
在做信号处理相关项目中,经常会遇到多个数乘加的情况。如下式所示:
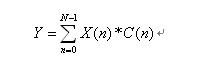
其实FIR滤波器也基本上是这种表达式。如果信号是串行进来的话,那么基本上等效于如下图的结构:
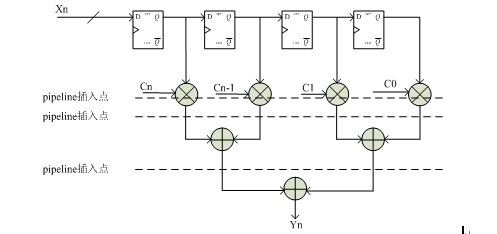
在FPGA设计中,乘法器大部分使用的是内嵌的DSP硬核,如果系统需要跑很高的时钟频率的话,此时会视综合和布线结果而定来决定pipeline寄存器插在何处。由于FPGA的DSP乘法器具有内部插寄存器的功能,那么可以在乘法器内部插入pipeline,也可以在乘法器输出插入pipeline,当然也可以在最后一级全加器的输入前加pipeline,具体的插入点需要根据关键路径而定。上图的只是一个简单的举例,如果阶数很高的话,那么逻辑级数会更高一些。
在FPGA设计中,使用这种方法可以满足一定的时序。可是仔细思考一下,这种方法如果应用到ASIC上或者是阵列式的信号处理上(需要并行的几百套一样的FIR滤波器的时候)是有很大的缺点的。
ASIC的设计目的更偏向于追求面积和功耗的降低。这种方法由于插入了大量的寄存器,因而带来面积的增大,另外一点更为致命,由于插入pipeline的点基本上都是位宽和个数都很多,那么所增加的动态功耗将急剧上升。举个例子,如果在乘法器的输出加一级pipeline寄存器,假设该处理单元有25阶,乘法器输出位宽为16bit,那么就该级的pipeline就要增加16*25个寄存器,如果有256个一样的这种并行阵列,那么单单一级pipeline就需要256*16*25个寄存器,所增加的资源和功耗将是非常可怕的。
另外还有一个缺点,在ASIC设计中,如果约束的时钟越高,那么实现同样的功能综合器综合出来的面积将是不一样的,特别是使用了一些实现资源可以优化的软IP(即RTL代码,如果你对该IP实现方式不了解的话,是无法对该IP进行don’t touch约束的,即无法指定综合器不优化该逻辑)约束的时钟越高,跑出来的面积越大。因此这也无形中增加了资源。
因此,事实上一个较优的乘累加设计,尤其是涉及到阵列式,需要多套并行信号处理的时候,应该是采用另外一种思路,该种思路包含以下两个重要方面:
接下来将继续介绍这种思路。



 /5
/5 






文章评论(0条评论)
登录后参与讨论