯视角与相对车纵轴约100°的偏航角。 图3:环视OpenCV鱼眼相机传感器配置 除了传感器的配置,考虑到脚本是通过选取地面点,求解相机到地面的投影矩阵,并转换生成BEV视图进行组合,所以还需要构建一张 特征明显、易于辨认标定效果的地图。 本文所使用的仿真软件支持在 Unreal Engine 中进行 地图编辑与导出 ,并带有一定数量的 3D资产库, 因此可以基于一张基础室内地图,布置一定数量的正方形黑白标定板,根据需要搭建一个标定地图: 图4:基于aiSim插件的Unreal Engine地图编辑 首先,在 Unreal Engine 中打开项目,并进入 室内合成地图; 然后,从 3D资产库 中选择100cm×100cm×5cm的标定板静态网格体,拖放到地图中; 随后,通过直接拖动模型上的变换工具或者修改侧边栏中的变换属性框 调整标定板的位置与姿态; 进而,配置标定板的材质,以黑色、白色的交替顺序铺展标定板; 最终形成一个 长方形的标定区域。 图5:编辑完成后的地图效果参考 批量铺展的过程可以拆分为对2×2的标定板组合实施 横向与纵向阵列 ,完成后的地图如图所示,整体是一个6m×11m的矩形区域, 车辆 放置在中间2m×5m的矩形区域中。 三、图像处理与AVM合成验证集 如前文所述,本文使用的 AVM脚本 是基于车辆四周,位于相邻两个相机重叠视野的标定物,通过 选取参考投影区域 实现鱼眼相机到 BEV 的转化,以前视鱼眼相机为例: 图6:投影区域及BEV转化示意图 首先,由于是仿真传感器的标准OpenCV鱼眼相机模型,焦距、中心像素位置、畸变参数等内参均已知,可直接使用 OpenCV的去畸变函数 实现去畸变,如图6的(c)到(d)所示; 其次,设定 图6(a)与(b)所示关键参数 ,确定图像上的点对应的真实世界位置,进而计算尺度: (1)AVM视野总宽 total_width = 2 × shift_width + 6 × board_size; (2)AVM视野总长 total_height = 2 × shift_height + 11 × board_size; (3)board_size为 标定板边长 ,此处为100,单位cm; (4)shift_width与shift_height为 视野延伸距离 ,单位cm; (5)左上角投影点 projection_point_0:(shift_width + 100, shift_height),以此类推 右上角、左下角、右下角 投影点坐标,形成 投影区域; (6)inner_height与inner_width为投影区域相对车辆的 横向、纵向距离 ,单位cm,由此可以推算出自车所处区域; 而后,对去畸变相机图像追加 Shi-Tomasi角点提取处理 ,并增加 半自动采点 的模式切换,自动选取鼠标点击像素位置周围欧式距离最小的角点,保障准确度的同时提升效率; 最后,如图6(d)选取4个角点,形成与(b)对应的参考投影区域,输出的 BEV视图 如图6(e)所示。 图7:环视BEV合成AVM示例 以此类推可以得到4个方向的BEV视图及对应的投影参数,结合车辆图层作为覆盖,即可生成对应传感器布置下的 二维AVM合成图像 ,如图7所示,其中每个像素分辨率为1cm²。 图8:传感器外参优化示例 通过仿真软件,一方面可以在 控制算法不变 的情况下寻找出更优的 传感器外参布局 ,另一方面也可以在 控制传感器不变 的情况下在多种不同场景验证,进而迭代 优化AVM算法 的表现。结合相机传感器自带的标注信息,后续也可以进行包括 障碍物识别 在内的更多功能验证。 图9:不同场景下的AVM合成数据 四、总结与展望 本文介绍了基于aiSim仿真软件生成 AVM合成数据 的完整流程,包括传感器与地图的配置、图像处理与BEV视图生成以及最终的AVM合成验证。 不难看出,仿真软件的 高效性与灵活性 保障了在安全可控的环境中 快速验证算法性能 的可行性,并可以通过多场景测试与参数优化改进算法,最终提升其综合表现。




 标签: 测试
标签: 测试