我们知道“摩尔定律”形容的是半导体的尖端制造工艺——现在尖端制造工艺的 foundry 玩家就剩 3 个了,毕竟成本和技术投入也不是谁都承受得起。而能够承担尖端制造工艺的芯片门类也不多,电脑、手机、数据中心里面的大芯片,然后就没有了。
从技术角度来说,CPU 这类通用处理器受惠于摩尔定律的性能提升幅度越来越有限,原因比较复杂,不是咱要讨论的重点。得到尖端制造工艺最大红利的,我觉得是更偏专用的芯片:就是那些能大量堆砌算力、搞大规模并行计算的芯片。AI 芯片、GPU 都是典型。
所以 GPU、AI 芯片每年迭代堆晶体管都还是蛮狠的,因为堆晶体管真的有效,多堆一些计算单元,算力也就跟着提高——虽然堆晶体管实现性能趋近于线性提升也不是那么简单。
不过这些芯片也面临一些实际问题,比如说芯片已经那么大了,再大半导体制造设备都处理不了;与此同时晶体管微缩速度显著放缓,根本就做不到每 2 年单位面积内的晶体管数量翻番——这其实也是阻碍堆晶体管的重要因素。最近英伟达 GTC Fall 上,黄仁勋就说:“摩尔定律主要讲的是有关于晶体管的,还有技术代与代之间成本变低。但现实已经不是这样了。摩尔定律已经结束了,技术现在变得越来越昂贵。”
其实有关“单个晶体管造价成本降低”的问题,这应该算是摩尔定律的一个推论——有兴趣的可以去看看维基百科对摩尔定律的具体阐释。老黄说的是事实,从 20nm 以后,单个晶体管造价就在一路小幅攀升——前两年有关这方面的研究还挺多的;这就相当于摩尔定律终结了一半。而到现在,即便半导体制造上游的很多市场参与者还在嘴硬,也改变不了现实。
当然,其实解决问题的方法还有不少,比如其他更系统层面的方案——像 chiplet、先进封装、DSA(专用架构)、Synopsys 的 SysMoore 之类的。不过咱来看个更有趣的例子:
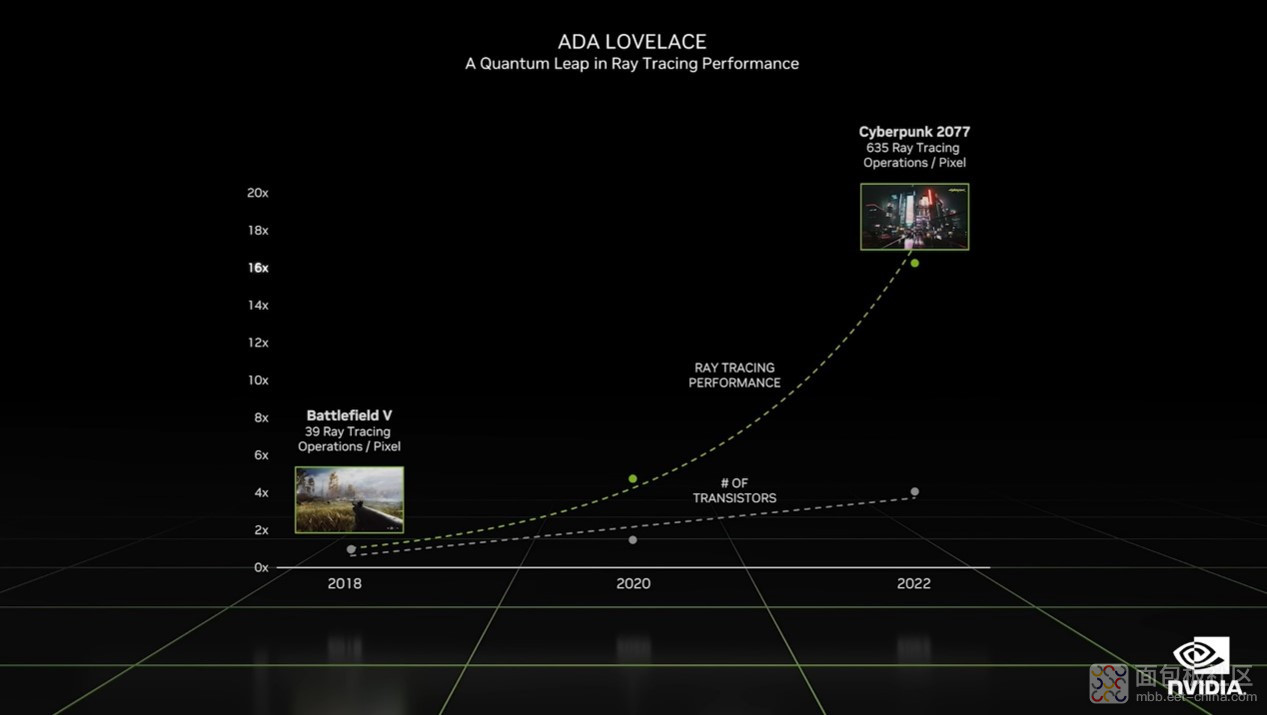
这是黄仁勋在主题演讲中展示的一张PPT。这张图中下面那根曲线是 2018 - 2022 年英伟达 GPU 的晶体管数量增长趋势,从增长倍数来看也还行。
但光线追踪的性能需求,已经从 4 年前的每像素 39 次光追操作,上涨到 635 次。之间的性能跃升是 16 倍。如果真的只靠堆晶体管,那就扑街了。
英伟达针对今年新发布 Ada Lovelace 架构显卡综合性能提升的宣传说辞是“4 倍”。今年 GTC Spring 的时候,英伟达也说面向数据中心的 Hopper 架构 GPU 性能提升 3 倍——就摩尔定律的角度,这都相当不科学。尤其黄仁勋不是还说摩尔定律结束了吗?那这 3、4 倍的性能提升都是哪儿来的?通用处理器一年性能提个 20% 就了不得了。
基于对这些“倍数”的解析,也有利于咱从 fabless 的企业看一看,这年头提升芯片性能应该用怎样的思路。反过来说,芯片设计企业的这些操作,其实也能有效佐证摩尔定律的终结,毕竟他们已经无法倚仗摩尔定律卖货了。
文章比较长,可以选择性阅读;各章节也可跳转阅读。(这次 GTC 发布的 RTX Remix 也挺有意思的,我专门写了一篇文章,附在文末)
4080 12GB 性能真的能约等于 3090 Ti?
对消费用户而言,GTC Fall 的大热门莫过于 GeForce RTX 40 系列新显卡。从产品层面先来简单看看这次的新货。
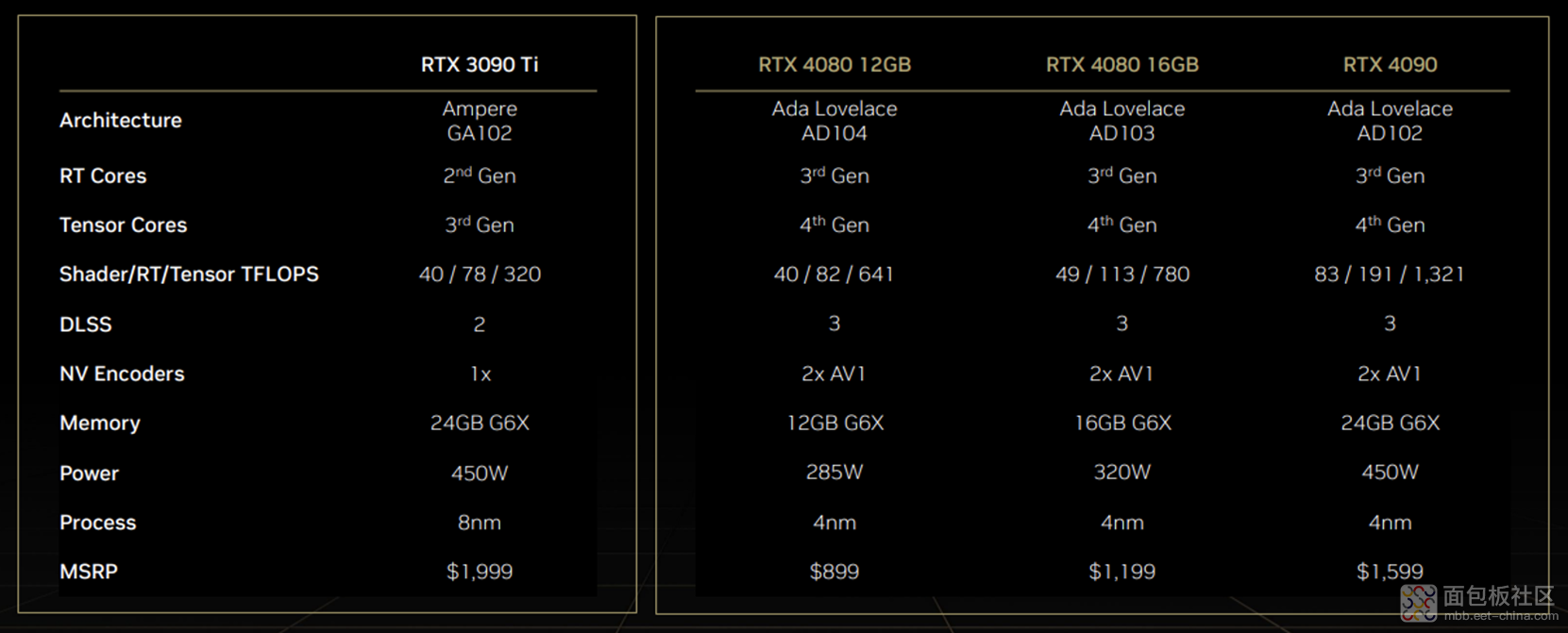
游戏显卡新发的产品主要就 3 个:GeForce RTX 4090、GeForce RTX 4080 16GB 和 GeForce RTX 4080 12GB。
貌似这次被吐槽比较多的是 4080 12GB 版,因为这块显卡的 die 和 4080 16GB 都不一样,按照传统应该放到 4070 一档。不过英伟达说 4080 12GB 在性能上最高达到了 3080 12GB 的 3 倍,比 3090 Ti 性能强,所以仍将其归于“4080”定位。
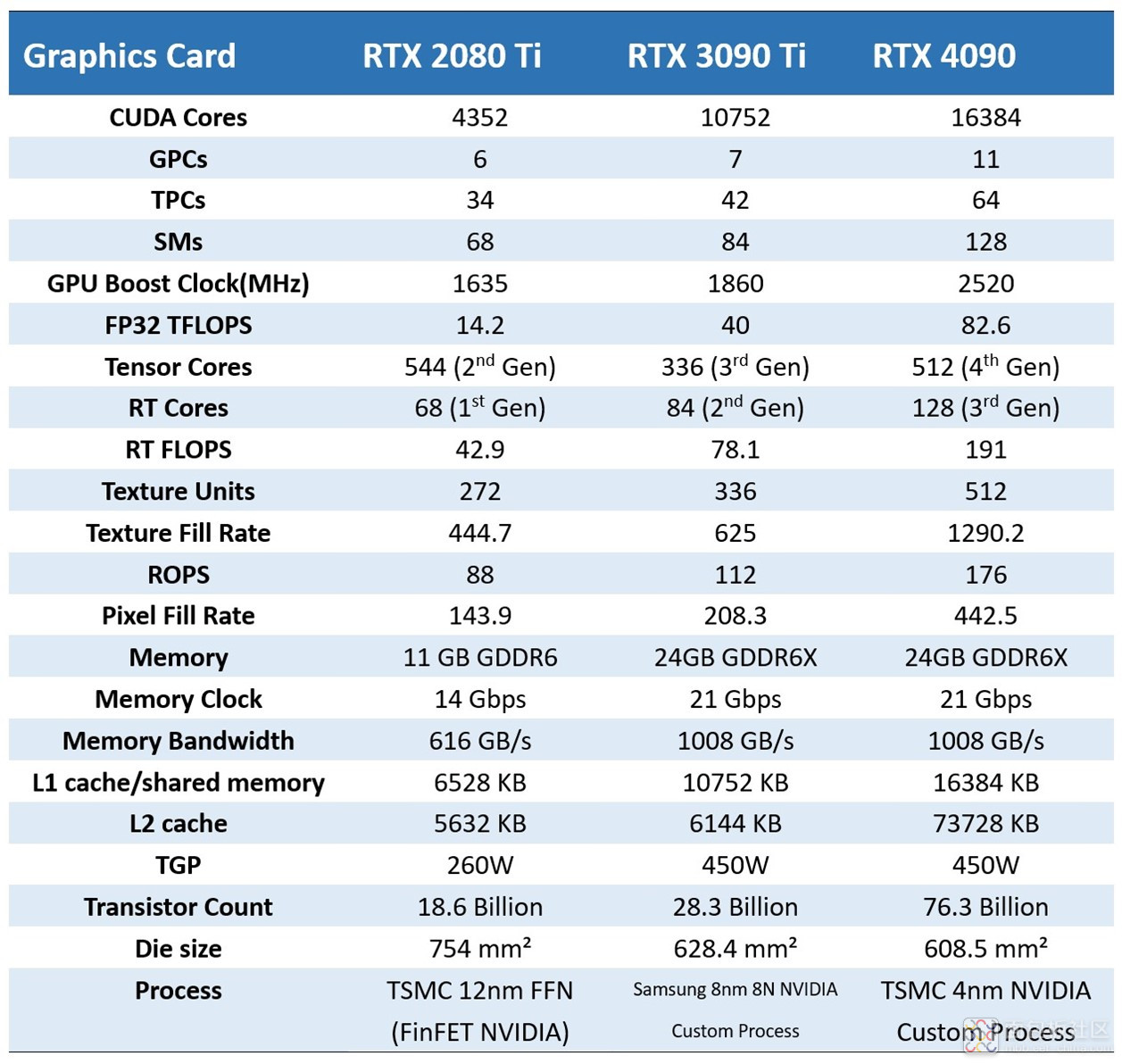
已列出的参数就不多啰嗦了,看图即可,说一些亮点。基于台积电 4N 工艺,4090 的 AD102 die 上堆砌的晶体管数量是 763 亿个,die size 608.5mm²;3090 Ti 的这两个值是 283 亿和 628.5mm²。台积电果然还是比三星要靠谱许多的…
可能很多同学对 763 亿晶体管没有量级概念。实际上很多数据中心的大规模 AI 芯片、GPGPU 都没有这个数量级,比如 Graphcore IPU 的单 die 也就 600 亿晶体管,英伟达自己用在数据中心的 Hopper 架构 GH100 是 800 亿晶体管。这年头,玩个游戏都这么高级了吗?
另外,新架构新工艺带来的一大亮点在于功耗的显著降低。我个人感觉就工艺器件层面,比较有对比价值的一个数据是,4090 的 TGP 450W,和 3090 Ti 一样,但前者的浮点吞吐性能是后者的 2 倍。这种比较 raw 的对比方式,是能够看出工艺层面的进步的。
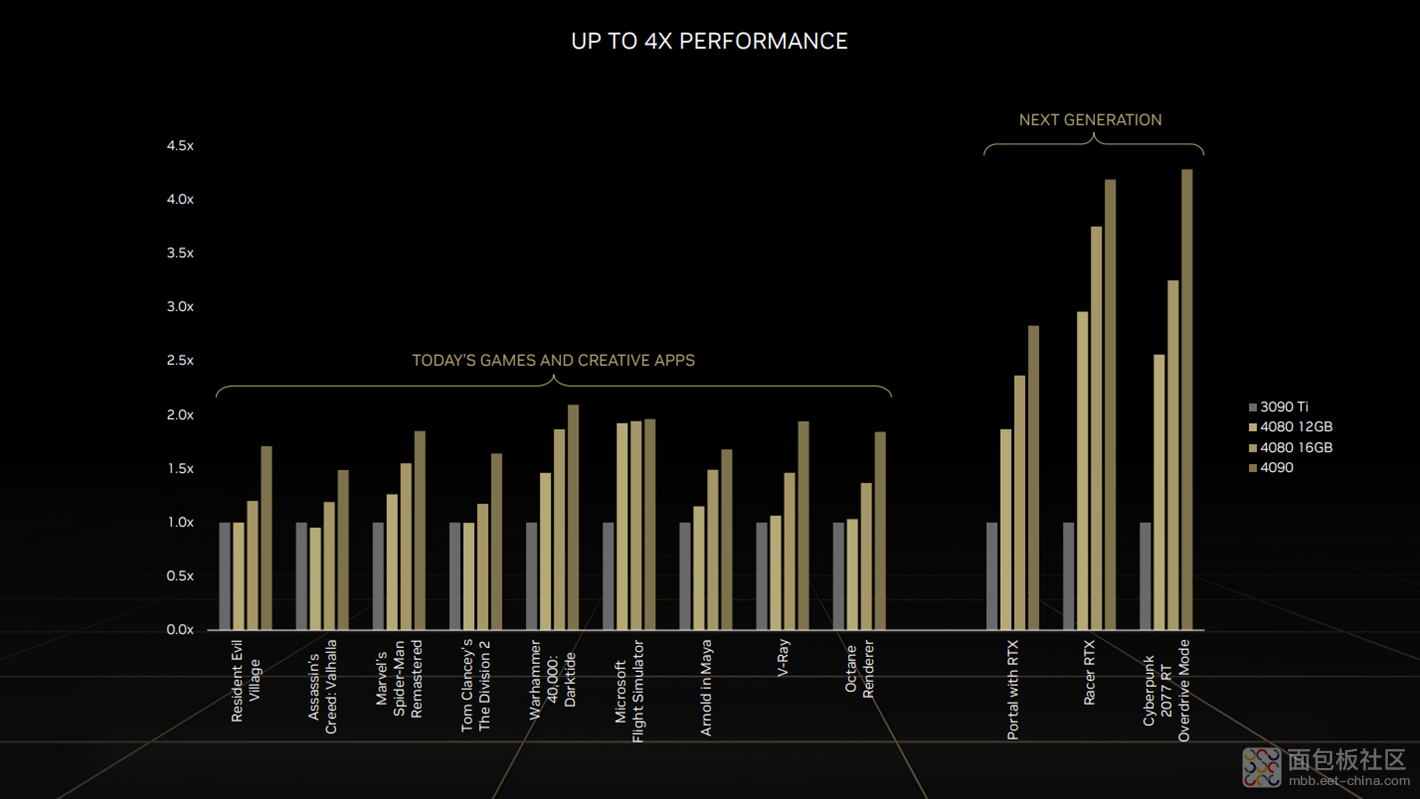
还有一个说法,是前面提到的英伟达说 4080 12GB 性能就比肩 3090 Ti 了,但功耗却从此前的 450W 降低到了 285W。这个说法是否有待商榷?佐证是下面这张图的游戏与应用实测数据。
这个数据一大部分是基于 DLSS 3——后面会提到这项技术。看过发布会或报道文章的同学应该知道 DLSS 3 的技术主体包括了游戏画面的超分(AI Super Resolution)和插帧(AI Frame Generation),另外还有个 Nvidia Reflex。尤其是插帧,看起来简直是刷游戏帧率神器;换句话说一部分画面并不是图形单元渲染出来的,而是 AI 生成的。这也算性能提升吗?
就这个问题,说一点个人感想。我始终觉得“以体验为本”是考察性能是否真的提升的依据。当代图形计算的很多 tricky 技术都是基于这一点,比如说 VRS(可变速率着色)——很早以前就有人说 VRS 是“虚假的帧率提升技术”。但这项技术是真切地提升了画面帧率,同时对体验又没有什么影响的;那么它就是一项应纳入性能考虑范畴的技术。
超分、插帧如果能真切提升游戏流畅度,而且对画质和体验几乎没有影响或影响很小,则其带来的性能提升就应当被纳入考量。其实电子工程(EE)和计算机科学(CS)这两门学科,乃至更多电子相关的工程类学科的一大特色,就是利用各种 tricky 技术来实现进步。而随着摩尔定律的结束,堆晶体管已经没那么有效,一切 brute force 的技术推升都需要一些“奇技淫巧”来从旁协助。行业其实就是在各种奇技淫巧思路的推进中发展的。
从 Turing 架构开始,在图形 GPU 上增加 RT core、Tensor core 多少都算当年的奇技淫巧。而它们的计算范式一旦成为行业标准,构成生态,也就成为了图形技术的组成部分。像 3DMark 这种 benchmark 工具都已经在逐步加入对于光追、AI 超分的考察方法,自然算得性能提升。
据说 DLSS 3 今年 10 月就会应用于首波 35 款游戏和应用中,这进度似乎比 DLSS 最初发布的时候还要顺利。这也算英伟达在生态号召力上的体现吧。其实如果某种技术和标准没有号召力,则它对于实际性能的贡献,大概率都会被整个行业排除在外。
所以 4080 12GB 性能约等于 3090 Ti,以及 Ada Lovelace 消费级显卡性能相比 Ampere 消费级显卡提升 4 倍,这类命题能成立的一个必要条件就是生态号召力足够强大。当然还有就是技术本身能够实打实提升体验(所以叫“以体验为本”嘛),而不是像既有的一些插帧技术一样,极大增加了游戏操控延迟,那把帧数提升算在性能进步里,就比较不靠谱了。
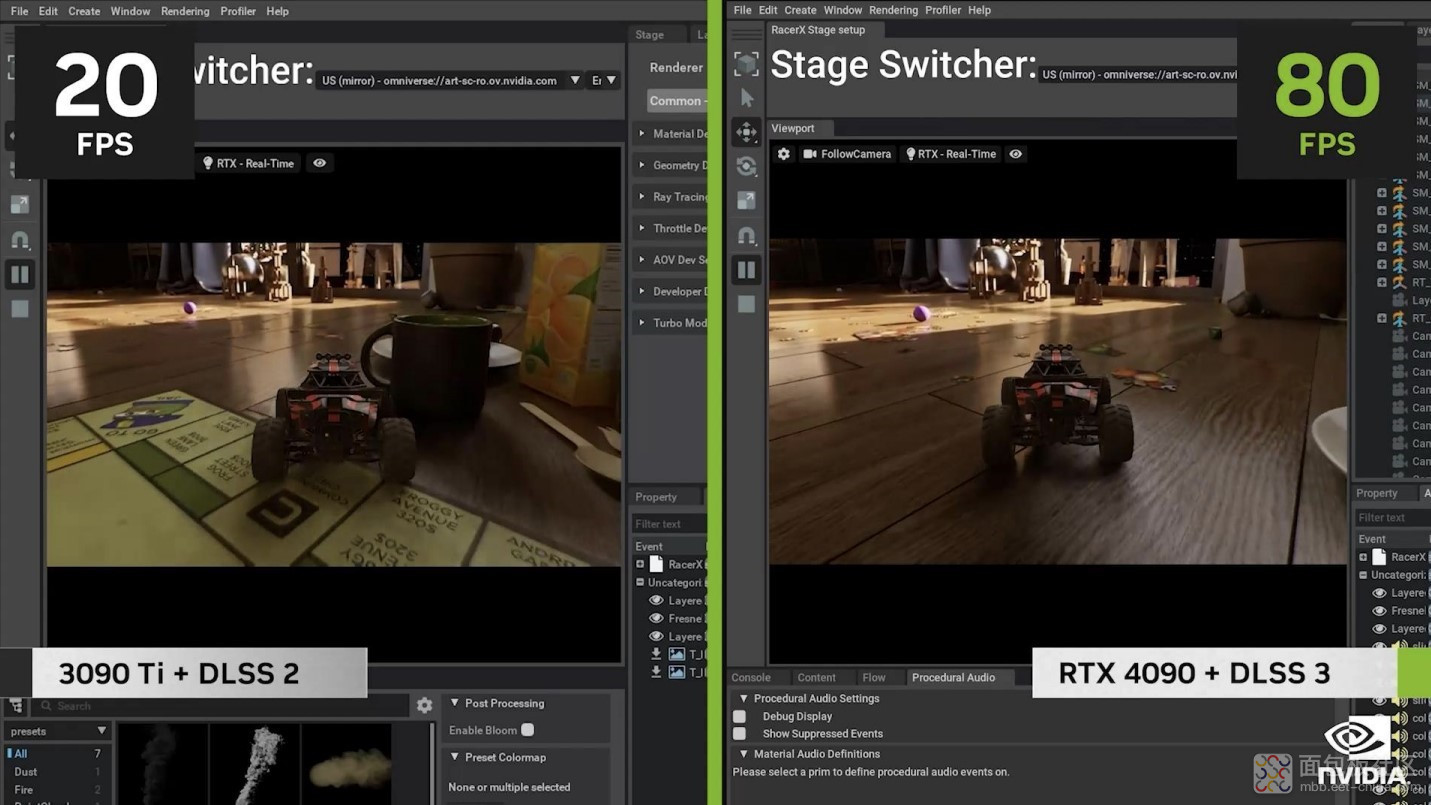
我个人印象比较深刻的一点是这次英伟达不是还发布了一个 Racer X 么?英伟达说对于其设计,如果是用 3090 Ti + DLSS 2,那么设计师是需要做权衡的:要么就是你看到的画面是物理级准确的(physically accurate),但帧率会很低;要么就是帧率可以更高,但预览的渲染精度会明显更低。但英伟达说,这回的 4090 + DLSS 3,帧率、精度都能有。我感觉这个点的性能提升是质的飞跃。
产品层面最后值得一提的是,除了 GeForce 显卡以外,这次 Ada Lovelace 架构显卡还有新增面向工作站的 RTX 6000 更新,以及用于数据中心的 L40。后者不是 Hopper 架构,而是富含图形单元的 Ada Lovelace——所以也就是云游戏,或者其他图形计算密集型应用,也包括 AI、CV,当然还有 Omniverse。
Ada Lovelace 新架构概览
有关 GeForce RTX 40 系 GPU 详细配置,网上的信息已经比较多了,这里不再一一列举,包括目前最大的 AD102 die 的 CUDA 核心、频率、TGP,还有 RT core、Tensor core 有多少、第几代等等,汇总相较于前两代显卡旗舰款的配置数据对比如下:
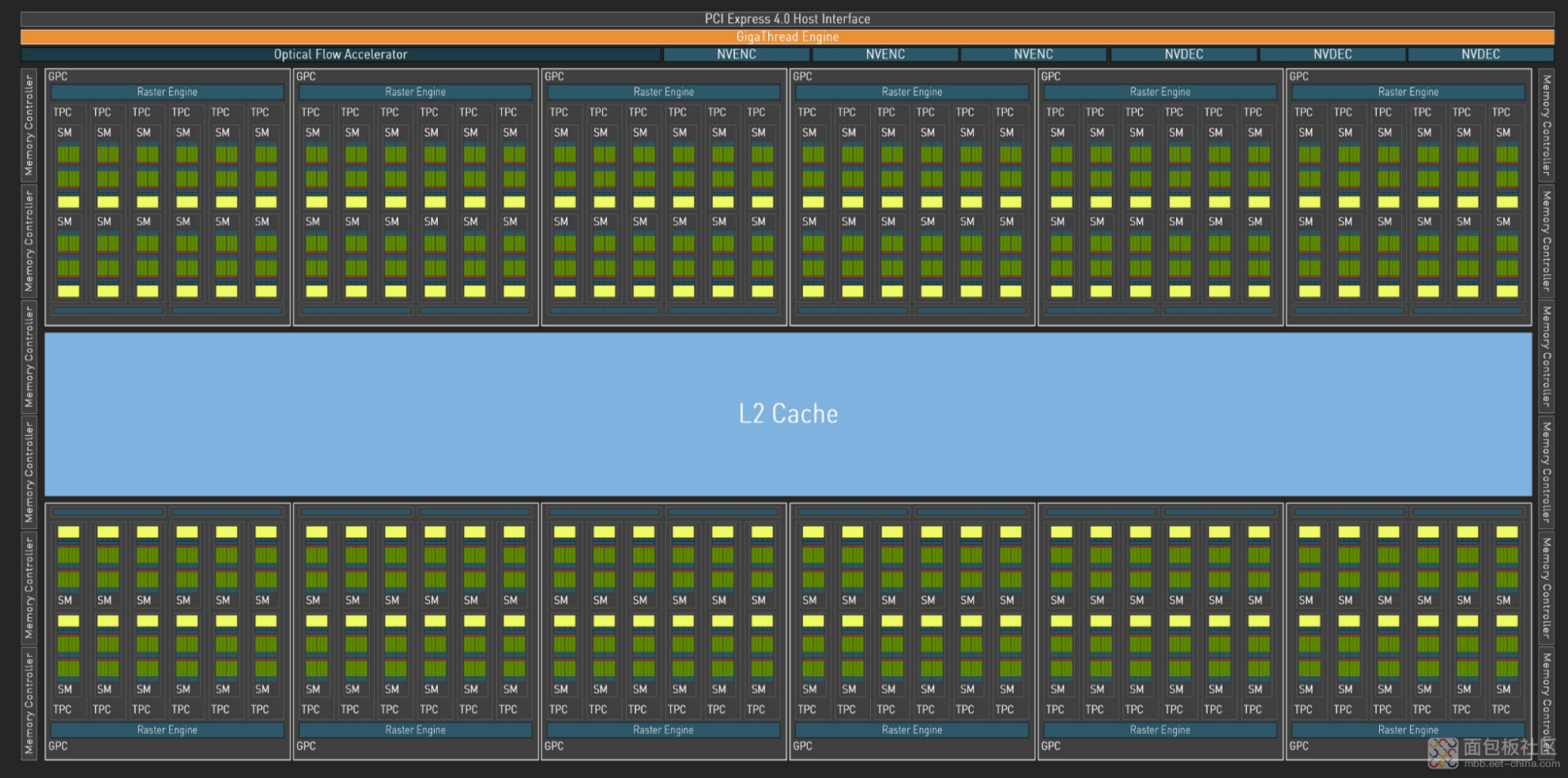
SM 层级、GPC 层级
GPU 层级
AD102 从 SM 到 GPC 到 GPU 不同维度的模块构成示意如上图,应用于 4090 的时候如何下刀的应该也一目了然了。不过这个示意图也有一些信息未给出,比如说每个 SM 还带 2 个 FP64 核心。还有编解码器,NVENC 升级到第 8 代,开始支持 AV1 编码——高配的 GeForce RTX 40 系配了双 NVENC 编码器;NVDEC 解码器配置不变。
从 AD102 die 层面,总共应该是 18432 个 CUDA core,144 个 RT core,576 个 Tensor core,576 个 TU(纹理单元)。像存储子系统之类的部分就不多谈了:比如 AD102 的 L2 cache 堆料算是暴涨的;还有显存方面,似乎就系统角度来看,据说这次英伟达和美光合作搞的 GDDR6X,加上重新设计的散热系统,能在显卡工作时让温度相比 3090 下降 10℃——主要是因为更高的显存密度,颗粒放在了 PCB 单面……更多配置数据就看图吧。
比较值得一提的是,上代 Ampere 架构的 RT core,也就是处理光追的单元,主要包含了 Box Intersection Engine(用于 BVH 盒子遍历加速)和 Triangle Intersection Engine(光线-三角形相交测试加速)——这是第 2 代 RT core。现在这类单元貌似已经成为当代光追 GPU 标配。
Ada Lovelace 的第 3 代 RT core 新增了 Opacity Micromap Engine 和 Displaced Micro-Mesh Engine。这两个新增的单元促成的改进,可认为是加速实时光追技术发展的重要组成部分。另外还有老黄在主题演讲中着重说到的 SER(Shader Execution Reordering,着色器执行重排序)。
而第 4 代 Tensor core,或者说专用 AI 单元,其乘加矩阵算力的具体情况可以去看英伟达官网产品介绍。比较值得一提的是,Tensor core 里也加入了 Hopper 架构中的 FP8 Transformer 引擎,毕竟这符合 AI 应用发展的大趋势。此外,和 Tensor core 相关的 DLSS 3,以及专用的 Optical Flow Engine 单元,后文会单独谈到。
光追技术上的几个变化
光追这两年越来越成为 GPU 的标配了,不光是PC市场的主要竞争者都给 GPU 加上了专用的光追单元,移动平台都已经在积极着手布局光追。这方面迈步比较早的英伟达,眼见生态建设成果还不错,就开始搞光追技术和流程的优化、迭代了。
这次的第 3 代 RT core 对于整个光追生态而言,应该都会有借鉴意义。我个人的理解是光追相关的 3 个主要改进,其实都着眼于解决光追技术现存的问题,或者说尝试提升光追的效率。
先来聊聊 SER。老黄在发布会上说这项技术为光追带来的价值,无异于当年 CPU 引入乱序执行。
其实对于不包含光追的纯光栅渲染管线,SIMT(Single Instruction Multiple Threads)操作是很自然而然的,一条指令、并行线程就下去了,填充进 shader 的所有通道。比如一个三角形,如果这个三角形对应 32 个像素,那么它们都跑在一起。Shader 要被高效利用,就应该是跑一个程序,shader 内的所有通道都被占满。
光线在碰到场景中的对象(secondary ray tracing),又射往不同方向,以前的 GPU 跑起来就会相对低效,因为不同的 shader 程序跑在不同的线程上,而且还经常串行化执行
而到了光线追踪情况就不同了,工作负载间很多时候不再有天然的相干性,因为场景内的每条光线可能会四处乱飞。或者说它们相当的“发散”。不仅是不同的线程会执行不同的 shader 或者代码路径,还在于线程要去访问存储资源的时候,这些资源很难做 cache。
Ada Lovelace 对此所用的解决方案就是 SER。技术白皮书中说这是个新的调度系统,对 shading 工作进行重排序,以实现更好的执行和数据 cache 效率。据说英伟达在这方面花了多年时间做研发。
SER 是在光追管线上新增了一个环节,如上图就是对上例中的第二次光线 hit shading 进行重排序和分组,那么在后面的执行阶段也就能更加高效。英伟达说加上这项技术以后《赛博朋克 2077》在光追 Overdrive 模式下,从 SER 这一项特性获取的性能提升达到了 44%。
其实自此就很容易理解,对架构的改进,相较于单纯堆计算单元和晶体管的收益有时可以高很多。不过光追技术原本就在发展早期:或许它未来还会有极大的余量做各种流程优化。值得一提的是,开发者可基于 API 指定对特定负载做排序的最佳方法。这又是个需要培养生态的技术。当前英伟达在和微软之类的合作伙伴合作,令其成为标准图形 API。
除了 SER,Ada Lovelace 另外两个改进,一是 Displaced Micro-mesh,二是 Opacity Micro-masks。这俩改进本质也是针对光追技术的优化的。
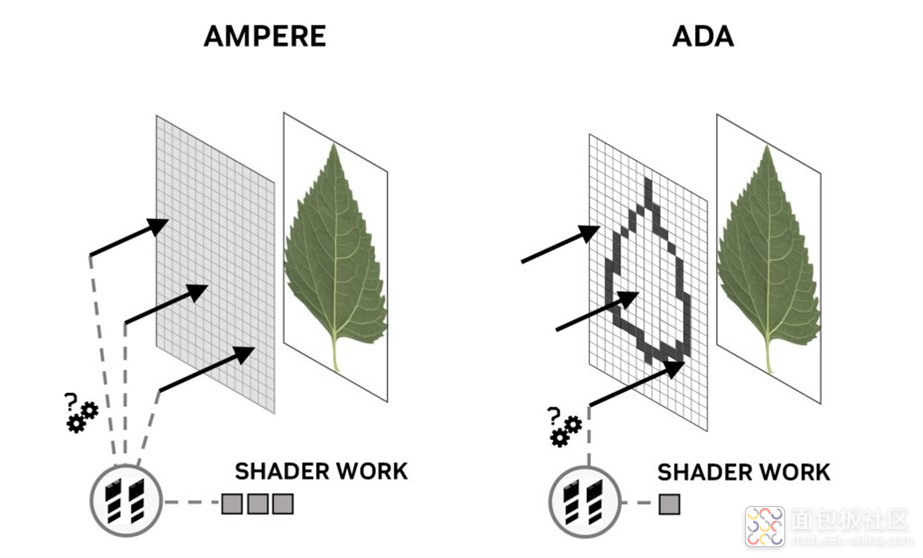
其中 Displaced Micro-mesh 着眼于解决光追在遇到大量几何细节需时开销过大的问题。因为光追以前所用的 BVH 数据结构需要搞定场景中的每一个三角形,要直接捕捉每个细节,开销就很大:包括 BVH 构建所需的时间,和占用的存储资源。
Displaced micro-mesh 是几何形状的一种结构化表达,用来表达几何细节(上图图左的右边部分)。简单来说,它知道如何构造螃蟹腿上的那些凸起。基于粗粒度最基本的三角形(上图图左的左边部分,base triangle),RT core 就知道如何解决问题了;并且能够最终得到上图右那样的效果。
从硬件层面来看,RT core 里面新增了 Micro-Mesh Engine,用于生成细分的 micro-triangles。这里面还涉及到什么 displacement map、压缩之类的问题,就不细谈了;有兴趣的可以去看看 Ada 架构技术白皮书。
值得一提的是,Simplygon 和 Adobe 两家都已经宣布把 displaced micro-mesh 支持加入到它们的工具链里面。这种事情一般能够表明它有可能成为新的标准存在。
还有就是 Opacity Micro-mask 了。玩游戏的同学应该知道,3D 场景中逼真的植物渲染开销不小。绘制上面这样一片叶子,一般是搞个矩形、然后在上面应用纹理;当然叶子不会是矩形的,那么就需要有些部分是透明的。
以前没有光追的年代 TU 会去检查 alpha(透明度)通道,自然就知道了要绕过对应的透明部分,一切都比较顺利。但在光追世界里,RT core 干不了这件事。RT core 会去看整个矩形,光线打到矩形的任意位置,它就要把信息传递给 SM——SM 再去搞清楚某个地方是不是透明的,然后再告知 RT core 继续做光线追踪,或者这地方是不透明或半透明的…
这一代 RT core 为此引入了 Opacity Micromap Engine 单元。简单来说 RT core 能够基于 opacity micromap 的透明度状态,来直接解决光线相交的问题。仅在状态标注为“unkown”时才需要找 SM 帮忙。这样一来,效率会有大幅飞跃。具体的方法涉及到了所谓的 opacity mask,而 Opacity Micromap Engine 就负责标注透明度状态……细节就不做深入了。
也不光是树叶子,比较典型的像烟雾缭绕的场景,以往开启光追时就很容易悲剧。那么新特性的引入就会极大提升这方面的表现。英伟达在这次自己做的 mod《Portal RTX》里面也特别演示了对应的场景。
英伟达表示这几项特性包括 SER 都已经通过 SDK 的方式提供给了开发者,开发者可以很容易进行集成支持。而未来是否能和微软合作,通过 DXR 做集成,也可以期待一下。好像电子产业发展至今,更下游开发者的水平也极大程度决定了性能跃进幅度。
说了这么多,以上都是 GeForce RTX 40 系显卡相较前代实现 2 倍性能提升的技术基础。不是说好的 4 倍吗?还有 2 倍在哪里?那就是 DLSS 3 的事情了。
AI 算出来的帧率
DLSS 最初作为一种 AI 超分技术,从初代诞生至今已经 4 年了。前面我就说 DLSS 是种“奇技淫巧”。因为严格来说,DLSS 更靠近计算机视觉,而非图形渲染 – 还是基于 AI 的。它在思路上,就“GPU”这类硬件来看算是相当不正经。
而 DLSS 的出现,本身就很大程度代表着摩尔定律的终结。因为如果晶体管数量真的能无节制往上涨,还满足市场需求,那么图形渲染发展得好好的,要 CV 干嘛?一定是现有技术压根儿满足不了市场,才需要“奇技淫巧”的辅助。
黄仁勋在主题演讲后,接受采访时说了个很有趣的点:“英伟达就生于摩尔定律终结的时代。”“这也是加速计算崛起的原因。”这个立意听起来就拔高了一些:加速计算变火,客观上就表现出了摩尔定律的终结——好像真是这样。
而 DLSS,本质上属于 1 级加速计算附带的 2 级加速计算。因为 GPU 本来就已经是图形加速器了,而 DLSS 则成为了用来给图形计算再做加速的加速器。挺有意思的吧?
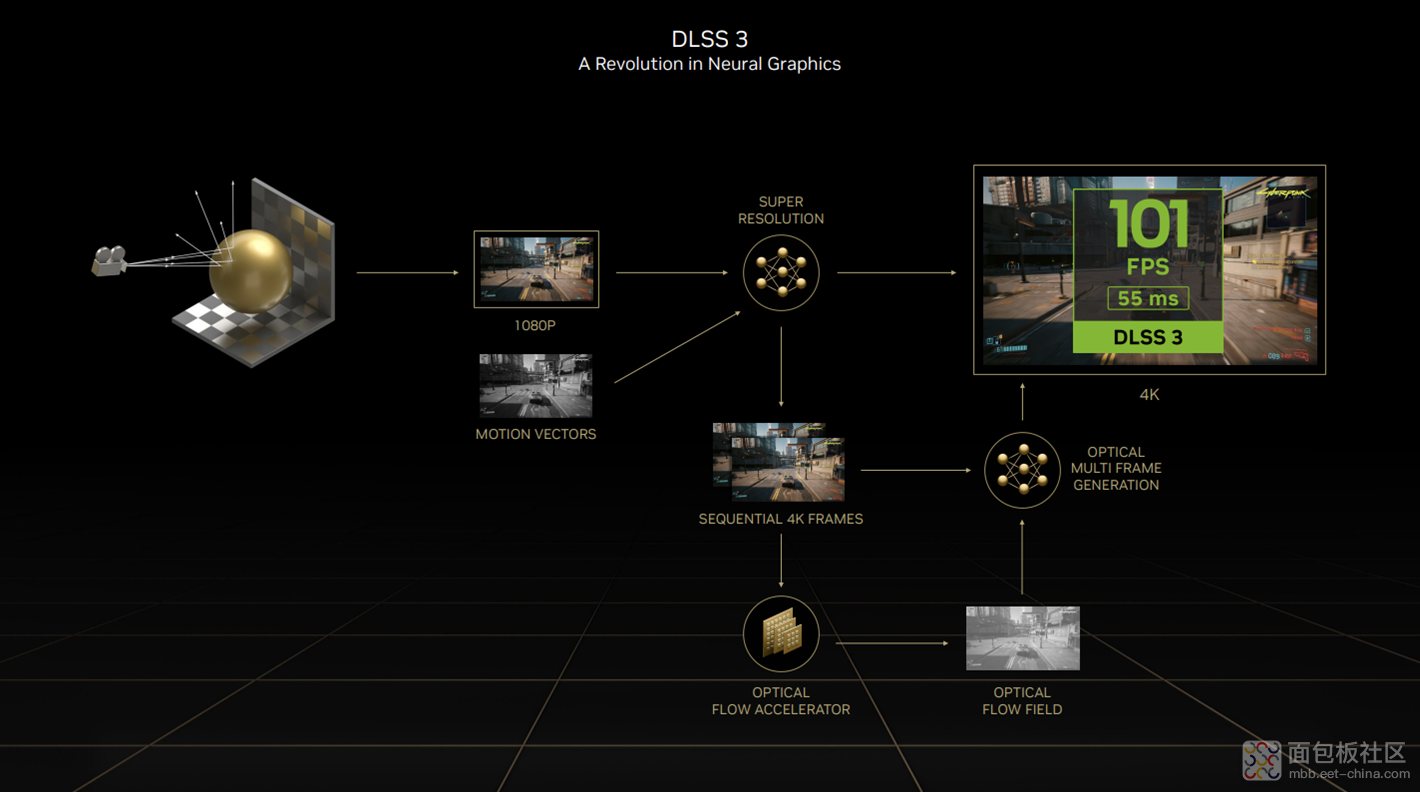
这次伴随 Ada Lovelace 而来的 DLSS 3。从软件层面来看,除了众所周知的超分(super resolution)——也就是基于AI把低分辨率的画面 upscale 为高分辨率,还新加了 AI 插帧(frame generation),以及 Nvidia Reflex。这三者干的事情分别是:提升画面清晰度(画质)、提升画面流畅度(帧率)、降低游戏操作延迟。
超分就不多谈了,其详细工作流程,网上现成的资料不少。而且这次 GTC 上英伟达也没怎么聊超分,估计和 DLSS 2 的超分差不多。着重来看看 AI 生成帧和 Reflex。
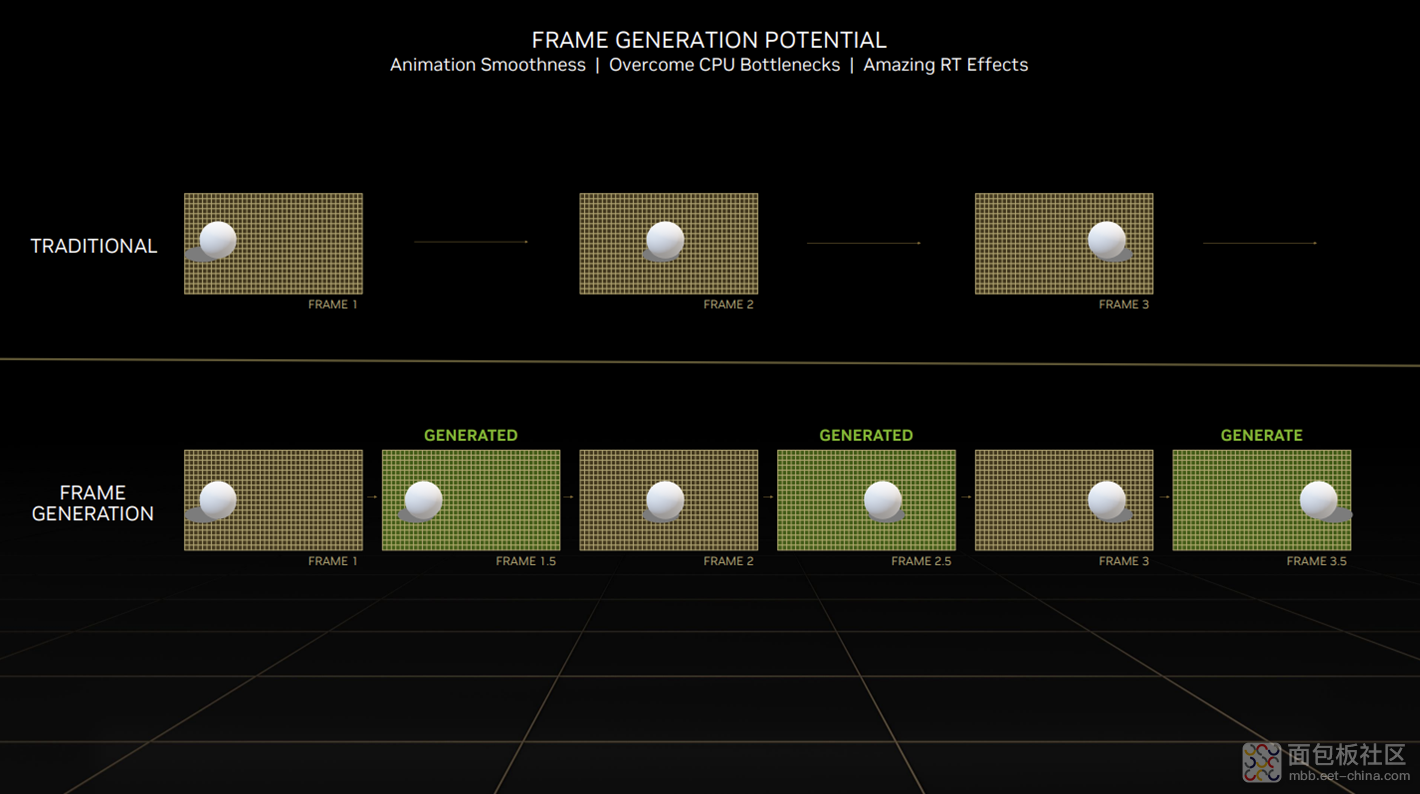
插帧或者叫补帧,顾名思义就是在原有 GPU 渲染出来的帧的基础上,再生成一些帧,以提高动态画面的帧率,起到提高画面流畅度的效果。这两年貌似手机行业有 OEM 厂商在搞的“显示芯片”就专职插帧(MEMC),但体验并不好,而且有明确可感知的操控延迟。
英伟达在技术白皮书中说,这项技术是过去 4 年 Applied Deep Learning Research 团队开发的。相关技术负责人说:“帧生成的挑战很大。我们需要确保画面中对象的顺畅、合理移动,确保不会让对象失真:比如要处理好画面中遮挡的问题,某个东西又出现的问题。另外还需要处理好游戏交互,确保很低的延迟。”这应该是现有解决方案存在的所有痛点。
光流法(optical flow)是计算机视觉应用中比较常见的,用来在连续渲染帧或视频帧之间,判断像素运动方向和速度的一种技术。其应用似乎还挺广泛,甚至在深度学习领域也用作汽车、机器人巡航、视频分析和理解等。
Ampere 架构 GPU 上就有专门的 OFA(optical flow engine,光流引擎)单元。而 Ada Lovelace 上的 OFA 提升了性能,标称 300 TOPS 光流操作,2 倍于 Ampere。似乎从英伟达的解释来看,Ampere GPU 之所以不会支持 DLSS 3,主要就是因为对于目前的算法来说,OFA 的性能不够。
当然另一个核心也在于运动矢量分析算法。DLSS 3 的插帧就是基于运动矢量+光流。英伟达说之所以要做光流,是因为如果只用运动矢量的话,画面可能会出现大量伪像。尤其在应用光追的情况下,因为几何运动矢量根本就无法用于判断光追造成效果的移动。比如画面中路面上的阴影,如果把这个阴影当作几何体,则它也会随着路面向后移动。但实际上我们知道,这个阴影应该是随视角位置相对稳定的。这就需要用光流来判断。
所以这里 engine motion vectors 能够理解几何体的移动,而 optical flow vectors 则能够更多的理解外观变化情况。英伟达说其实光流对于运动的理解不够精准,会犯错,最终效果也各异;这是 Ada Lovelace 投入光流加速器单元的原因,是为了令其更快、更准确。
这回 GTC 主题演讲和各路 session 都拿《微软模拟飞行》在应用 DLSS 帧生成技术后帧率暴涨来举例。其实像这种 CPU 为主要瓶颈的游戏,较大程度受惠于 DLSS 插帧很正常——CPU 瓶颈决定了超分技术的收益会很有限,但插帧是不需要 CPU 参与的,自然帧率倍增。
从英伟达那里听到相关插帧的技术解释差不多就这些了,总感觉这其中还遗漏了些什么重要信息。比如说所谓的 AI frame generation,并没有看出“AI”技术的应用——针对这一点英伟达倒是有告诉我 DLSS 3 的 frame generation 算法模型是 AI 计算模型,所以也需要 Tensore core 来加速; 还有从直觉来看,这么做仍然很容易造成可感知的操控延迟。猜测基于 GeForce RTX 40 系 GPU 的原生堆料和运算速度提升,DLSS 3 未应用于 30 系 GPU 的一大原因也在于旧显卡的延迟可能会太高。
英伟达展示的数据是,《赛博朋克 2077》开启光追 + DLSS 2 超分,输出 4K 画面的帧率是 62fps,延迟 58ms;而接入 DLSS 3,加入插帧,则帧率提升到 101fps,延迟还更短了。DLSS 相关技术负责人只在采访中说,针对 DLSS 帧生成技术,英伟达投入了大量工作,所有的优化加在一起、“对整个图形管线做优化”,才有了现在的结果。
当然 DLSS 3 还有一个组成部分没说,就是 Nvidia Reflex,这是一项显著降低操控延迟的技术。英伟达告诉我说,frame generation 带来的新延迟会被 Reflex 抵消,Reflex 也提供了更多的优化。“所以在绝大部分场景下,开启DLSS 3 会比,开启 DLSS 2 而没有开启 Reflex 的(情况)延迟更低。”
说起来,Nvidia Reflex 也不是新技术了,之前英伟达在竞技游戏和电竞圈里推 Reflex 生态也挺长时间。这次把 Reflex 作为 DLSS 3 的一大组件,可能是插帧有增加延迟的风险,故而需要借助 Reflex 再推一把——这是我自己猜的,但从英伟达的反应来看,差不多就是这样。
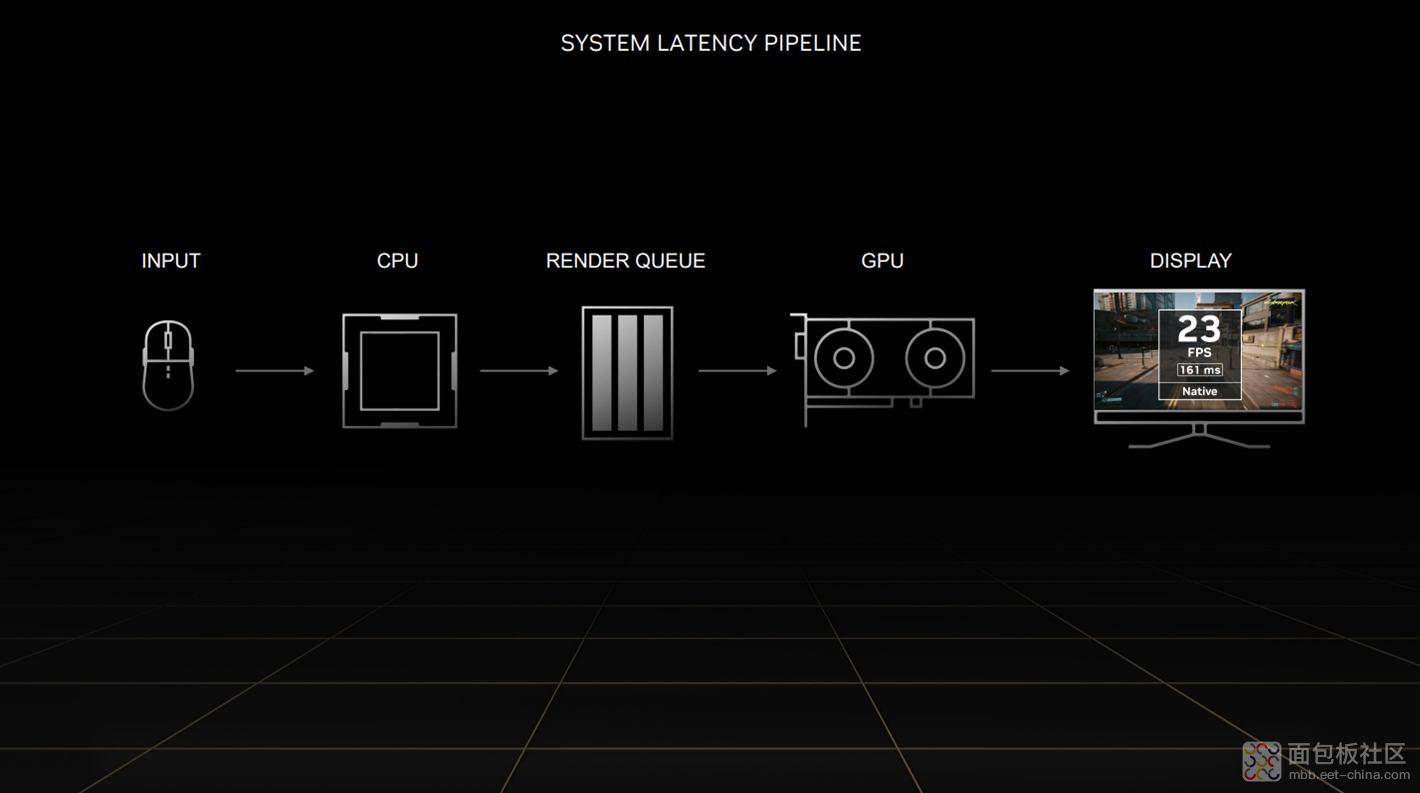
我们所说的游戏延迟,是指从输入设备发出指令,比如鼠标按下按键,到屏幕上的像素做出响应,这之间的时间。此前好像不少游戏输入输出设备供应商都推出过 Reflex 生态产品。
这个流程里当然还有 CPU 之类的参与,包括生成一大堆的 draw call,告诉 GPU 如何绘制场景,并进入到渲染队列(Render Queue)。GPU 就从渲染队列中去取这些 draw call,渲染完了会把画面发给显示器。
这里面有几十毫秒的延迟可能会是渲染队列带来的。其实渲染队列的存在很大程度上是为了确保 GPU 的高利用率的。要移除渲染队列还是需要很仔细的。Nvidia Reflex 在这条通路上的选择之一就是移除渲染队列。
据英伟达所说,Nvidia Reflex 很仔细地协调了 GPU 和 CPU 的工作。这其实就要求 Reflex 非常了解游戏引擎在某些特定点的工作状况。这主要依托于游戏开发者在游戏引擎里增加的一些所谓的“Reflex Markers”标记,这些标记会告诉 Reflex 软件怎么做,那么 CPU、GPU 在不需要渲染队列的情况下,就能保持高效同步。如此一来也就消除了不少的延迟。
这个 Reflex Markers 也是对开发者而言,要去践行 DLSS 3 非常重要的组成部分——在此之前应该是没有这部分操作的(也是就开发者角度,相较 DLSS 2 的唯一差别)。可见 Reflex 是配套消除延迟的必行方案。
在 DLSS 3 的生态扩展方面,前文已经提到了首批很快会有 35 款游戏和应用做出支持;另外 DLSS 3 会作为 Streamline 插件存在,UE 引擎之类的就不用多说了。
我觉得有一个点可能会吸引到玩家,就是英伟达在 DLSS 3 技术解析 session 上说,长久以来竞技类游戏玩家都选择 1080p 分辨率,这是为了确保高帧率。但这次英伟达很推荐这部分玩家开始用 1440p,因为“我们发现 1440p 27 寸显示器上,相比于 1080p 25 寸显示器,玩家能够提高对准精度、打击更小的目标”,高分辨率也有助于更快锁定目标。而新架构是实现这些的基础。
摩尔定律终结后…
原本还想聊聊 Ada Lovelace 的“第 8 代”NVENC 的,但文章篇幅有些过长了,且等往后吧。有关编码器可总结的部分是这次的 NVENC 新增了对于 AV1 编码的支持,貌似英伟达在 AV1 生态方面也做了不少工作。
另外就是采用双编码器(dual encoders)配置——英伟达也为此开发了双编码器协作算法,可以把帧拆成两半,实现编码负载均衡——这就让 GeForce RTX 40 系显卡用达芬奇之类的工具做视频剪辑的时候,4K 编码速度快 1 倍、8K 输出速度快 2.5 倍等…以及和 Black Magic 合作,实现达芬奇 12K RAW 剪辑可以不用代理……
最后做个总结吧。从 Ada Lovelace 来看,英伟达作为一家 GPU 企业,对抗摩尔定律停滞的方法至少包含以下几项:
(1)DSA 和更专用的硬件单元。从此前给 GPU 加 Tensor core、RT core 就能看出来了;而在 Ada Lovelace 上,则为 RT core 又特别加了好几个专用引擎,用以提升光追效率;还有 Tensor core 上此前就已经出现的 FP8 Transformer 引擎;
(2)大搞 AI 技术。这一点虽然跟第 1 点有那么点重复,但 Tensor core 的存在,以及 DLSS 这类技术,都已经成为原始 GPU 之外,像素世界展示的重要组成部分了;AI 生成的像素和帧,未来大概就比 GPU 渲染的像素还要多。宣传中所说的 4 倍性能提升,其中有 2 倍都是来自 DLSS;
(3)架构优化。从 Ada Lovelace 上主要体现在光追的架构和流程改良上,SER 是个中典型;
(4)从系统层面看问题。这一点算是全行业趋势,黄仁勋在答记者问时说:“未来是有关加速全栈的(The future is about accelerated full stack)。”“计算并不是个芯片问题,计算是软件和芯片的问题,是全栈的挑战。”如果你在图形之外,关注英伟达的 HPC 和 AI 版图,就知道他们经常隔年更新某个细分领域的库、框架之类的东西,同硬件下的计算性能就提升 1 倍……
其实这上面有好几项都与生态构建能力有莫大关联,尤其专用硬件、AI 技术、系统层面的软件构成,都依托于庞大的开发者生态,否则也就是个精致的摆设。比如光追架构改一下,开发生态和标准可能都跟着有动作,也没有多少芯片公司现在敢贸然做这种事吧。而生态恰好是英伟达的强项。或者大概应当说正因为是强项,才会这么去做。
其实系统层面 more than Moore、Over Moore 之类的技术宣传都还在持续,这些技术惠及 PC 和工作站 GPU 应该也快了。我们可以等等看,明后年的英伟达 GPU 还将有哪些有趣的变化。
PS:针对这次 GTC Fall 的一个大热门 RTX Remix——就是那个能用来做游戏 MOD 的工具,我另外写了文章,这是个挺有趣的技术,欢迎点阅:













 /4
/4 







yzw92 2022-10-11 06:26