导语:在过去的十年里,人工智能的大部分重点都放在了GPU的处理上,这是理所当然的,因为所有的进步都在GPU。但GPU变得如此之快,以至于输入到其中的数据已成为整体AI训练性能的主要瓶颈。因此,快速、高效的数据管道已经成为用GPU加速深度神经网络(DNN)训练的关键。
一、GPU数据匮乏
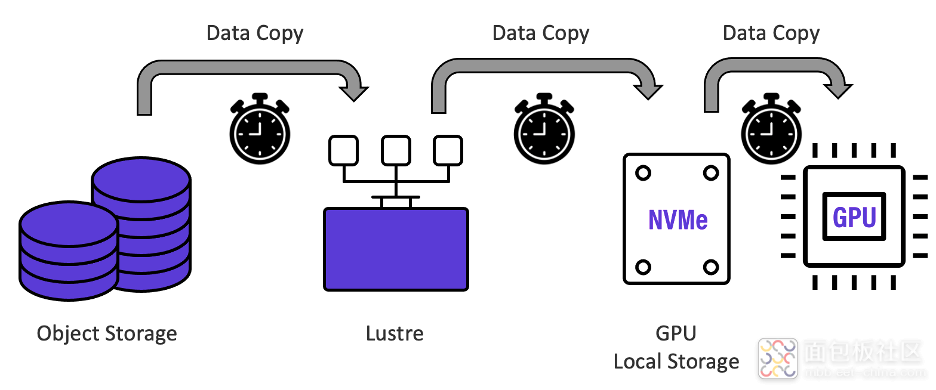
Google、Microsoft以及世界各地其他组织最近的研究表明,GPU花费了高达70%的AI训练时间来等待数据。看看他们的数据管道,这应该不足为奇。下图显示了典型的深度学习数据管道,NVIDIA称这是他们及其客户常用的。
如上图所示,在每个训练Epoch开始时,保存在大容量对象存储上的训练数据通常被移动到Lustre存储系统层,然后再次移动到GPU本地存储,用作GPU计算的暂存空间。每个“跃点”都会引入数据复制时间延迟和管理干预,从而大大减慢每个训练时期。宝贵的GPU处理资源在等待数据时一直处于空闲状态,并且不必要地延长了重要的训练时间。
二、HK-WEKA有更好的解决方法:AI数据平台
深度学习模型训练的主要设计目标,也是HK-WEKA人工智能数据平台的设计目标,即是通过在存储学习数据的HK-WEKA文件系统中以最低的延迟提供最高的吞吐量,使进行训练处理的GPU持续饱和。深度学习模型能够学习的数据越多,它就能越快地收敛于一个解决方案,其准确性也就越高。
HK-WEKA将典型的GPU匮乏的“multi-hop”AI数据管道折叠成一个单一的、零拷贝的高性能AI数据平台—其中大容量对象存储与高速HK-WEKA存储“融合”在一起,共享同一命名空间,并由GPU通过NVIDIA GPUDirect Storage协议直接访问,消除了所有瓶颈,如下图所示。将用于人工智能的HK-WEKA数据平台纳入深度学习数据管道,可使数据传输率达到饱和,并消除存储仓之间浪费的数据复制和传输时间,使每天可分析的训练数据集数量呈几何级数增加。
通过HK-WEKA零拷贝架构,数据只需写入一次,就可以被深度学习数据流中的所有资源透明地访问。如上图所示,HK-WEKA人工智能数据平台支持英伟达的GPUDirect存储协议,该协议绕过了GPU服务器的CPU和内存,使GPU能够直接与HK-WEKA存储进行通信,将吞吐量加速到尽可能快的性能。
1.专为最低延迟深度学习数据管道设计的架构
深度学习人工智能工作流程包括跨训练数据集的密集随机读取,低延迟可以加速训练和推理性能。
*HK-WEKA的设计是为了尽可能实现最低的延迟和最高的性能。
*HK-WEKA的小型4K块大小与NVMe SSD介质块大小相匹配,以实现最佳性能和效率。
*HK-WEKA将元数据处理和直接数据访问均匀地分布在所有存储服务器上(没有后端网络),进一步降低了延迟,提高了性能。
*更重要的是,HK-WEKA设计了低延迟的性能优化的网络。
*HK-WEKA不使用标准的TCP/IP服务,而是使用UDP上的数据平面开发工具包(DPDK)来加速数据包处理工作负载,没有任何上下文切换和零拷贝访问,这是一个特制的基础设施。
*HK-WEKA绕过了标准的网络内核栈,消除了网络操作对内核资源的消耗。
2.无缝低延迟命名空间扩展到对象存储
HK-WEKA数据平台的集成对象存储提供经济、大容量和快速访问,以便在深度学习训练过程中存储和保护大量训练集。
*用于AI的HK-WEKA数据平台包括无缝扩展其命名空间到对象存储和从对象存储扩展的能力.
*所有数据都位于一个HK-WEKA命名空间中,所有元数据都位于闪存层上,以便快速、轻松地访问和管理。
*为了减少延迟,大文件被分割成小对象,小文件被打包成更大的对象,以最大限度地提高并行性能访问和空间效率。
3.通过切换到HK-WEKA的AI数据平台,Epoch Time可减少20倍
为了说明如何显著减少训练周期时间,计算机视觉深度神经网络最大、知识最渊博的用户之一最近从传统的多副本数据管道转换到HK-WEKA的零拷贝数据管道,在传统的多副本数据管道中,每个训练周期需要80小时。而现在,他们将Epoch Time缩短了20倍至4小时,如下图所示。这使他们能够在12天内完成旧基础设施需要一年才能完成的工作,从而大大加快了最终产品的上市速度。

关于虹科云科技
虹科云科技,主要分享云计算、数据库、商业智能、数据可视化、高性能计算等相关知识、产品信息、应用案例及行业信息,为学习者传输前沿知识、为技术工程师解答专业问题、为企业找到最适合的云解决方案!







 /2
/2 





文章评论(0条评论)
登录后参与讨论